
数据挖掘过程中的离散方法


我们在跑模型的过程中都离不开特征离散的环节,特别是一些连续值范围绝大的特征,不做离散化处理很容易过拟合,在数据特征处理过程中离散可以很好的解决这些问题,包括常知道的分箱处理等频等距。
从数据集的特征按照其取值可以分为连续特征和离散特征。连续特征也称为定量特征,例如人的身高160~190cm,年龄18~60周岁等等。 离散特征也称定性特征,如性别(男/女)、学历(大专/本/硕/博), 城市(北上广) 等, 此类特征的值域只限定于较少的取值。连续特征的取值允许被排序,可进行算术运算;离散特征的取值有时允许被排序, 但是其不能进行算术运算。
在我们平时做分类预测问题过程中存在着大量的连续特征,基本的年龄、收入、购买频次/登陆次数/消费金额等等。
将连续特征离散化,再将离散化的结果应
用于算法有很多好处。
- 离散化结果将会减少给定连续特征值的个数,减小系统对存储空间的实际需求。
- 离散特征相对于连续特征来说更接近于知识层面的表示。
- 通过离散化,数据被规约和简化,对于使用者和专家来说,离散化的数据都更易于理解,使用和解释。
- 离散化处理使得算法的学习更为准确和迅速。
- 一系列算法只能应用于离散型数据,
使得离散化处理成为必要,而离散化又使很多算法的应用范围扩展了。
但最优离散化问题已经被证明是一个NP-hard问题。 离散化的方法有很多,在这里重点介绍离散化过程和不同的方法论。
离散化处理的一般过程
对连续特征进行离散化处理,一般经过以下步骤:
- 对此特征进行排序。特别是对于大数据集,排序算法的选择要有助于节省时间,提高效率,减少离散化的整个过程的时间开支及复杂度。
- 选择某个点作为候选断点,用所选取的具体的离散化方法的尺度进行衡量此候选断点是否满足要求。
- 若候选断点满足离散化的衡量尺度,
则对数据集进行分裂或合并,再选择下一个候选断点,重复步骤(2)(3)。
- 当离散算法存在停止准则时,如果满足停止准则,则不再进行离散化过程,从而得到最终的离散结果。
关于离散结果的好坏,还是要看模型的效果。
离散化方法
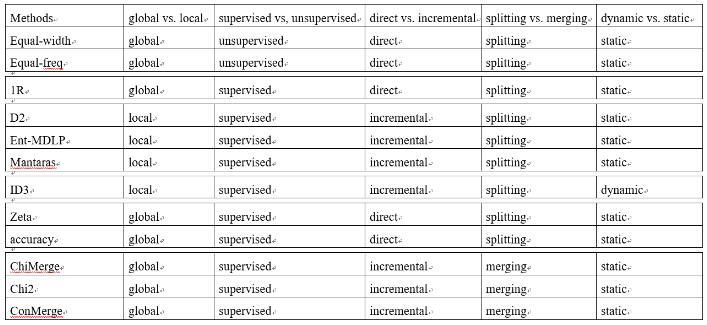
一般的离散方法有
分箱binning
- Equal width or frequency
- 1R
熵entropy
- ID3 type
- D2
- Ent-MDLP
- Mantaras distance
独立性dependency
- Zeta
精确度accuracy
- adaptive quantizer
归纳参考下图

参考文献
[1] Mehmed Kantardzic , 2003. Data Mining: Concepts, Models, Methods, and Algorithms, IEEE press, pp:19-22,54-58
[2] 张永,丁洪昌,2007。连续特征离散化的 MaxDiff 方法。计算机工程与应用,2007,43 (19)
[3] Ying Yang and Xindong Wu,2007 。 Discretization Methods Simon, H.A. 1981. The Sciences of the Artificial, 2nd edn. Cambridge, MA: MIT Press.
[4] 刘业政,焦宁等,2007。连续特征离散化算法 比较研究。计算机应用研究,2007 年 9 月第 24 卷第 9 期。
[5] Dougherty, J.,Kohavi, R., and Sahami, M. 1995. Supervised and unsupervised discretization of continuous features. In Proc. Twelfth International Conference on Machine Learning. Los Altos, CA: Morgan Kaufmann, pp. 194–202
