
论文阅读笔记:Neural Belief Tracker--数据驱动的对话状态跟踪

标题:Neural Belief Tracker: Data-Driven Dialogue State Tracking
原文链接:Link
nlp-paper:NLP相关Paper笔记和代码复现
nlp-dialogue:一个开源的全流程对话系统,更新中!
说明:阅读原文时进行相关思想、结构、优缺点,内容进行提炼和记录,原文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
Abstract
belief tracker是现代口语对话系统的核心组件之一,它可以在对话的每个步骤中估算用户的目标,但是,大多数当前方法很难扩展到更大,更复杂的对话域。这是由于它们对以下方面的依赖:a)需要大量带注释的训练数据的口语理解模型;或b)手工制作的词典,用于捕获用户语言的某些语言变化。我们提出了一种新颖的Neural Belief Tracking (NBT) 框架,该框架通过基于表示学习的最新进展来克服这些问题。NBT通过推理对预先训练的单词向量进行建模,学习将其组合为用户话语和对话上下文的分布表示形式。我们对两个数据集的评估表明,该方法超越了过去的局限性,与依赖于手工制作的语义词典的最新模型的性能相匹配,并且在不提供此类词典的情况下其性能优于后者。
Introduction
下图中的示例显示了三轮对话中每个用户语句后的真实状态,从该示例可以看出,DST模型依赖于标识用户话语中的本体。


下图给出了一个针对三个槽值对的字典的示例(传统的做法是建语义词典),我们称其为非词化(delexicalisation)的这种方法显然无法扩展到更大,更复杂的对话域。如意大利语和德语这种词汇和形态丰富的语言。


在本文中,我们介绍了两个新模型,统称为 Neural Belief Tracker (NBT)系列,这些模型将SLU和DST结合在一起,可以有效地学习处理变化,而无需任何手工资源。
Background
- Separate SLU
- Joint SLU/DST
本文提出的工作的主要动机是克服影响以前的信念跟踪模型的限制。NBT模型通过以下方式有效地从可用数据中学习
- 利用预训练词向量中的语义信息来解决词汇/形态上的歧义
- 最大化本体值之间共享的参数数量
- 具有学习领域特定释义和其他变体的灵活性,这使得依靠精确匹配和去词缀化作为一种可靠的策略是不可行的
Neural Belief Tracker
下图展示了该模式下的信息流
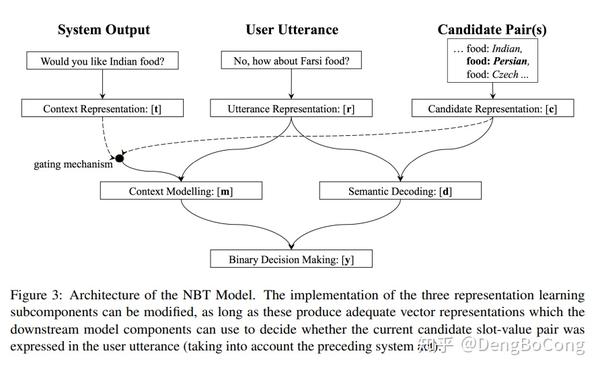

