Pixel CNN, Wavenet, GCNN笔记

这又是一篇翻译自我的英文博客的笔记,原址
http://ruotianluo.github.io/2017/01/11/pixelcnn-wavenet/。
这篇文章中将非常简单的讨论这三篇论文, Pixel CNN (nips那篇), Wavenet,和 Language modeling with GCNN。
这三篇的模型都运用了基于门(gate)的网络结构,而且都是autoregressive的生成模型(分别生成图片,音频和语言)。之前,这种自回归的模型经常用于language model,比如用RNN来预测下个单词。这种模型被运用到了更多模态(其实比如说图像之前也有自回归的模型,但是那好像是pre-deep的时候)。
这三篇中,Pixel CNN和Wavenet来自Deepmind,GCNN来自FAIR.
Pixel CNN
Pixel CNN是基于之前他们的Pixel RNN的文章。Pixel RNN基本上就是直接套用Language modeling的方法运用到图像上,只是因为图像是二维的,他们用了grid LSTM。(其实他们在pixelRNN那篇论文中也提到了pixelCNN,但是那篇文章中的pixelCNN有盲点的问题,所以表现不如pixelRNN好,是以baseline的形态出现的。(盲点的意思是,预测下一个像素时没有用到所有之前的像素信息))
条件pixel CNN就是他们在nips发表的新模型。这个模型在pixelRNN里面提出的那个有盲点模型上进行了改进,使得不再拥有盲点。他们提出了两个方向上的卷积网络,垂直的和水平的。垂直的网络可以看到所有需预测像素上方的像素 (在下图中微蓝色区域),而水平的网络可以看到所有该像素左边的像素(图中对应左边区域)
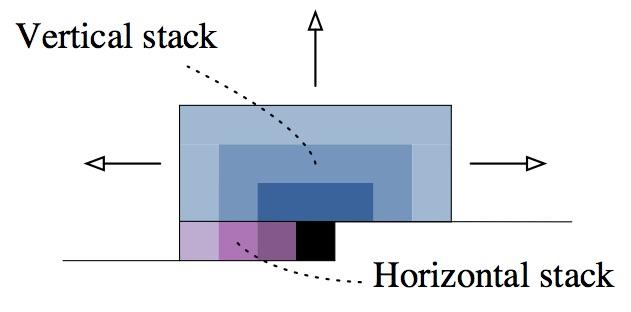

注意的是,垂直网络中的特征会被fuse到水平网络中,所以实际上水平网络也能看到上方的像素。(下图有网络的示意图,其实就是一个箭头。)。
他们在水平的网络中使用的residual,垂直的没有使用。
为了避免看到将来的像素,他们使用了带掩膜的卷积。另外他们使用了门结构。
y=tanh(Wf∗x)⊙σ(Wg∗x)
