
Python爬虫实战入门四:使用Cookie模拟登录——获取电子书下载链接

在实际情况中,很多网站的内容都是需要登录之后才能看到,如此我们就需要进行模拟登录,使用登录后的状态进行爬取。这里就需要使用到Cookie。
现在大多数的网站都是使用Cookie跟踪用户的登录状态,一旦网站验证了登录信息,就会将登录信息保存在浏览器的cookie中。网站会把这个cookie作为验证的凭据,在浏览网站的页面是返回给服务器。
因为cookie是保存在本地的,自然cookie就可以进行篡改和伪造,暂且不表,我们先来看看Cookie长什么样子。
打开网页调试工具,随便打开一个网页,在“network”选项卡,打开一个链接,在headers里面:
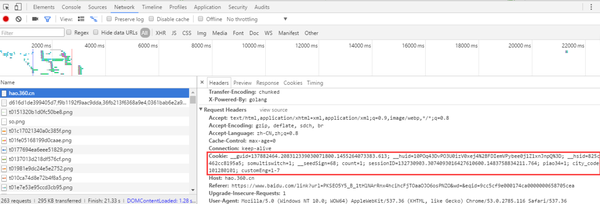

我们复制出来看看:
__guid=137882464.208312339030071800.1455264073383.613;
__huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D;
__hsid=825c7462cc8195a5;
somultiswitch=1;
__seedSign=68;
count=1; sessionID=132730903.3074093016427610600.1483758834211.764;
piao34=1;
city_code=101280101;
customEng=1-7由一个个键值对组成。
接下来,我们以看看豆(http://kankandou.com)的一本书籍的详情页为例,讲解一下Cookie的使用。
看看豆是一个电子书下载网站,自己Kindle上的书多是从这上面找寻到的。
示例网址为:宇宙是猫咪酣睡的梦-看看豆-提供优质正版电子书导购服务
正常情况下,未登录用户是看不到下载链接的,比如这样:
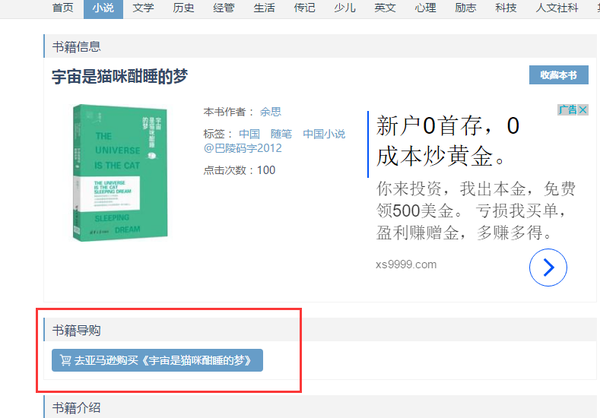

隐藏了书籍的下载链接。
其头信息如下:
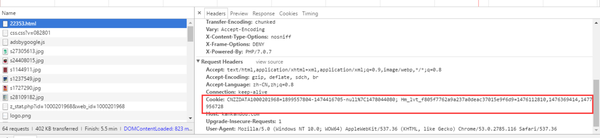

我们再看看登录之后的页面:
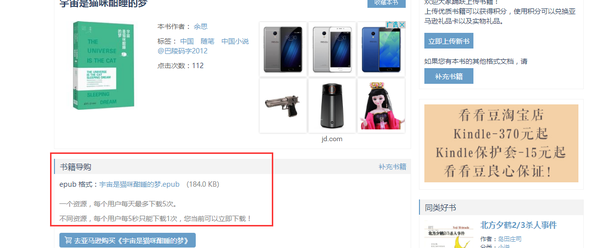

下载链接已经显示出来了,我们看看头信息的Cookie部分
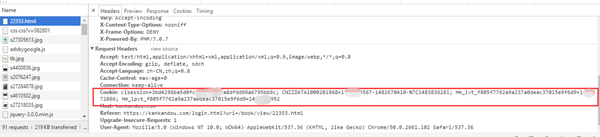

很明显地与之前未登录状态下的Cookie有区别。
接下来,我们按照上一章爬取腾讯新闻的方法,对示例网址(https://kankandou.com/book/view/22353.html)进行HTTP请求:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)结果如下:
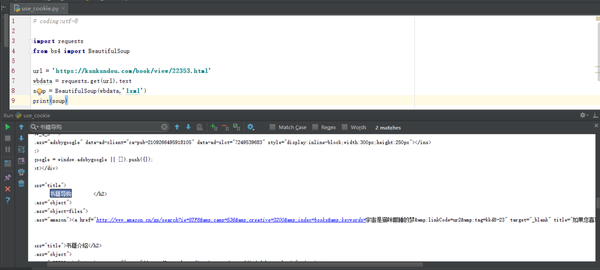

我们从中找到下载链接存在的栏目“书籍导购”的HTML代码:
<h2 class="title">书籍导购</h2>
<div class="object">
<div class="object-files">
<div class="amazon"><a href="http://www.amazon.cn/gp/search?ie=UTF8&camp=536&creative=3200&index=books&keywords=宇宙是猫咪酣睡的梦&linkCode=ur2&tag=kkd8-23" target="_blank" title="如果您喜欢《宇宙是猫咪酣睡的梦》这本书,请去亚马逊购买。">去亚马逊购买《宇宙是猫咪酣睡的梦》</a></div>
</div>
</div>如同我们在未登录状态使用浏览器访问这个网址一样,只显示了亚马逊的购买链接,而没有电子格式的下载链接。
我们尝试使用以下登录之后的Cookie:
使用Cookie有两种方式,
1、直接将Cookie写在header头部
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)上述代码返回了对页面(https://kankandou.com/book/view/22353.html)的响应,
我们搜索响应的代码,
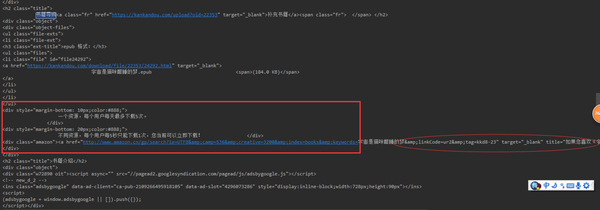

红色椭圆的部分与未带Cookie访问是返回的HTML一致,为亚马逊的购买链接,
红色矩形部分则为电子书的下载链接,这是在请求中使用的Cookie才出现的
对比实际网页中的模样,与用网页登录查看的显示页面是一致的。
功能完成。接下来看看第二种方式
2、使用requests插入Cookie
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)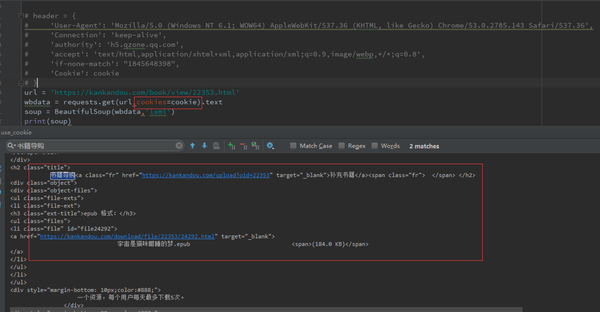

如此获取到的也是登录后显示的HTML:
这样,我们就轻松的使用Cookie获取到了需要登录验证后才能浏览到的网页和资源了。
这里只是简单介绍了对Cookie的使用,关于Cookie如何获取,手动复制是一种办法,通过代码获取,需要使用到Selenium,接下来的章节会讲解,这里暂且不表。
=======================================================================
微信公众号:州的先生 首发
个人网站:http://zmister.com 同步更新