给定三个模型输入,NBT层次结构的第一层执行表示学习,从而为用户话语生成矢量表示 (r) ,当前的候选插槽值对表示 (c) ,系统对话动作表示为 (t_q, t_s, t_v) 。随后,学习到的向量表示通过上下文建模和语义解码子模块进行交互,以获得中间交互向量 d_r,d_c,d ,这些用作最终决策模块的输入,该模块决定用户是否表达了由候选插槽值对表示的意图。
目的是根据用户的输入(User Utterance,由ASR得到的结果,当然也可以直接是用户的文本输入)和系统上一轮的回复(System Output),遍历Domain Ontology(说白了就是某个领域内slot-value对可能取值)中每一个(slot,value)对,以判断用户真实意图中包含该slot-value对的概率大小。例如上图中的Domain Ontology存在三个可能的slot-value对,分别是(food, Indian), (food, Persian), (food, Czech)。而本论文的目的便是需要分别遍历这三个可能取值,假设当前遍历到了(food, Persian)这个取值,通过表征模型可以得到它的表征c,再通过图中所示的流程,最后可以得到一个结果y,这个结果便表明了(food, Persian)这个slot-value对属于用户真实意图的可能性大小。
Representation Learning
这里分别使用了两个模型来得到文本的表征:NBT-DNN和NBT-CNN,所有的表征学习都是建立在词向量上,论文说用专注于语义的词向量,效果会比普通的词向量好,可以看作是《同义词林》的“词向量版”。
模型的输入包括系统的前一个对话动作,用户的输入 u 和一个候选的slot-value对。输入 u 的词向量分别是 u_1,...,u_k 。 V_i^n 是n个词向量的拼接。
V_i^n=u_i⊕...⊕u_{i+n-1}
先看看NBT-DNN,结构如下图所示。计算累积n-gram特征向量 r_1, r_2, r_3 ,分别对应unigrams(1-gram),bigrams(2-gram)和trigrams(3-gram);再经过全连接层和非线性映射得到 r_n^{'} ,s代表不同的slot;最后求和得到用户输入的一个表征向量 r 。
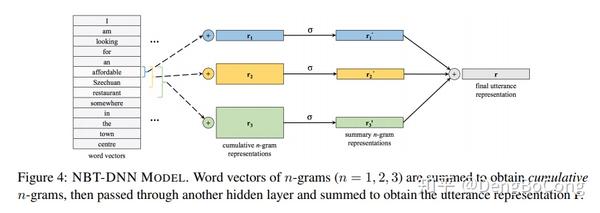

r_n=\sum_{i=1}^{k_u-n+1}V_i^n
r_n^{'}=\sigma (W_n^sr_n+b_n^s)
r=r_1^{'}+r_2^{'}+r_3^{'}
实际上,模型应该能学到哪些utterance是更重要的,如更侧重于形容词、名词的检测。因此,论文利用了NLU上得到成功应用的CNN架构实现第二个版本NBT-CNN。CNN结构也很熟悉,词向量的输入,过卷积层,抽n-gram特征,然后是非线性激活函数,max-pooling,求和。 F_n^s \in R^{L\times nD} 代表卷积过滤器, m_n=[V_1^n;V_2^n,...;V_{k-n+1}^n] 是n-grams的各个拼接词向量。
R_n=F_n^sm_n
r_n^{'}=maxpool(ReLU(R_n+b_n^s))
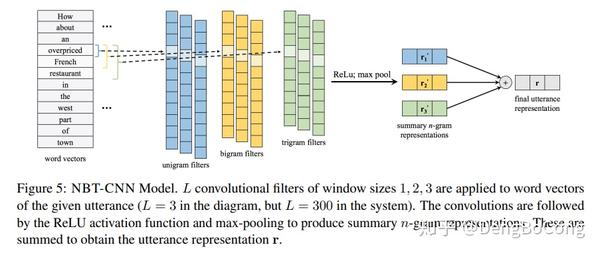