这个结构借鉴自LSTM, highway network和neural GPU。并且这个结构能提高结果。下图是gated pixel cnn的一层的结构。
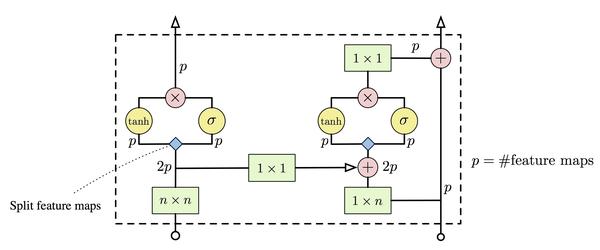

(卷积层为绿色, element-wise multiplications和加法层为红色。 W_f和W_g的卷积结果,2p长度的特征,在经过蓝色小菱形后分开成两组长度为p的特征。)
通过增加门单元的输入,可以获得条件pixelCNN(额外的输入可以是跟位置有关,也可以无关)。实验显示它们的模型在多个数据集上能够获得最好的平均负log似然。
如何比较PixelCNN与DCGAN两种Image generation方法 这里有我提的问题。唯一的回答回答的非常好,我收获颇丰,我就不放了,自己看吧。
Wavenet
Wavenet和pixelCNN基本上属于孪生兄弟,结构非常类似。但是从生成的音频质量来看要比pixel CNN生成图片成功的多。这个模型是直接用声音的原始波形来进行训练的,非常牛逼。
由于声波采样非常密集,所以为了提高receptive field,文章使用了dilated convolution,可以在保持和原本卷积层相同数量的参数情况下,几倍地增加receptive field。
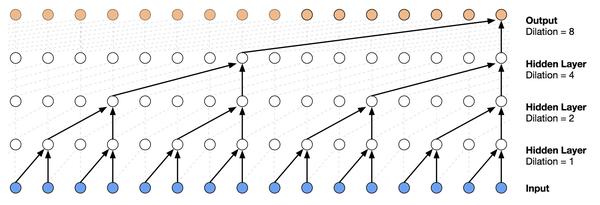
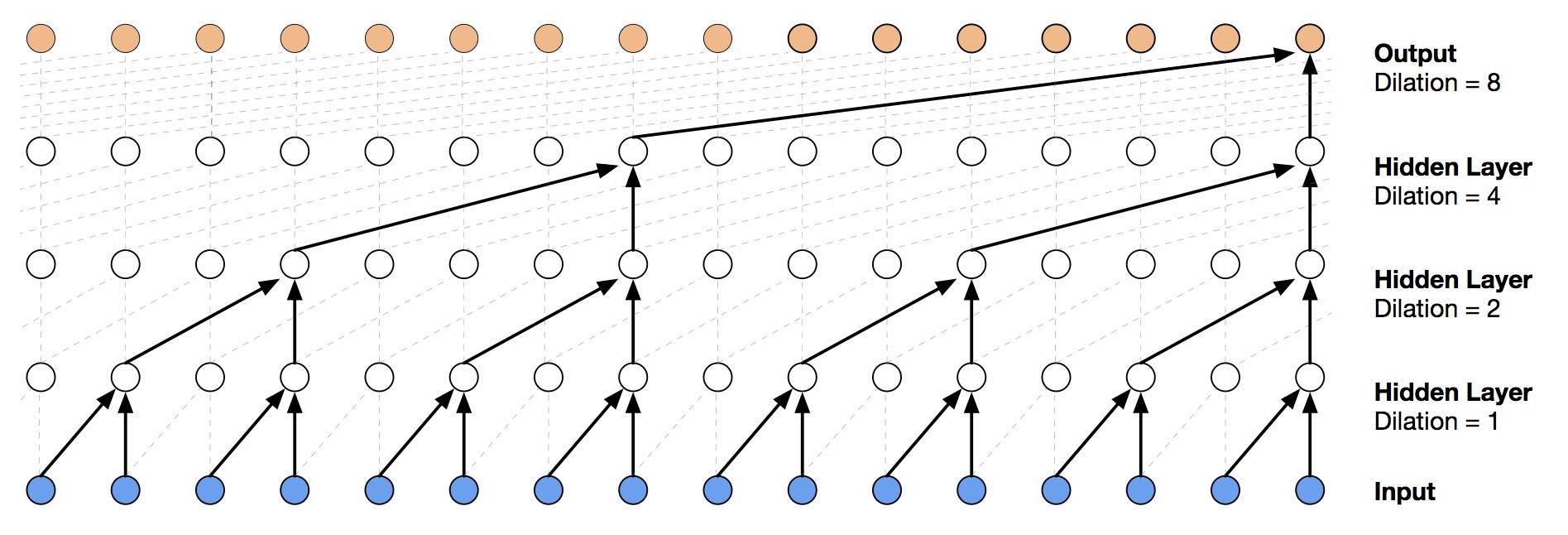
(dilated convolution就是跳着卷)
他们最后的模型,就是多个上图的结构进行多层叠加。
虽然音频的输出是连续的,但是他们这里将输出进行了量化,变成了256个离散值,转化成了分类问题。他们也用了residual,和与pixelcnn一样的门结构,另外,还用了skip connection。最终结构如下图所示。
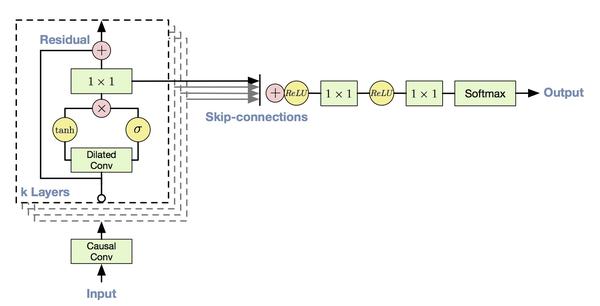

和pixelcnn类似,通过添加输入,可以将这个模型转化成条件生成模型。条件输入可以是一个表示说话者身份的one-hot的向量;或者是输入文本的linguistic features来进行TTS(text to speech).
