
8.7万条豆瓣电影数据分析

这篇文章主要分两部分来聊,第一部分讲数据的抓取,第二部分对电影数据进行一些简单的分析。好,我们这就进入正题...
第一章:获取豆瓣电影信息
1.构造链接


这里我通过一个theme_page的类,获取所有主题下的全部链接地址:
# coding=utf-8
# usr/bin/eny python
import urllib.request
import requests
from lxml import etree
import time
'''
获取每个主题下有多少页内容 (没有输入,输出字典)
'''
class theme_page(object):
def __init__(self):
self.tags = [u"爱情", u"喜剧", u"动画", u'剧情', u'科幻', u'动作', u'经典', u'悬疑', u'青春', u'犯罪', u'惊悚', \
u"文艺", u"搞笑", u"纪录片", u'励志', u'恐怖', u'战争', u'短片', u'黑色幽默', u'魔幻', u'传记', \
u'情色', u"感人", u"暴力", u'动画短片', u'家庭', u'音乐', u'童年', u'浪漫', u'黑帮', u'女性', \
u'同志', u"史诗", u"童话", u'烂片', u'cult']
def get_total_num(self):
tags = self.tags
total_num = []
list = []
for tag in tags:
# print(tag) #主题名称
re_url = 'https://movie.douban.com/tag/{}?start=0&type=T'.format(urllib.request.quote(tag))
# print(re_url) # 主题链接
s = requests.get(re_url)
contents = s.content.decode('utf-8')
selector = etree.HTML(contents)
num = selector.xpath('//*[@id="content"]/div/div[1]/div[3]/a[10]/text()')
total_num.append(int(num[0]))
# print(num[0]) # 总页数
list.append({ # list :{'爱情': '393'}, {'喜剧': '392'}, {'动画': '274'},
'主题' : tag ,
'总页数' : num[0]
})
return list2.信息抽取
这块的工作也比较常规,由于豆瓣电影信息的页面不是动态加载,给抓取数据的工作减小了很大难度,使用lxml工具先抓到列表页中的电影简介信息和链接,然后进入到每部电影的链接里抓取详情信息。
抓取列表页信息:
tag = urllib.request.quote(u'爱情')
url_1 = 'https://movie.douban.com/tag/{}?start=0&type=T'.format(tag)
class douban(object):
def __init__(self,*args,**kwargs):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='', db='douban', charset='utf8')
self.cursor = self.conn.cursor()
self.sql_info = "INSERT IGNORE INTO `douban_mov` VALUES(%s,%s,%s,%s,%s,%s)"
def search(self,content):
'''
爬取页面内电影信息
'''
try:
selector = etree.HTML(content)
textslist = selector.xpath('//div[contains(@class,"grid-16-8 clearfix")]/div[1]/div[2]/table')
except Exception as e:
print(e)
try:
for text in textslist:
lists = []
title = text.xpath('tr/td[2]/div/a/text()')
score = text.xpath('tr/td[2]/div/div/span[2]/text()')
num = text.xpath('tr/td[2]/div/div/span[3]/text()')
link = text.xpath('tr/td/a/@href')
content = text.xpath('tr/td[2]/div/p/text()')
if title:
title = title[0].strip().replace('\n', "").replace(' ', "").replace('/', "") if title else ''
score = score[0] if score else ''
num = num[0].replace('(', "").replace(')', "") if num else ''
link = link[0] if link else ''
time = content[0].split(' / ')[0] if content else ''
actors = content[0].split(' / ')[1:6] if content else ''
lists.append({
'电影名' : title,
'评分' : score,
'评价人数' : num,
'详情链接' : link,
'上映时间' : time,
'主演' : actors
})
if lists:
lists = lists.pop()
else:
lists = u' '
print(lists)
try:
self.cursor.execute(self.sql_info,(str(lists['电影名']),str(lists['评分']),str(lists['评价人数']),str(lists['详情链接']),
str(lists['上映时间']),str(lists['主演'])))
self.conn.commit()
except Exception as e:
print(e)
except Exception as e:
pass
从列表页中找到每部电影链接,进去抓详情:
def get_detail(self,url):
'''
抓取每页详细信息
'''
try:
detail_contents = requests.get(url)
detail_contents =detail_contents.content.decode('utf-8')
selector = etree.HTML(detail_contents)
except Exception as e:
print(e)
detail = []
try:
detail_director = selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') # 导演
detail_time = selector.xpath('//span[contains(@property,"v:runtime")]/text()') # 片长
detail_type_1 = selector.xpath('//*[@id="info"]/span[5]/text()') # 类型
detail_type_2 = selector.xpath('//*[@id="info"]/span[6]/text()')
detail_type_3 = selector.xpath('//*[@id="info"]/span[7]/text()')
except Exception as e:
print(e)
if detail_director:
detail_director = detail_director[0] if detail_director else ''
detail_time = detail_time[0] if detail_time else ''
detail_type_1 = detail_type_1[0] if detail_type_1 else ''
detail_type_2 = detail_type_2[0] if detail_type_2 else ''
detail_type_3 = detail_type_3[0] if detail_type_3 else ''
type = detail_type_1 + u' ' + detail_type_2 + u' ' + detail_type_3
detail.append({
'导演' : detail_director,
'片长' : detail_time,
'类型' : type,
})
else:
pass
return detail
3.让程序run起来
for page_info in page_infos: # 遍历所有主题
tags = page_info['主题']
page = page_info['总页数']
tag = urllib.request.quote(tags)
threads = []
for i in range(int(page)): # 每个主题下的所有页数
if i == 0:
url = 'https://movie.douban.com/tag/{0}?start={1}&type=T'.format(tag, 0)
else:
url = 'https://movie.douban.com/tag/{0}?start={1}&type=T'.format(tag, i * 20)
s = requests.get(url)
s = s.content.decode('utf-8')
# pool.apply_async(run.search(s))
# pool.close()
# pool.join()
lists = run.search(s)
time.sleep(5)
每天晚上睡觉前把电脑打开,单机跑了几个晚上,拉下来87000多条电影数据。好慢的说..
第二章:豆瓣电影的简要分析
前人们对豆瓣的分析已经很多了,这里的画风简单带过,主要是最后有一个最受欢迎与最受吐槽的电影榜单,大家可以乐呵一下...
1.电影类型分布
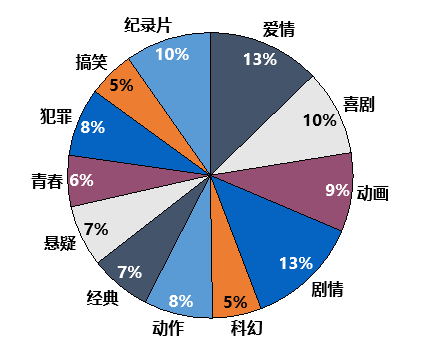

