奇异值分解的揭秘(一):矩阵的奇异值分解过程

矩阵的奇异值分解(singular value decomposition,简称SVD)是线性代数中很重要的内容,并且奇异值分解过程也是线性代数中相似对角化分解(也被称为特征值分解,eigenvalue decomposition,简称EVD)的延伸。因此,以下将从线性代数中最基础的矩阵分解开始讲起,引出奇异值分解的定义,并最终给出奇异值分解的低秩逼近问题相关的证明过程。
1 线性代数中的矩阵分解
我们在学习线性代数时,就已经接触了线性代数中的两个重要定理,即对角化定理和相似对角化定理,在这里,我们先简单地回顾一下这两个定理。另外,在接下来的篇幅里,我们所提到的矩阵都是指由实数构成的矩阵,即实矩阵。
给定一个大小为m\times m的矩阵A(是方阵),其对角化分解可以写成
A=U\Lambda U^{-1}
其中,U的每一列都是特征向量,\Lambda对角线上的元素是从大到小排列的特征值,若将U记作U=\left( \vec{u}_1,\vec{u}_2,...,\vec{u}_m \right) ,则
AU=A\left(\vec{u}_1,\vec{u}_2,...,\vec{u}_m\right)=\left(\lambda_1 \vec{u}_1,\lambda_2 \vec{u}_2,...,\lambda_m \vec{u}_m\right)
=\left(\vec{u}_1,\vec{u}_2,...,\vec{u}_m\right) \left[ \begin{array}{ccc} \lambda_1 & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & \lambda_m \\ \end{array} \right]
\Rightarrow AU=U\Lambda \Rightarrow A=U\Lambda U^{-1}
更为特殊的是,当矩阵A是一个对称矩阵时,则存在一个对称对角化分解,即
A=Q\Lambda Q^T
其中,Q的每一列都是相互正交的特征向量,且是单位向量,\Lambda对角线上的元素是从大到小排列的特征值。
当然,将矩阵Q记作Q=\left(\vec{q}_1,\vec{q}_2,...,\vec{q}_m\right),则矩阵A也可以写成如下形式:
A=\lambda_1 \vec{q}_1\vec{q}_1^T+\lambda_2 \vec{q}_2\vec{q}_2^T+...+\lambda_m \vec{q}_m\vec{q}_m^T
举一个简单的例子,如给定一个大小为2\times 2的矩阵A=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right],根据\left|\lambda I-A\right|=\left| \begin{array}{cc} \lambda-2 & -1 \\ -1 & \lambda-2 \\ \end{array} \right|=0求得特征值为\lambda_1=3,\lambda_2=1,相应地,\vec{q}_1=\left(\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T,\vec{q}_2=\left(-\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T,则
A=\lambda_1 \vec{q}_1\vec{q}_1^T+\lambda_2 \vec{q}_2\vec{q}_2^T =\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right].
这样,我们就很容易地得到了矩阵A的对称对角化分解。
2 奇异值分解的定义
在上面,对于对称的方阵而言,我们能够进行对称对角化分解,试想:对称对角化分解与奇异值分解有什么本质关系呢?
当给定一个大小为m\times n的矩阵A,虽然矩阵A不一定是方阵,但大小为m\times m的AA^T和n\times n的A^TA却是对称矩阵,若AA^T=P\Lambda_1 P^T,A^TA=Q\Lambda_2Q^T,则矩阵A的奇异值分解为
A=P\Sigma Q^T
其中,矩阵P=\left(\vec{p}_1,\vec{p}_2,...,\vec{p}_m\right)的大小为m\times m,列向量\vec{p}_1,\vec{p}_2,...,\vec{p}_m是AA^T的特征向量,也被称为矩阵A的左奇异向量(left singular vector);矩阵Q=\left(\vec{q}_1,\vec{q}_2,...,\vec{q}_n\right)的大小为n\times n,列向量\vec{q}_1,\vec{q}_2,...,\vec{q}_n是A^TA的特征向量,也被称为矩阵A的右奇异向量(right singular vector);矩阵\Lambda_1大小为m\times m,矩阵\Lambda_2大小为n\times n,两个矩阵对角线上的非零元素相同(即矩阵AA^T和矩阵A^TA的非零特征值相同,推导过程见附录1);矩阵\Sigma的大小为m\times n,位于对角线上的元素被称为奇异值(singular value)。
接下来,我们来看看矩阵\Sigma与矩阵AA^T和矩阵A^TA的关系。令常数k是矩阵A的秩,则k\leq \min\left( m,n \right) ,当m\ne n时,很明显,矩阵\Lambda_1和矩阵\Lambda_2的大小不同,但矩阵\Lambda_1和矩阵\Lambda_2对角线上的非零元素却是相同的,若将矩阵\Lambda_1(或矩阵\Lambda_2)对角线上的非零元素分别为\lambda_1,\lambda_2,...,\lambda_k,其中,这些特征值也都是非负的,再令矩阵\Sigma对角线上的非零元素分别为\sigma_1,\sigma_2,...,\sigma_k,则
