
【机器学习】Cross-Validation(交叉验证)详解


本文章部分内容基于之前的一篇专栏文章:统计学习引论
在机器学习里,通常来说我们不能将全部用于数据训练模型,否则我们将没有数据集对该模型进行验证,从而评估我们的模型的预测效果。为了解决这一问题,有如下常用的方法:
1.The Validation Set Approach
第一种是最简单的,也是很容易就想到的。我们可以把整个数据集分成两部分,一部分用于训练,一部分用于验证,这也就是我们经常提到的训练集(training set)和测试集(test set)。
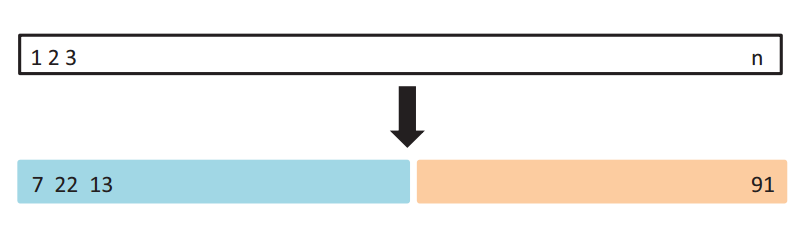

例如,如上图所示,我们可以将蓝色部分的数据作为训练集(包含7、22、13等数据),将右侧的数据作为测试集(包含91等),这样通过在蓝色的训练集上训练模型,在测试集上观察不同模型不同参数对应的MSE的大小,就可以合适选择模型和参数了。
不过,这个简单的方法存在两个弊端。
1.最终模型与参数的选取将极大程度依赖于你对训练集和测试集的划分方法。什么意思呢?我们再看一张图:
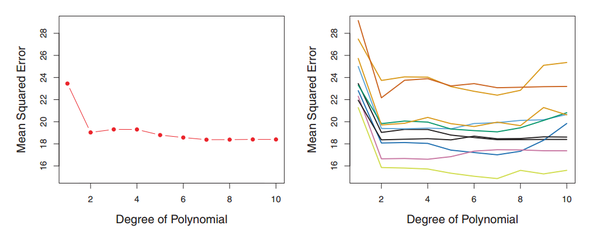

