
浅析感知机(一)--模型与学习策略


最近在实验室中通过空闲时间来夯实自己一些机器学习的基础,于是打算仔细阅读李航博士的《统计学习方法》一书,而自己看书的习惯就是记录自己的学习笔记和过程,便于总结与分享给他人,一起交流学习!哈哈哈哈,开写~
感知机
感知机是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法对损失函数进行最优化。
感知机模型
假设输入空间(特征向量)是x\in R^{n} ,输出空间为Y\in \left\{ -1,+1 \right\} ,输入x\in X表示实例的特征向量,对应于输入空间的点,输出y\in Y表示实例的类别,则由输入空间到输出空间的表达形式为:
f(x)=sign(w*x+b)上面该函数称为感知机,其中w,b称为模型的参数,w\in R^{n} 称为权值,b称为偏置,w*x表示为w,x的内积
这里
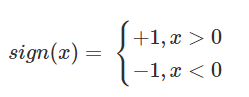
该感知机线性方程表示为:w*x+b=0,它的几何意义如下图所示:

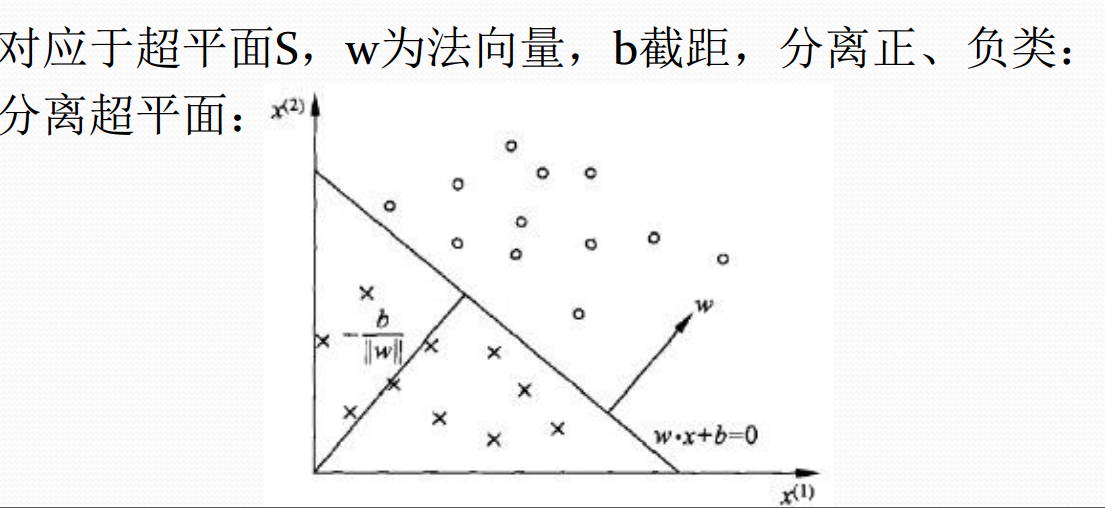
我们其实就是在学习参数w与b,确定了w与b,图上的直线(高维空间下为超平面)也就确定了,那么以后来一个数据点,我用训练好的模型进行预测判断,如果大于0就分类到+1,如果小于0就分类到-1。
由于自己在这里碰到了问题,稍微证明一下为什么w是直线(高维空间下为超平面)的法向量?

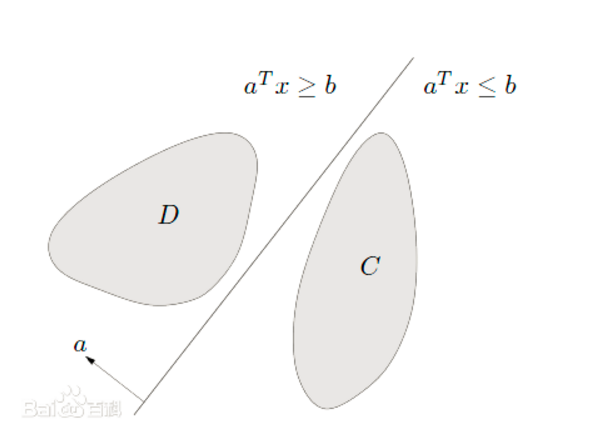
上面说到我用训练好的模型进行预测判断,如果大于0就分类到+1,如果小于0就分类到-1。用到了超平面分离定理:超平面分离定理是应用凸集到最优化理论中的重要结果,这个结果在最优化理论中有重要的位置。所谓两个凸集分离,直观地看是指两个凸集合没有交叉和重合的部分,因此可以用一张超平面将两者隔在两边。如下图所示,在大于0的时候,我将数据点分类成了D类,在小于0的时候,我将数据点分类成了C类

