
Python · 数据工具包

射命丸咲
一个啥都想学的浮莲子
(这里是本章用到的 GitHub 地址)
(依稀有印象以前在某个地方说过怎么生成数据集……嘛不要在意细节【喂】)
说是数据工具包、其实实现的东西都相当朴素;虽说今后可能会因为一些新需求而拓展它、不过目前为止它只有如下三个功能:
- 生成异或数据集
- 生成螺旋线数据集
- 数值化数据
如果没有关系的话、就请往下看吧 ( σ'ω')σ
首先是最简单的生成异或数据集的实现,大概直接贴代码也没什么问题:
# 参数 size 即是每个象限中样本点个数
# 参数 scale 则描述了整个数据集的分散程度
def gen_xor(size=100, scale=1):
x = np.random.randn(size) * scale
y = np.random.randn(size) * scale
z = np.zeros((size, 2))
z[x * y >= 0, :] = [0, 1]
z[x * y < 0, :] = [1, 0]
return np.c_[x, y].astype(np.float32), z
然后是生成螺旋线数据集的实现,用到了螺旋线在极坐标的中的表达式。具体而言: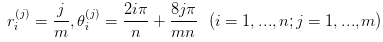
这里的 n 代表螺旋线的条数,m 代表每条螺旋线上的样本点个数
from math import pi
# 参数 size 即为上式中的 m,参数 n 即为上式中的 n,参数 n_class 代表类别个数
def gen_spin(size=50, n=7, n_class=7):
xs = np.zeros((size * n, 2), dtype=np.float32)
ys = np.zeros(size * n, dtype=np.int8)
for i in range(n):
ix = range(size * i, size * (i + 1))
r = np.linspace(0.0, 1, size+1)[1:]
t = np.linspace(2 * i * pi / n, 2 * (i + 4) * pi / n, size)
xs[ix] = np.c_[r * np.sin(t), r * np.cos(t)]
ys[ix] = i % n_class
z = []
for yy in ys:
tmp = [0 if i != yy else 1 for i in range(n_class)]
z.append(tmp)
return xs, np.array(z)
这样生成出来的螺旋线可能太过整齐:
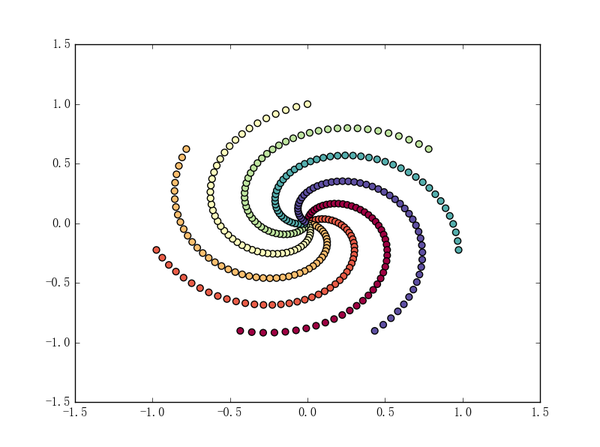

如果觉着瘆得慌的话可以在 t 那里加一个随机项以让数据“乱一点”:
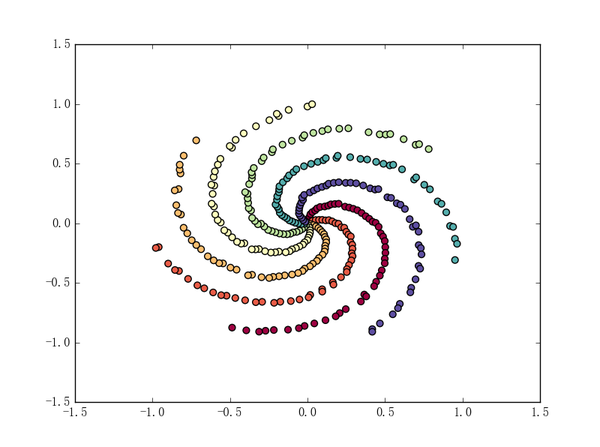

# wc 是 whether_continuous 的缩写
# continuous_rate 是判定特征是否连续的阈值
def quantize_data(x, y, wc=None, continuous_rate=0.1, separate=False):
# 先将 x 转置
if isinstance(x, list):
xt = map(list, zip(*x))
else:
xt = x.T
# 用 set 获取各维度特征所有可能的取值
features = [set(feat) for feat in xt]
# 如果没提供 wc、就用阈值判断各维度特征是否连续
if wc is None:
wc = np.array([len(feat) >= continuous_rate * len(y)
for feat in features])
else:
wc = np.array(wc)
# 获取数值化数据时的转换字典
feat_dics = [{_l: i for i, _l in enumerate(feats)} if not wc[i] else None
for i, feats in enumerate(features)]
# 如果参数 separate 是 True、就将离散数据和连续数据分开
# 若为 False,则如果全是离散型特征、就令数据类型为 int,否则令为 double
if not separate:
if np.all(~wc):
dtype = np.int
else:
dtype = np.double
x = np.array([[feat_dics[i][_l] if not wc[i] else _l
for i, _l in enumerate(sample)] for sample in x], dtype=dtype)
else:
dtype = np.double
x = np.array([[feat_dics[i][_l] if not wc[i] else _l
for i, _l in enumerate(sample)] for sample in x], dtype=dtype)
x = (x[:, ~wc].astype(np.int), x[:, wc])
# 数值化类别并获取数值化类别时的转换字典
label_dic = {_l: i for i, _l in enumerate(set(y))}
y = np.array([label_dic[yy] for yy in y], dtype=np.int8)
label_dic = {i: _l for i, _l in enumerate(set(y))}
# 返回所有可能还会用到的东西
return x, y, wc, features, feat_dics, label_dic
这个数值化数据的方法会在朴素贝叶斯模型的实现中用到,它本身也是一个简易的数据预处理、可以应用的场合算是比较广泛
以上、我们就讲完了“数据工具包”中的所有功能及相应实现,虽说比较简陋、但个人感觉在初等的场合用起来还是颇为方便 ( σ'ω')σ
希望各位观众老爷们能够喜欢~
编辑于 2017-03-24 22:11
