别再滥用scrapy CrawlSpider中的follow=True

对于刚接触scrapy的同学来说, crawlspider中的rule是比较难理解的, 很可能驾驭不住. 而且笔者在YouTube中看到许多公开的演讲都都错用了follow这一选项, 所以今天就来仔细谈一谈.
首先我们看scrapy中的follow是如何实现的:
# 为了方便理解, 去除了不必要代码
def _requests_to_follow(self, response):
"""遍历rules, 使用rule提取response中的链接
每个rule中提取的链接都会被添加到集合中
相同的链接只会被提取一次, 也就是范围大的rule 会覆盖范围小的rule
使用提取到的链接发送请求, 得到response
"""
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
for link in links:
seen.add(link)
r = Request(url=link.url, callback=self._response_downloaded)
yield r
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
首先, 在我们的定义中rules是一系列Rule对象的集合, 示例如下:
rules = (
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
在源代码中, 我们可以看到:
- 遍历所有的Rule对象, 并使用其link_extractor属性提取链接
- 对于提取到的链接, 我们把它加入到一个集合中
- 使用链接发送一个请求, 并且callback的最终结果是self._parse_response
上述操作表明, 当我们follow一个链接时, 我们其实是用rules把这个链接返回的response再提取一遍.

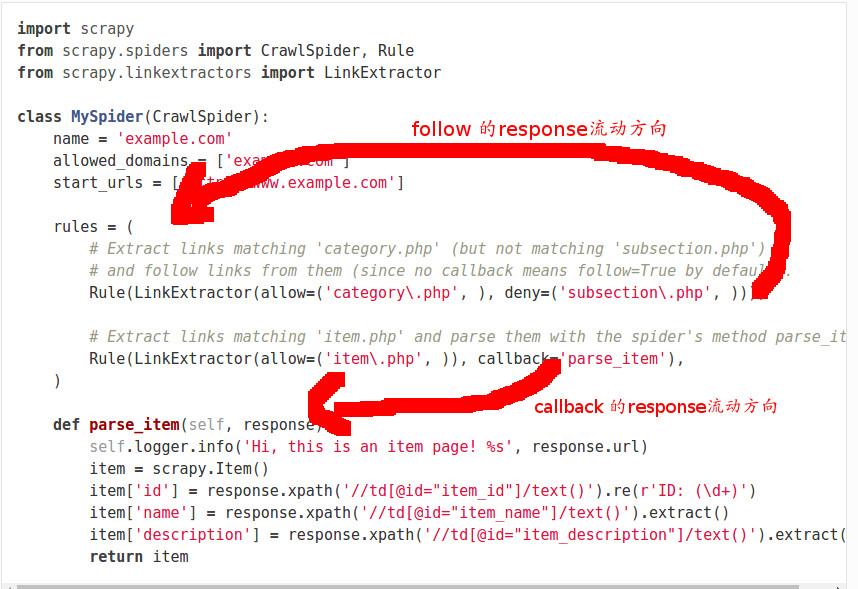
当我们需要对response进行进一步提取的时候我们才使用follow, 它会把response用rules过滤一遍, 产生新的response.
当我们的response包含有我们需要的信息是, 直接用callback提取信息.
不要滥用follow, 因为我们提取出来的链接都会被下载, 造成了不必要的请求.
其实源代码中还解释了文档中提到的关于rules顺序的问题:
Each Rule defines a certain behaviour for crawling the site. Rules objects are described below. If multiple rules match the same link, the first one will be used, according to the order they’re defined in this attribute.
多个Rule匹配同一个链接, 只有第一个Rule会被使用, 用源代码来解释就是我们匹配到了链接已经添加到set中去重了, 所以之后的匹配都无法添加. 所以我们在使用rules时, 如果两个Rule有交集, 要注意顺序.
发布于 2017-03-09 00:30