
使用Python进行语音识别---将音频转为文字

自从入职以来,一直在做关于ArcGIS视频的中英字幕,前前后后已经做了不少。基本都上传到网上了,有兴趣的可以看看ArcGIS培训视频中心的自频道-优酷视频
说实话,这是个挺废时间的工作,一般一个5-6分钟的视频,从听写字幕脚本到时间轴校对,校对完之后逐句翻译,本着自己的水平,不求信达雅,只求通畅就行,然后再加一些DuangDuang字幕特效,最后将字幕和视频进行,基本是3-4个小时,可能看起来不可思议,有兴趣的可以亲自去尝试一下。
虽然过程是枯燥乏味的,但是最终看到自己的成果,成就感也是油然而生的。

中英字幕 小样
前段时间美国Esri举办了全球的开发者大会,我在YouTube上看到陆续有上传的现场视频,于是下了下来,想着翻译一些,然后在ArcGIS知乎上等渠道做一下传播推广。但是有个问题是,这些视频没有字幕脚本,更坑爹的是,里面大部分是印度人主讲,带着印度咖喱腔的英语,听起来着实费解,所以翻译进度远不如之前,慢得出其,让我很困惑。做了几个视频的字幕后,实在没动力了,于是就暂停了。。。。
今天看了一篇报道,说是语音识别的技术,成熟度已经很可观了。突然想到:能不能将视频转为音频,然后使用一些语音识别的技术,完成这个艰巨的活呢。于是说干就干,百度搜索了许多音频转文字的技术。最后发现IBM公司有这项技术,对音频的识别率很高,并且提供有1000分钟的免费API(可以在IBM Bluemix - Next-Generation Cloud App Development Platform注册一下,获取API用户名和密码,后续会有用,这个很关键!!!),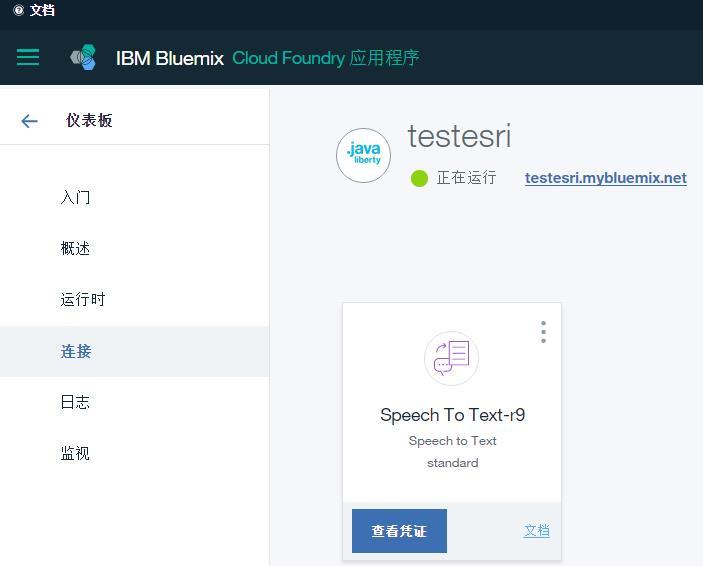