\sigma_1=\sqrt{\lambda_1},\sigma_2=\sqrt{\lambda_2},...,\sigma_k=\sqrt{\lambda_k}
即非零奇异值的平方对应着矩阵\Lambda_1(或矩阵\Lambda_2)的非零特征值,到这里,我们就不难看出奇异值分解与对称对角化分解的关系了,即我们可以由对称对角化分解得到我们想要的奇异值分解。
为了便于理解,在这里,给定一个大小为2\times 2的矩阵A=\left[ \begin{array}{cc} 4 & 4 \\ -3 & 3 \\ \end{array} \right],虽然这个矩阵是方阵,但却不是对称矩阵,我们来看看它的奇异值分解是怎样的。
由AA^T=\left[ \begin{array}{cc} 32 & 0 \\ 0 & 18 \\ \end{array} \right]进行对称对角化分解,得到特征值为\lambda_1=32,\lambda_2=18,相应地,特征向量为\vec{p}_1=\left( 1,0 \right) ^T,\vec{p}_2=\left(0,1\right)^T;由A^TA=\left[ \begin{array}{cc} 25 & 7 \\ 7 & 25 \\ \end{array} \right]进行对称对角化分解,得到特征值为\lambda_1=32,\lambda_2=18,相应地,特征向量为\vec{q}_1=\left(\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right)^T,\vec{q}_2=\left(-\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T。取\Sigma =\left[ \begin{array}{cc} 4\sqrt{2} & 0 \\ 0 & 3\sqrt{2} \\ \end{array} \right],则矩阵A的奇异值分解为
A=P\Sigma Q^T=\left(\vec{p}_1,\vec{p}_2\right)\Sigma \left(\vec{q}_1,\vec{q}_2\right)^T
=\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} 4\sqrt{2} & 0 \\ 0 & 3\sqrt{2} \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] =\left[ \begin{array}{cc} 4 & 4 \\ -3 & 3 \\ \end{array} \right].
若矩阵A不再是一个方阵,而是一个大小为3\times 2的A=\left[ \begin{array}{cc} 1 & 2 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right],由AA^T=\left[ \begin{array}{ccc} 5 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} \right]得到特征值为\lambda_1=5,\lambda_2=\lambda_3=0,特征向量为\vec{p}_1=\left(1,0,0\right)^T,\vec{p}_2=\left(0,1,0\right)^T,\vec{p}_3=\left(0,0,1\right)^T;由A^TA=\left[ \begin{array}{cc} 1 & 2 \\ 2 & 4 \\ \end{array} \right]得到特征值为\lambda_1=5,\lambda_2=0,特征向量为\vec{q}_1=\left(\frac{\sqrt{5}}{5},\frac{2\sqrt{5}}{5}\right)^T,\vec{q}_2=\left(-\frac{2\sqrt{5}}{5},\frac{\sqrt{5}}{5}\right)^T,令\Sigma=\left[ \begin{array}{cc} \sqrt{5} & 0 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right](注意:矩阵\Sigma大小为3\times 2),此时,矩阵A的奇异值分解为
A=P\Sigma Q^T=\left(\vec{p}_1,\vec{p}_2\right)\Sigma \left(\vec{q}_1,\vec{q}_2\right)^T
=\left[ \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} \sqrt{5} & 0 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{5}}{5} & \frac{2\sqrt{5}}{5} \\ -\frac{2\sqrt{5}}{5} & \frac{\sqrt{5}}{5} \\ \end{array} \right] =\left[ \begin{array}{cc} 1 & 2 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right].
比较有趣的是,假设给定一个对称矩阵A=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right],它是对称矩阵,则其奇异值分解是怎么样的呢?