2.人们参与评分情况
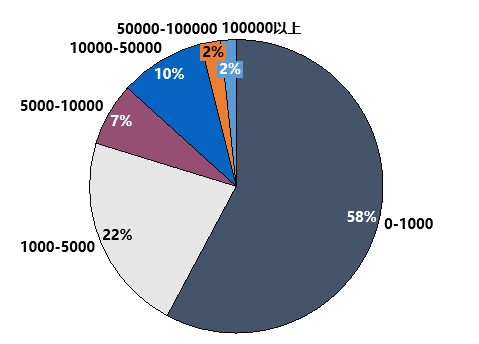

3.“重点”电影打分情况分析


4.榜单
说了那么多,我们关心的究竟是哪几部电影那么有特色啊
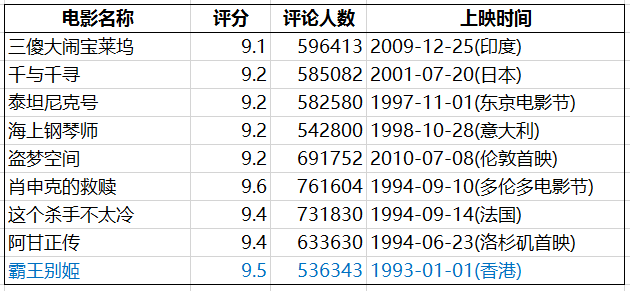
最受欢迎榜单 (评分>9,评论人数>50万)

最不受欢迎榜单 (评分<5,评论人数>10万)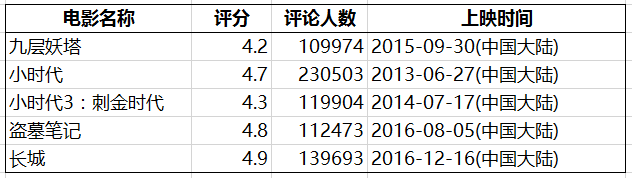

大家看看就好,我就不展开了...
大家想自己看看豆瓣电影数据的:电影数据 (密码:s11k)

