
斯坦福CS224N深度学习自然语言处理-assignment1

I'm no one.
一、证明softmax函数,对于所有input向量x都减去一个常向量c,并不影响整体结果。


关于本题额外参考:


"softmax函数的本质就是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间,并且总和为1。"
"看名字就知道了,就是如果某一个zj大过其他z,那这个映射的分量就逼近于1,其他就逼近于0,主要应用就是多分类,sigmoid函数只能分两类,而softmax能分多类,softmax是sigmoid的扩展。"
softmax的代价函数:
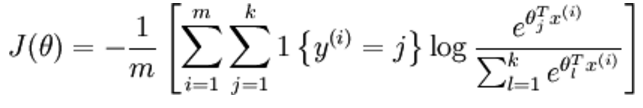

经过求导,我们得到梯度公式如下:
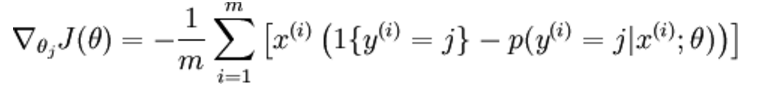



如何利用这个结论:




额外扩展:




二、利用上述的优化公式,对每一行计算softmax预测。完善代码。
题目二待续==============================================
三、推导sigmoid的梯度,并以函数\sigma (x)形式表示,而非x。


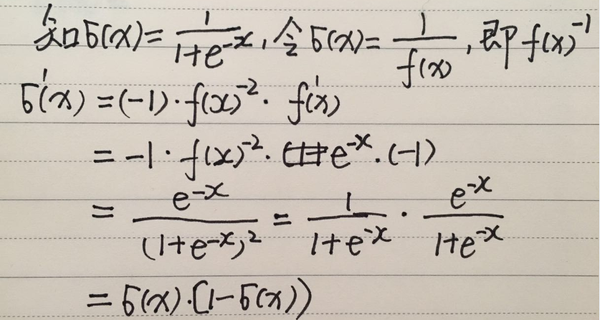

四、推导交叉熵梯度。其中y是one-hot形式的真实label,y^是softmax产出的对于每个类别的概率预测结果。




(对于后面这种\theta{i} 更易于理解。对于上面sigmoid以及本题对CE求导的结论,应当当作常识知识牢牢记住。)
五、对于一层隐层NN,CE作为loss,对x进行求导。
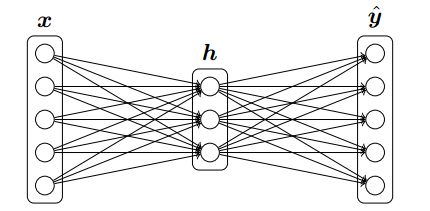

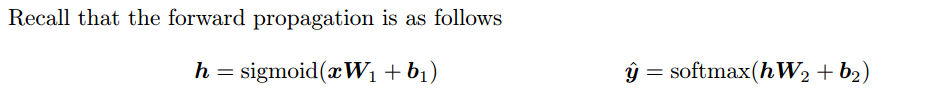

(即将NN先看作一个黑盒的话,求CE对x的导。)
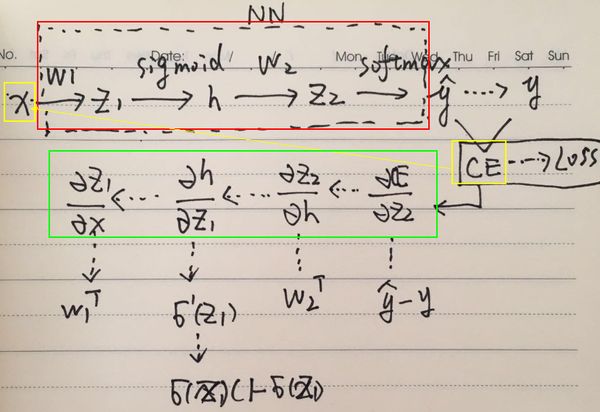

(根据链式法则以及前面两题的结论,可得上述的结果。官方的结果只是形式稍有不同。)
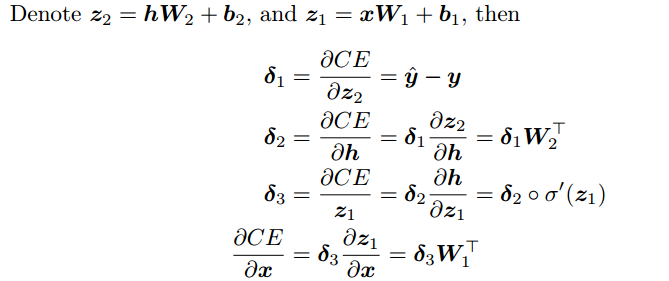

六、input有D{x}维,output有D{y}维,有H个隐含节点,问一共有多少个参数?

(x作为输入时,要额外加一个偏移项;h作为输入时,也要额外加一个偏移项。)
编写代码题目待续。
编辑于 2017-05-11 08:49