分别计算AA^T和A^TA,我们会发现,AA^T=A^TA=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right] \left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right] =\left[ \begin{array}{cc} 5 & 4 \\ 4 & 5 \\ \end{array} \right],左奇异向量和右奇异向量构成的矩阵也是相等的,即P=Q=\left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right],更为神奇的是,该矩阵的奇异值分解和对称对角化分解相同,都是A=\left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] \left[ \begin{array}{cc} 3 & 0 \\ 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right]。这是由于对于正定对称矩阵而言,奇异值分解和对称对角化分解结果相同。
3 奇异值分解的低秩逼近
在对称对角化分解中,若给定一个大小为3\times 3的矩阵A=\left[ \begin{array}{ccc} 30 & 0 & 0 \\ 0 & 20 & 0 \\ 0 & 0 & 1 \\ \end{array} \right],很显然,矩阵A的秩为rank\left(A\right)=3,特征值为\lambda_1=30,\lambda_2=20,\lambda_3=1,对应的特征向量分别为\vec{q}_1=\left(1,0,0\right)^T,\vec{q}_2=\left(0,1,0\right)^T,\vec{q}_3=\left(0,0,1\right)^T,考虑任意一个向量\vec{v}=\left(2,4,6\right)^T=2\vec{q}_1+4\vec{q}_2+6\vec{q}_3,则
A\vec{v}=A\left(2\vec{q}_1+4\vec{q}_2+6\vec{q}_3\right)
=2\lambda_1\vec{q}_1+4\lambda_2\vec{q}_2+6\lambda_3\vec{q}_3=60\vec{q}_1+80\vec{q}_2+6\vec{q}_3
在这里,我们会发现,即使\vec{v}是一个任意向量,用矩阵A去乘以\vec{v}的效果取决于A较大的特征值及其特征向量,类似地,在奇异值分解中,较大的奇异值会决定原矩阵的“主要特征”,下面我们来看看奇异值分解的低秩逼近(有时也被称为截断奇异值分解)。需要说明的是,接下来的部分是从文献《A Singularly Valuable Decomposition: The SVD of a Matrix》整理而来的。
给定一个大小为m\times n的矩阵A,由于A=P\Sigma Q^T可以写成
A=\sum_{i=1}^{k}{\sigma_i\vec{p}_i\vec{q}_i^T}=\sigma_1\vec{p}_1\vec{q}_1^T+\sigma_2\vec{p}_2\vec{q}_2^T+...+\sigma_k\vec{p}_k\vec{q}_k^T
其中,向量\vec{p}_1,\vec{p}_2,...,\vec{p}_k之间相互正交,向量\vec{q}_1,\vec{q}_2,...,\vec{q}_k之间也相互正交,由内积\left<\sigma_i\vec{p}_i\vec{q}_i^T,\sigma_j\vec{p}_j\vec{q}_j^T\right>=0,1\leq i\leq k,1\leq j\leq k,i\ne j(有兴趣的读者可以自行推算)得到矩阵A的F-范数的平方为
||A||_F^2=||\sigma_1\vec{p}_1\vec{q}_1^T+\sigma_2\vec{p}_2\vec{q}_2^T+...+\sigma_k\vec{p}_k\vec{q}_k^T||_F^2 =\sigma_1^2||\vec p_1\vec q_1^T||_F^2+\sigma_2^2||\vec p_2\vec q_2^T||_F^2+...+\sigma_k^2||\vec p_k\vec q_k^T||_F^2 =\sigma_1^2+\sigma_2^2+...+\sigma_k^2=\sum_{i=1}^{r}{\sigma_i^2}
知道了矩阵A的F-范数的平方等于其所有奇异值的平方和之后,假设A_1=\sigma_1\vec p_1\vec q_1^T是矩阵A的一个秩一逼近(rank one approximation),那么,它所带来的误差则是\sigma_2^2+\sigma_3^2+...+\sigma_k^2(k是矩阵A的秩),不过如何证明A_1=\sigma_1\vec p_1\vec q_1^T是最好的秩一逼近呢?
由于||A-A_1||_F^2=||P\Sigma Q^T-A_1||_F^2=||\Sigma-P^TA_1Q||_F^2(证明过程见附录2),令P^TA_1Q=\alpha \vec x\vec y^T,其中,\alpha是一个正常数,向量\vec x和\vec y分别是大小为m\times 1和n\times 1的单位向量,则
||\Sigma-P^TA_1Q||_F^2=||\Sigma-\alpha \vec x\vec y^T||_F^2 =||\Sigma||_F^2+\alpha^2-2\alpha \left<\Sigma, \vec x\vec y^T\right>
单独看大小为m\times n的矩阵\Sigma和\vec x\vec y^T的内积\left<\Sigma, \vec x\vec y^T\right>,我们会发现,
\left<\Sigma, \vec x\vec y^T\right>=\sum_{i=1}^{k}{\sigma_i x_i y_i}\leq \sum_{i=1}^{k}{\sigma_i\left| x_i\right|\left| y_i\right|}
\leq\sigma_1 \sum_{i=1}^{k}{\left| x_i\right|\left| y_i\right|}=\sigma_1\left<\vec x^*,\vec y^*\right> \leq \sigma_1||\vec x^*||\cdot ||\vec y^*||\leq \sigma_1||\vec x||\cdot ||\vec y||=\sigma_1
其中,需要注意的是,x_i,y_i分别是向量\vec x和\vec y的第i个元素;向量\vec x^*=\left(\left|x_1\right|,\left|x_2\right|,...,\left|x_k\right|\right)^T的大小为k\times 1,向量\vec y^*=\left(\left|y_1\right|,\left|y_2\right|,...,\left|y_k\right|\right)^T的大小也为k\times 1,另外,以\vec x^*为例,||\vec x^*||=\sqrt{x_1^2+x_2^2+...+x_k^2}是向量的模,则||A-A_1||_F^2(残差矩阵的平方和)为
||\Sigma-\alpha \vec x\vec y^T||_F^2\geq ||\Sigma||_F^2+\alpha^2-2\alpha \sigma_1 =||\Sigma||_F^2+\left(\alpha-\sigma_1\right)^2-\sigma_1^2
当且仅当\alpha=\sigma_1时,||A-A_1||_F^2取得最小值\sigma_2^2+\sigma_3^2+...+\sigma_k^2,此时,矩阵A的秩一逼近恰好是A_1=\sigma_1\vec p_1\vec q_1^T.
