
含噪数据的有效训练,谷歌地标图像检索竞赛2020冠军方案解读



2020年谷歌地标图像检索竞赛(Google Landmark Retrieval 2020)是今年举行的大型图像检索算法竞赛,该比赛在Kaggle 竞赛平台进行,吸引了全球541支团队参赛,最终来自韩国三星电子的一位软件工程师 SeungKee Jeon获得冠军。
下图即最终的排行榜:


近日,SeungKee Jeon 撰写论文 1st Place Solution to Google Landmark Retrieval 2020 详细描述了获胜方案。

虽然三星员工获得了冠军,但作者在引脚注明,其实他是在无薪休假一年时顺便打了这场比赛(愿意花一年时间闭关,这么洒脱的吗?)。
比赛任务
给定一幅地标图像,在数据集中查询与其相似的图像。
也就是常见的图像检索了。难度在于:数据集非常庞大且含噪声, Google Landmarks Dataset v2(GLD2)含近500万幅图像,训练集4132914幅图像,203094个类别,索引集761757幅图像,测试集117577幅图像,该数据集是由网络数据挖掘而得到的地标图像数据,所以含有非常多的噪声标注。
另外该数据集有一个被上届比赛中smlyaka团队使用自动清理工具清理过的版本CGLD2,其训练集含有 1580470 幅图像, 81313 个类别。


基本方案
作者使用的技术方案算是一套标准的度量学习流程,模型设计上可能不能带来新的启发,但对数据的理解和处理上还是值得借鉴的。
模型结构如下图:
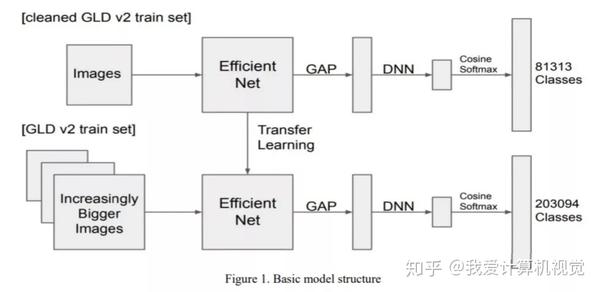

模型选择:
EfficientNet + global average pooling(GAP) 用于提取特征,后接 DNN 降维 (最终特征是512维),使用Cosine Softmax(CosFace)进行度量学习。使用 fixed adacos 确定 Cosine Softmax 的参数,Margin设置为 0 。
预训练过程:
使用ImageNet上的预训练模型,然后再使用清理后的数据集CGLD2训练模型,再使用含噪声的大数据集GLD2训练。
应对类别不平衡:
使用了 weighted crossentropy。
图像增广:
只使用了图像左右翻转,作者认为这么大体量的数据不太可能过拟合,而且左右翻转这样的操作显然不会像改变颜色、旋转等造成数据分布的改变。
验证集数据选择:对于每类大于等于4个样本的类,只选择一个样本。作者解释这样做为了使类别更丰富,最终验证集使用了72322个样本。
训练硬件:
Google Colab上的TPUv2-8。
训练策略
训练策略可以说是作者赢得比赛的关键,通过“异常简单”却卓有成效的4步,将冠军锁定。(即使是单模型也能拿到冠军!)
作者发现含噪声的GLD2参与训练是有效的,另外提高图像分辨率也能带来显著的精度增益。
通过将同一个模型在CGLD2(经数据清理的) 和 GLD2数据集(含较大标签噪声)的交替训练,并提升输入分辨率,使每一步训练快速收敛并不断改进了精度。
下图是作者使用单个 efficientnet7 每一步得到的精度:
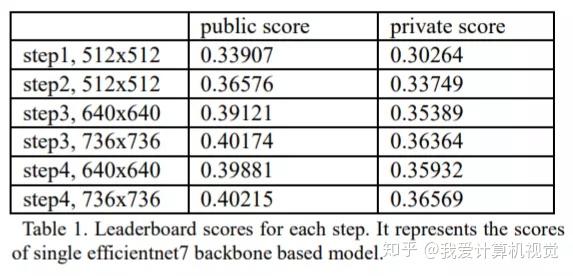

step 1, 在CGLD2上训练的模型,输入分辨率 512 x 512。
step 2,将step 1得到的模型在 GLD2 上训练,输入分辨率 512 x 512。
step 3,将step 2得到的模型在 GLD2 上训练,输入分辨率 640 x 640。
同时,将step 2得到的模型在 GLD2 上训练,输入分辨率 736 x 736。
step 4, 将step 3 中 640 x 640 分辨率数据训练得到模型在CGLD2上继续训练。
step 4, 将step 3 中 736 x 736 分辨率数据训练得到模型在CGLD2上继续训练。
可见,在两个数据集上交替训练后输入分辨率更高的模型精度最高。
模型集成
此处作者使用的模型集成方法比较简单,使用了 efficientnet7、efficientnet6、efficientnet5三种特征提取网络,将得到的特征嵌入加权后串联,权重分别为(1,0.8,0.5)。
最终经过上述 4 步训练的三个单模型集成后,在private score 排行榜得到精度0.38677,远超第二名(0.36278)。
结论
这篇竞赛技术报告给我们的一些启发:
- 数据清理是很有必要的;
- 大规模含噪数据加入训练仍能带来精度增益;
- 清洁数据-》含噪数据-》清洁数据的迭代训练,是使用噪声数据的有效手段。
- 作者没有使用近年来提出的看似更好的度量学习算法ArcFace、Circle Loss等。而在该比赛的讨论区不少人谈到方案中使用了ArcFace,所以采用哪种度量学习方法相对于有效利用数据来说其实并不是那么重要。
训练中的具体参数细节,不再赘述,感兴趣的朋友可参考原论文。
在OpenCV中文网公众号后台回复“GLR2020”,即可收到论文下载。