感知机学习策略
好了,上面我们已经知道感知机模型了,我们也知道他的任务是解决二分类问题,也知道了超平面的形式,那么下面关键是如何学习出超平面的参数w,b,这就需要用到我们的学习策略。
我们知道机器学习模型,需要首先找到损失函数,然后转化为最优化问题,用梯度下降等方法进行更新,最终学习到我们模型的参数w,b。ok,那好,我们开始来找感知机的损失函数,
我们很自然的会想到用误分类点的数目来作为损失函数,是的误分类点个数越来越少嘛,感知机本来也是做这种事的,只需要全部分对就好。但是不幸的是,这样的损失函数并不是w,b连续可导(你根本就无法用函数形式来表达出误分类点的个数),无法进行优化。
于是我们想转为另一种选择,误分类点到超平面的总距离(直观来看,总距离越小越好):
距离公式如下:
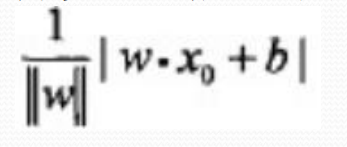
因为当我们数据点正确值为+1的时候,你误分类了,那么你判断为-1,则算出来(w*x_{0}+b )<0,所以满足-y_{i} (w*x_{0}+b )>0
当数据点是正确值为-1的时候,你误分类了,那么你判断为+1,则算出来(w*x_{0}+b )>0,所以满足-y_{i} (w*x_{0}+b )>0
则我们可以将绝对值符号去掉,得到误分类点的距离为:
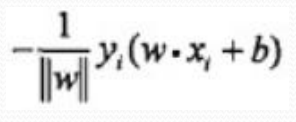
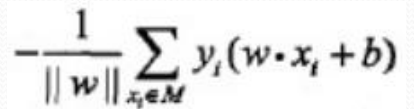
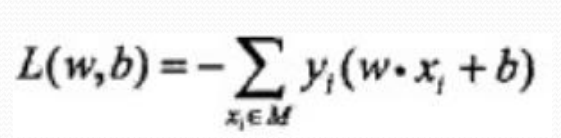

恩,好了,其实到这里为止,已经完成了标题所要表达的任务了,感知机的模型与学习策略!总结一下!
感知机的模型是f(x)=sign(w*x+b),它的任务是解决二分类问题,要得到感知机模型我们就需要学习到参数w,b。
则这个时候我们需要一个学习策略,不断的迭代更新w,b,所以我们需要找到一个损失函数。很自然的我们想到用误分类点的数目来表示损失函数,但是由于不可导,无法进行更新,改为误分类点到超平面的距离来表示,然后不考虑\frac{1}{||w||} ,得到我们最终的损失函数!
这里在学习的过程中,我有一个问题就是为什么可以不考虑\frac{1}{||w||} ,不用总距离表达式作为损失函数呢?
通过和师兄同学们的讨论,以及查阅资料,这里给出自己的理解(欢迎大家交流指错!)
感知机的任务是进行二分类工作,它最终并不关心得到的超平面离各点的距离有多少(所以我们最后才可以不考虑w的范式),只是关心我最后是否已经正确分类正确(也就是考虑误分类点的个数),比如说下面红色与绿线,对于感知机来说,效果任务是一样好的。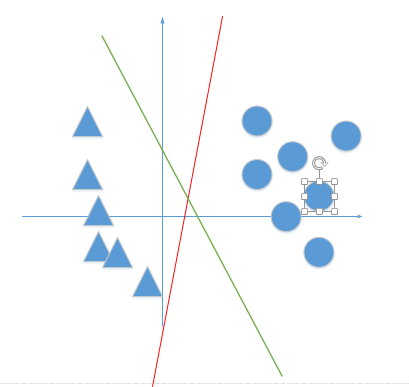
但是在SVM的评价标准中(绿线是要比红线好的,这个后面在讨论)
所以我们可以不考虑w的范式,直接去掉它,因为这个时候我们只考虑误分类点,当一个误分类点出现的时候,我们进行梯度下降,对w,b进行改变即可!跟距离没有什么关系了,因为w的范式始终是大于0,对于我们判断是否为误分类点(我们是通过是否-y_{i} (w*x_{0}+b )>0来判断是佛为误分类点)没有影响!这也回到了我们最初始想要作为损失函数的误分类点的个数,引入距离,只是将它推导出一个可导的形式!(最后说一句,我个人认为不去掉w的范式,也是一样可以得到最后的正确分类超平面,就是直接用距离来当做损失函数也是可以的,可能是求梯度比较复杂,或者是感知机本身就是用误分类点来区分,就没用了)
那么好了,我们已经得到了损失函数了,后面直接讲解如何梯度下降,收敛到分类正确即可,这个后续会讲到~这次的内容到这啦,希望大家交流指错,很多都是自己的理解总结,希望对大家有帮助,谢谢!欢迎大家指错交流~
后续文章预告:
《浅析感知机(二)--学习算法与收敛性证明》
《浅析感知机(三)--python实现源代码分析》
这里在安利一下,我是完全按李航博士书籍来学习,欢迎关注交流~哈哈哈哈
参考以下内容:
李航博士《统计学习方法》
致谢:郭江师兄,晓明师兄,德川,皓宇,继豪,海涛师兄