IBM注册 应用部署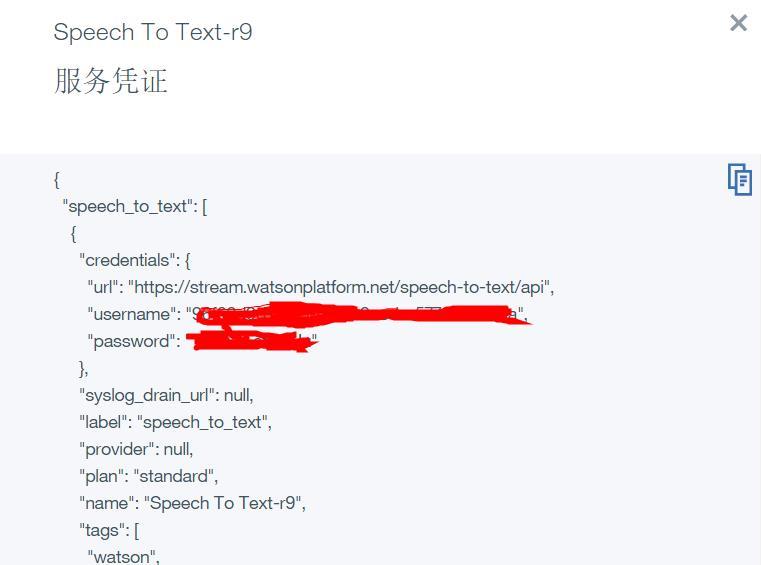

账户密码
正好也支持Python调用,整个过程很简单,就是先安装IBM的模块,这里我使用的是speechrecognition模块,在pycharm直接可以搜索到并安装,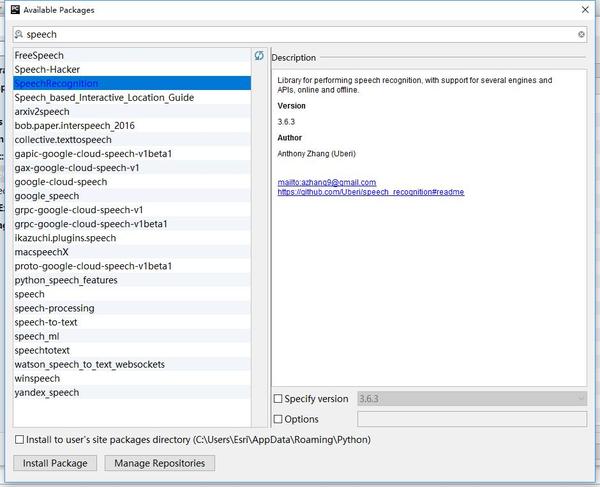

speechrecognition模块
speechrecognition模块不仅包含了IBM的语音识别API,还有微软、谷歌的语音识别API等等,带上github项目地址https://github.com/Uberi/speech_recognition#readme
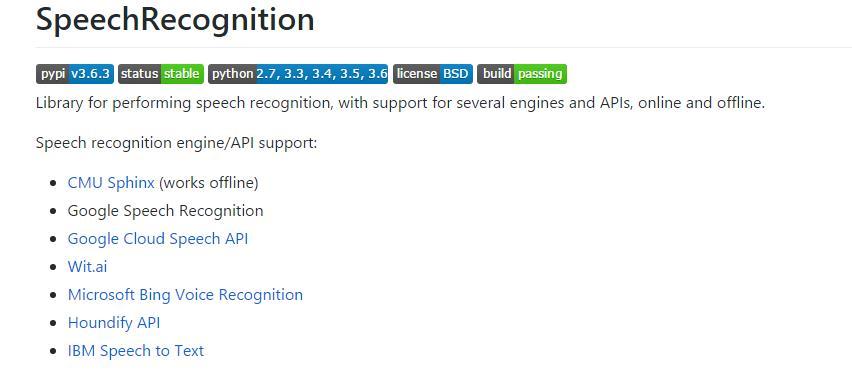

感叹到:Python的功能真是应有尽有,没有你想不到的。
然后我写了不多的几行代码,这个艰难的事情就迎刃而解了
思路主要如下,就是将视频转为WAV格式的音频(转为MP3等其他格式,可能识别不了),然后调用识别模块,就静静的等着或者去忙其他的事,最后会返回识别出来的文本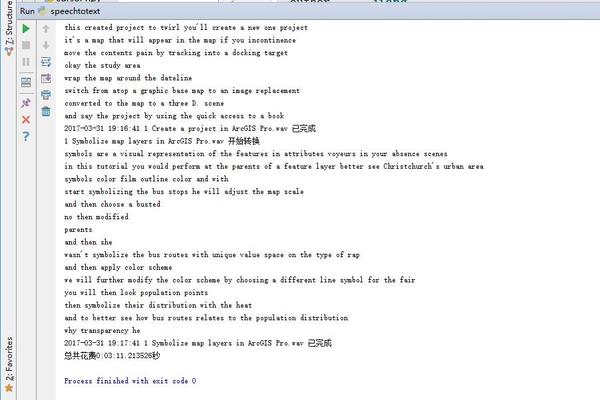