2.该方法只用了部分数据进行模型的训练
我们都知道,当用于模型训练的数据量越大时,训练出来的模型通常效果会越好。所以训练集和测试集的划分意味着我们无法充分利用我们手头已有的数据,所以得到的模型效果也会受到一定的影响。
基于这样的背景,有人就提出了Cross-Validation方法,也就是交叉验证。
2.Cross-Validation
2.1 LOOCV
首先,我们先介绍LOOCV方法,即(Leave-one-out cross-validation)。像Test set approach一样,LOOCV方法也包含将数据集分为训练集和测试集这一步骤。但是不同的是,我们现在只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)。
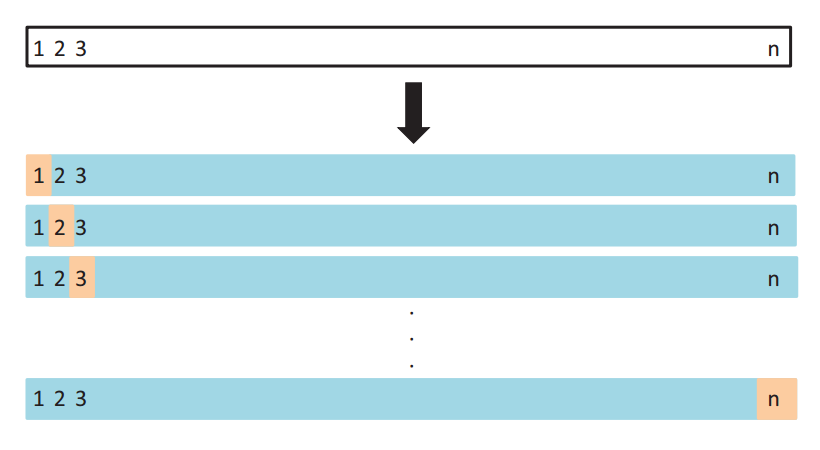
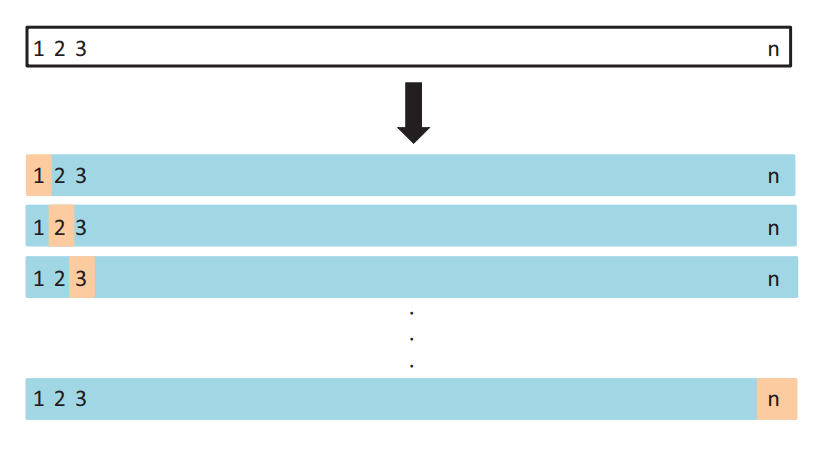
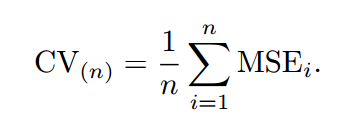
为了解决计算成本太大的弊端,又有人提供了下面的式子,使得LOOCV计算成本和只训练一个模型一样快。
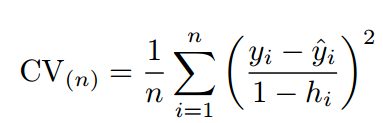
2.2 K-fold Cross Validation
另外一种折中的办法叫做K折交叉验证,和LOOCV的不同在于,我们每次的测试集将不再只包含一个数据,而是多个,具体数目将根据K的选取决定。比如,如果K=5,那么我们利用五折交叉验证的步骤就是:
1.将所有数据集分成5份
2.不重复地每次取其中一份做测试集,用其他四份做训练集训练模型,之后计算该模型在测试集上的MSE_i
3.将5次的MSE_i取平均得到最后的MSE
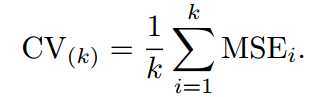
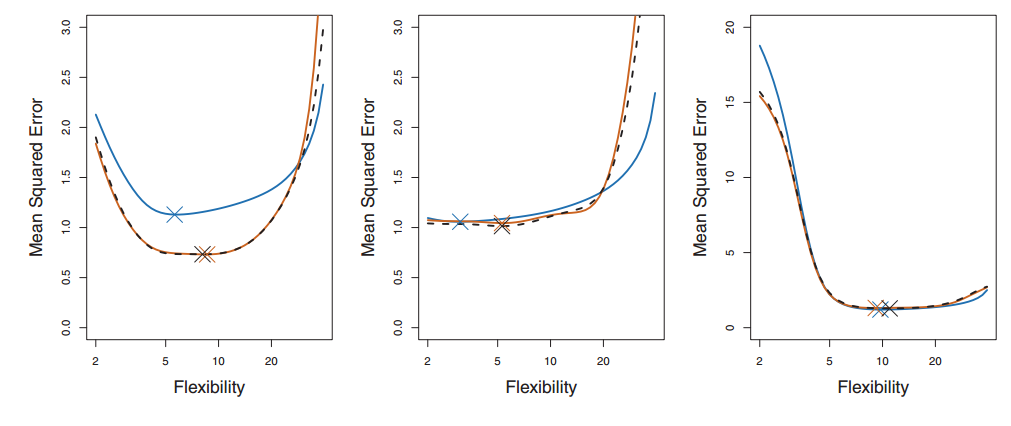
2.3 Bias-Variance Trade-Off for k-Fold Cross-Validation
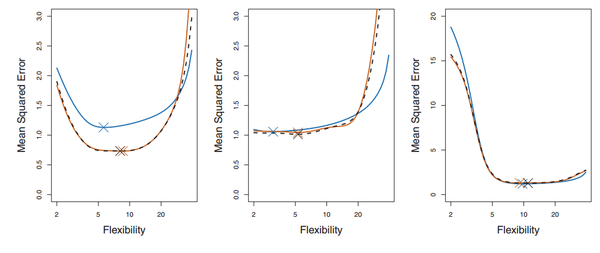
最后,我们要说说K的选取。事实上,和开头给出的文章里的部分内容一样,K的选取是一个Bias和Variance的trade-off。
K越大,每次投入的训练集的数据越多,模型的Bias越小。但是K越大,又意味着每一次选取的训练集之前的相关性越大(考虑最极端的例子,当k=N,也就是在LOOCV里,每次都训练数据几乎是一样的)。而这种大相关性会导致最终的test error具有更大的Variance。
一般来说,根据经验我们一般选择k=5或10。
2.4 Cross-Validation on Classification Problems
上面我们讲的都是回归问题,所以用MSE来衡量test error。如果是分类问题,那么我们可以用以下式子来衡量Cross-Validation的test error:
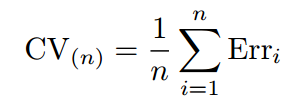
图片来源:《An Introduction to Statistical Learning with Applications in R》
说在后面
关于机器学习的内容还未结束,请持续关注该专栏的后续文章。
更多内容请关注我的专栏:R Language and Data Mining
或者关注我的知乎账号:温如