虽然他们用dilated卷积增加了receptive field,但是receptive field最终也只有300毫秒。所以他们又另外添加了一个模块叫context stacks。这个模型在更小的分辨率上工作,所以能看到更之前的信号。
他们的结果非常酷炫,见这里.
之前的wavenet以慢著称,说生成一秒要90分钟,但是最近的一篇文章提出了一个加速方法。其实算法的想法很简单,就是移除一些重复计算(其实跟动态规划的想法很像)。(虽然算法很有用,但是这篇文章的作者数量迷之多。讲道理,这个工作量应该不需要这么多。)
与pixelcnn一样,训练也很慢。
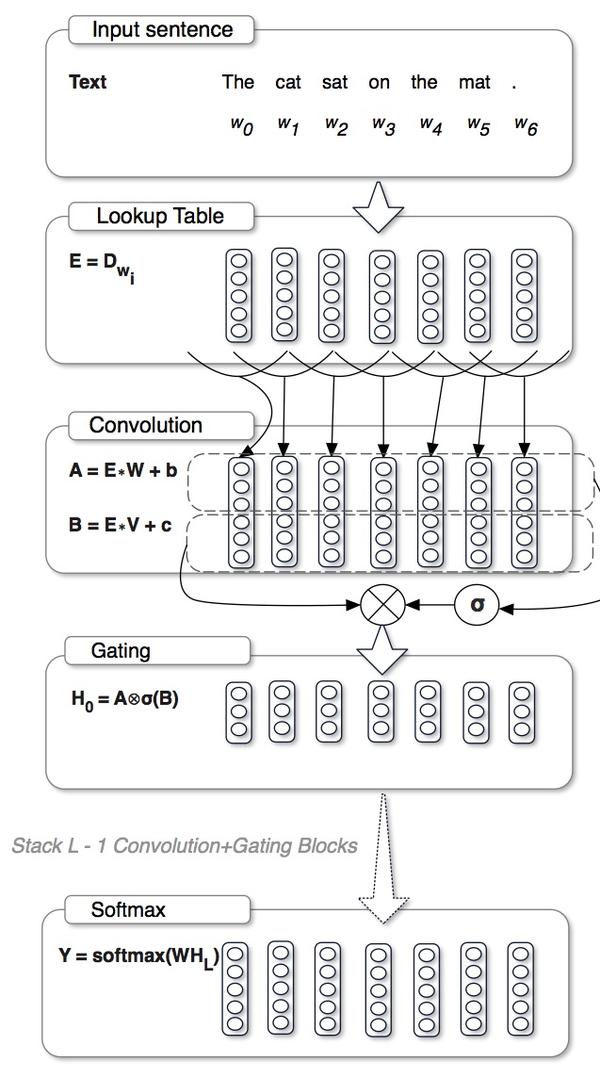
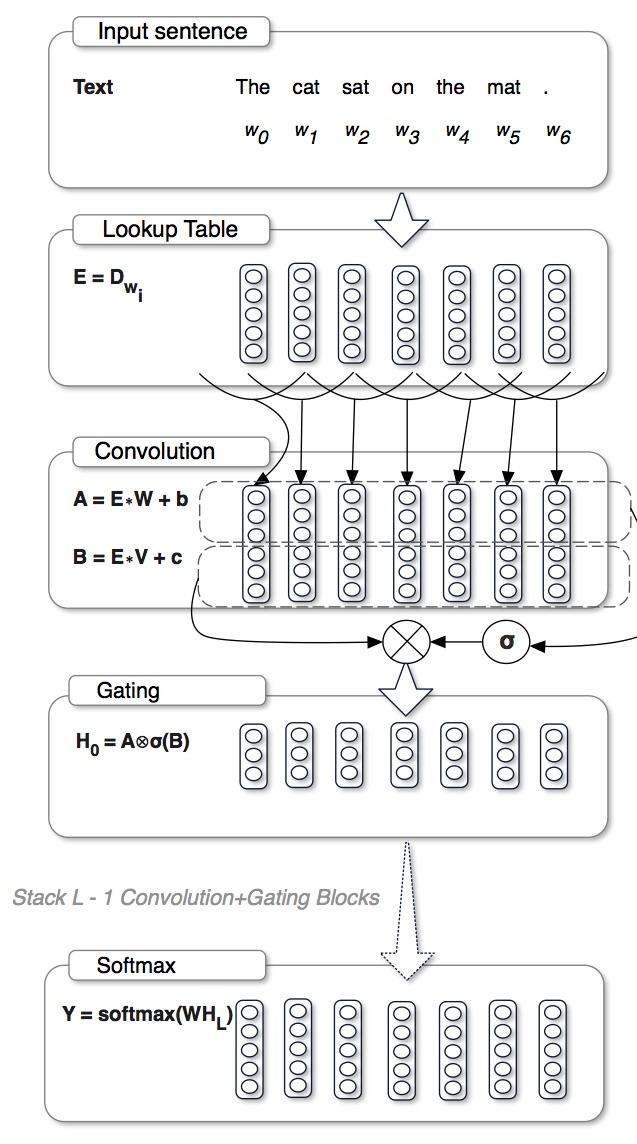
Gated CNN
GCNN和上两篇有着类似的门结构,但是有所不同。但是很有意思的是,这样的门结构最近居然如此之火,挺好奇到底是为什么的。
这里的门结构与之前不同的地方在于,没有使用tanh,而是直接将一支的特征乘以另一只经过sigmoid的特征,他们管这个叫Gated Linear Unit(对应的,有tanh的他们管叫gated tanh unit):
y=(W1∗x)⊙σ(W2∗x)
他们说这种结构不容易出现梯度消失的问题。
这篇文章的ablation study做的非常详细。
在WikiText-103, Gated Linear Unit表现最好,ReLU和GTU (Gated Tanh Unit) 表现类似,仅用tanh表现最差。
比较GLU和GTU,我们发现移除tanh效果更好。
比较GTU和Tanh,我们发现sigmoid门很重要。
比较GLU和ReLU,我们知道一个可学习的门函数很重要(你可以认为ReLU是一种特殊的GLU,其中门是固定的x>0)
他们也比较了不同的门:线性linear(无门),双线性(可以认为是将GLU的门改成线性的),GLU,GLU最好
深度:他们说如果深度小于句子长度表现就ok。(深度和长度比较有点奇怪)
背景大小: 如果背景大小超过20个单词,则对性能的提升就明显减少。这和之前在RNN中,截断20步之前的梯度并不影响结果的发现是一致的。
他们使用了weight normalization和gradient clipping(梯度clip一般不在cnn中用),对实验结果很有效。
结论:
看起来门结构在生成模型中现在很有用,虽然之前就提出了highway network,但是效果并不好。现在用门可以达到state of the art,其实还挺值得好好研究这门到底做了什么的。