返回的识别文本
准确率还是很高的,估摸有80%-90%
如果你手上正好有一堆的音频想转为文字,赶紧来试试,解放生产力的时候到了!!哈哈~~~
附上我写的拙劣代码
见笑见笑!
#!/usr/bin/env python
# -*-coding:utf-8 -*-
__author__ = 'jiang'
# import eyed3
# import wave
import os
import speech_recognition as sr
# from pydub import AudioSegment
import time
import datetime
# ##获取音频时长
# f = wave.open(r"C:\Users\Esri\Desktop\speech.wav","rb")
# timelength=int(f.getparams()[3]/f.getparams()[2])
# print(int(5.6))
#
# ##音频分割输出
# readaudio=AudioSegment.from_wav(r'C:\Users\Esri\Desktop\speech.wav')
# kn=int(timelength/30)+1
# for i in range(kn):
# readaudio[i*30*1000:((i+1)*30+2)*1000].export(r'C:\Users\Esri\Desktop\speech\speech%d.wav'%(i+1), format="wav")
##获取文件夹下的音频文件名
starttime = datetime.datetime.now()
i = 1
for name in os.listdir(r'C:\Users\Esri\Desktop\speech'):
print("%d %s 开始转换" % (i, name))
##音频分块识别
r = sr.Recognizer()
# for i in range(kn):
try:
with sr.WavFile(r'C:\Users\Esri\Desktop\speech\%s' % name) as source:
audio = r.record(source)
IBM_USERNAME = '*******************'
IBM_PASSWORD = '*****'
text = r.recognize_ibm(audio, username=IBM_USERNAME, password=IBM_PASSWORD, language='en-US')
print(text)
open(r'C:\Users\Esri\Desktop\text\%s.txt' % name, 'a+').write(text)
time.sleep(5)
temptime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('%s %d %s 已完成' % (temptime,i, name))
except Exception as e:
print(e)
temptime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('%s %d %s 未完成' % (temptime, i, name))
continue
jietime = datetime.datetime.now()
last=jietime-starttime
print('总共花费时间:%s'%last)
测试结果分析:
1、IBM的API能识别英语、中文等好几种语言,识别的正确率很不错;
2、经过我的初步测试,IBM的识别机制是按照这样来的:先是将你的音频传到IBM的服务器,然后是打开音频实时识别,听起来很拗口,意思就是将音频放一遍,服务器边放边识别,最后将所有的识别以文本的形式(貌似是JSON格式,但是在speechrecognition模块中,已经转为文本)返回给你;
3、看完上面的识别机制,你可能会产生疑问:如果音频时间比较长,中间出现网络中断,之前识别的内容不就没了么。因此最好采取分段的方法,将音频分割为较短的几段,等效于实时的返回,减少丢失的问题;
4、经过测试,又有新问题,如果分段的话,超过10段以上,远程服务器会中断服务,也就是说:不能频繁的调接口,跟网站的发爬虫一样。多进程就别想了。最后部门石经理提供的解决办法是:识别一段后。等个5秒左右再循环下一个,照此方法可行。由于我自己的视频不长,数量也不多,就没做等待处理;
5、IBM的语音识别着实厉害,其他的语音识别等有时间再做测试。
欢迎关注我的小小公众号! zyouzz
分享RS/GIS,无人机,物联网,大数据技术和资讯,萃取行业动向,为每天的进步助力!