实际上就是一个简单的CNN模型,分别取了filter-size为1,2,3这三种,output size都是L=300。
Semantic Decoding
这个模块对表征 r 检测是否包含候选slot-value对 c ,处理方法也比较简单。 (c_s, c_v) 分别是slot和value的词向量表示,投影映射成与 r 相同维度的向量,点积求相似度 d 。
c=\sigma(W_c^s(c_s+c_v)+b_c^s)
d=r⊕c
这个模块主要是计算slot-value对和用户句子的关系,简单而言的话,slot的词向量(如果有多个词则简单相加)和value的词向量(如果有多个词则简单相加),通过一个全连接层和非线性映射后得到表征c(该表征将slot和value的信息融合成一个向量),与句子表征r进行element-wise的乘积,得到d(依然是一个向量)。
Context Modelling
当用户询问时,仅从当前用户的输入还不足以抽取意图,belief tracker应该考虑对话的上下文,特别是上一句系统的动作。论文提出了两种动作:System Request和System Confirm。
- 系统请求(System Request):系统上一轮在向用户请求一个具体的信息,比如”what price range would you like?”,此时用户需要给出一个具体的信息,此时用t(q)表示”price range”这个slot;
- 系统确认(System Confirm):系统上一轮在让用户在确认一个具体的信息,比如”‘how about Turkish food?’”,此时用户一般只需要回答是与不是即可,此时用(t(s),t(v))表示(food, Turkish)这个slot-value对。
第一种情景是,系统对一个特定的slot发出提问,用户一般会给出具体的value。第二种是系统询问用户,某个slot-value是否正确,用户一般只会回答对或错。这两个场景应分别计算。 t_q 是request的参数, (t_s, t_v) 是confirm的参数。 t_q,t_s,t_v 都是slot/value的词向量,多个词时直接求和得到。通过系统动作,候选对 (c_s,c_v) 作为一个门,控制输入表征 r 的信息输出(般情况下系统要么是请求,要么是确认,那么此时t(q)为0向量或者(t(s),t(v))是零向量。):
m_r=(c_s \cdot t_q)r
m_c=(c_s \cdot t_s)(c_v \cdot t_v)r
该机制有点类似于将候选槽值与系统请求某个槽的信息或确认某个槽值对,计算一个相似度(上面公式都是点乘),然后通过这个相似度对用户的句子表征进行一个类似于门的控制(主要是scale作用)。
Binary Decision Maker:最后的二分类决策层。 \phi_{dim}(x)=\sigma(W_x+b) 将输入 x 映射到维度为size的向量,softmax二分类,完成slot-value对的存在检测:
y=\phi_2(\phi_{100}(d)+\phi_{100}(m_r)+\phi_{100}(m_c))
Belief State Update Mechanism
论文提出了一种简单的belief state的更新机制:先估计当前轮对话的slot-value,再更新历史记录。在嘈杂的环境中,取ASR输出的前N个最佳结果(N-best list)进行分析。对于第 $t$ 轮对话, sys^{t-1} 表示前一个系统动作, h^t 是ASR输出的结果假设, h_i^t 是N-best list中的第 i 个, s 是slot, v 是value,NBT模型需要估计 (s,v) 在用户的口语输入中的概率:
\mathbb{P}(s,v|h^t, sys^{t-1})=\sum_{i=1}^{N}p_i^t\mathbb{P}(s,v|h_i^t,sys^t)
对于当前和历史对话的belief state更新,引入一个权重系数 \lambda :
\mathbb{P}(s,v|h^{1:t},sys^{1:t-1})=\lambda\mathbb{P}(s,v|h^t,sys^{t-1})+(1-\lambda)\mathbb{P}(s,v|h^{1:t-1},sys^{1:t-2})
然后对于slot s 检测到的values,取概率最大的作为当前的goal value。
Experiments
实验仍然是task-oriented的对话任务,数据集有两个:DSTC2和WOZ 2.0。
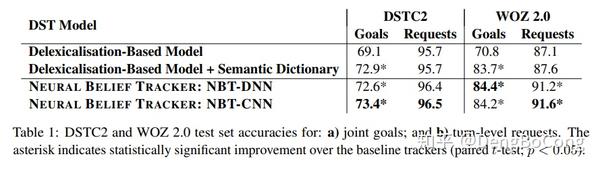

可以看到,NBT-DNN和NBT-CNN都能超过基于语义词典的模型,当然NBT-CNN多了不同n-grams特征的权重学习,会更好一点。论文还做了不同词向量对结果影响的实验。
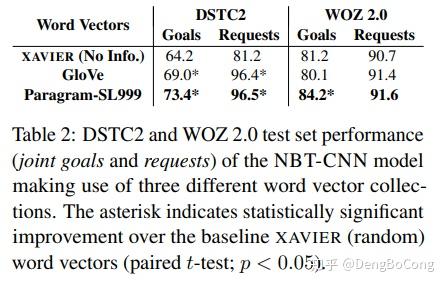

可以看出,专门针对语义任务的词向量Paragram-SL999对实验效果提升明显,这也很显然,先验知识更丰富,对下游的任务当然效果更佳。
Conclusion
在本文中,我们提出了一种新颖的神经信念跟踪(NBT)框架,旨在克服当前在现实世界中的对话域中部署对话系统的障碍。NBT模型提供了将口语理解和对话状态跟踪相结合的已知优势,而无需依赖手工制作的语义词典来实现最新的性能。我们的评估证明了这些好处:NBT模型与使用此类词典的模型的性能相匹配,并且在这些词典不可用时性能大大优于它们。最后,我们证明了NBT模型的性能随着底层单词向量的语义质量而提高。据我们所知,我们第一个超越内在评估并证明语义专业化可以提高下游任务性能。在未来的工作中,我们打算探索NBT在多域对话系统中的应用,以及在英语以外要求复杂形态变化处理的语言中的应用。