当然,我们也可以证明A_2=\sigma_2\vec p_2\vec q_2^T是矩阵A-A_1的最佳秩一逼近,以此类推,A_r=\sigma_r\vec p_r\vec q_r^T,r< k是矩阵A-A_1-A_2-...-A_{r-1}的最佳秩一逼近。由于矩阵A_1+A_2+...+A_r的秩为r,这样,我们可以得到矩阵A的最佳秩r逼近(rank-r approximation),即
A\approx A_1+A_2+...+A_r=\sum_{i=1}^{r}{A_i}.
这里得到的矩阵P_r的大小为m\times r,矩阵\Sigma_r的大小为r\times r,矩阵Q_r的大小为n\times r,矩阵A可以用P_r\Sigma_rQ_r^T来做近似。
用低秩逼近去近似矩阵A有什么价值呢?给定一个很大的矩阵,大小为m\times n,我们需要存储的元素数量是mn个,当矩阵A的秩k远小于m和n,我们只需要存储k(m+n+1)个元素就能得到原矩阵A,即k个奇异值、km个左奇异向量的元素和kn个右奇异向量的元素;若采用一个秩r矩阵A_1+A_2+...+A_r去逼近,我们则只需要存储更少的r(m+n+1)个元素。因此,奇异值分解是一种重要的数据压缩方法。
另外,关于奇异值分解的应用将在该系列后续文章中进行详述。
---------------------------------------------------------------
附录1:相关链接:Largest eigenvalues of AA&#x27; equals to A&#x27;A,截图如下:
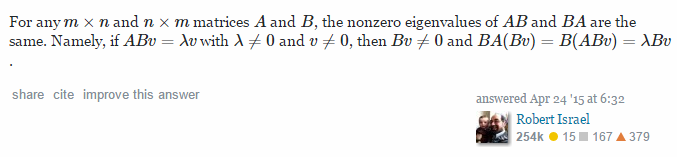

附录2:求证:||P\Sigma Q^T-A_1||_F^2=||\Sigma-P^TA_1Q||_F^2,其中,QQ^T=I,PP^T=I.
证明:||P\Sigma Q^T-A_1||_F^2
=trace \left(\left(P\Sigma Q^T-A_1\right)\left(P\Sigma Q^T-A_1\right)^T\right)
=trace \left(\left(P\Sigma Q^T-A_1\right)QQ^T\left(P\Sigma Q^T-A_1\right)^T\right)
=trace \left(\left(P\Sigma -A_1Q\right)\left(\Sigma^T P^T-Q^TA_1^T\right)\right)
=trace \left(\left(\Sigma^T P^T-Q^TA_1^T\right)\left(P\Sigma -A_1Q\right)\right)
=trace \left(\left(\Sigma^T P^T-Q^TA_1^T\right)PP^T\left(P\Sigma -A_1Q\right)\right)
=trace \left(\left(\Sigma^T -Q^TA_1^TP\right)\left(\Sigma -P^TA_1Q\right)\right)
=||\Sigma-P^TA_1Q||_F^2.
好书推荐
一、《矩阵计算》被誉为数值计算领域的“圣经”,该书以线性代数为基础,系统地介绍了矩阵计算的基本理论和方法,并附有大量算法、习题和参考文献,据谷歌学术 (Google Scholar) 引用数据显示,该书已被引用超过7.5万次,是一本不可多得的好书。目前,人民邮电出版社已获得授权在国内出版,并发行了中文版与英文版。
二、机器学习领域经典中文著作《机器学习》,南京大学周志华教授西瓜书。