![[OSDI'20] Assise: Distributed FS w/ NVM Colocation](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[OSDI'20] Assise: Distributed FS w/ NVM Colocation

早睡早起
Assise: Performance and Availability via NVM Colocation in a Distributed File System
Thomas E. Anderson, Marco Canini , Jongyul Kim, Dejan Kostic, Youngjin Kwon, Simon Peter, Waleed Reda , Henry N. Schuh, Emmett Witchel
Background on NVM (Non-Volatile Memory):


Background on Disaggregation
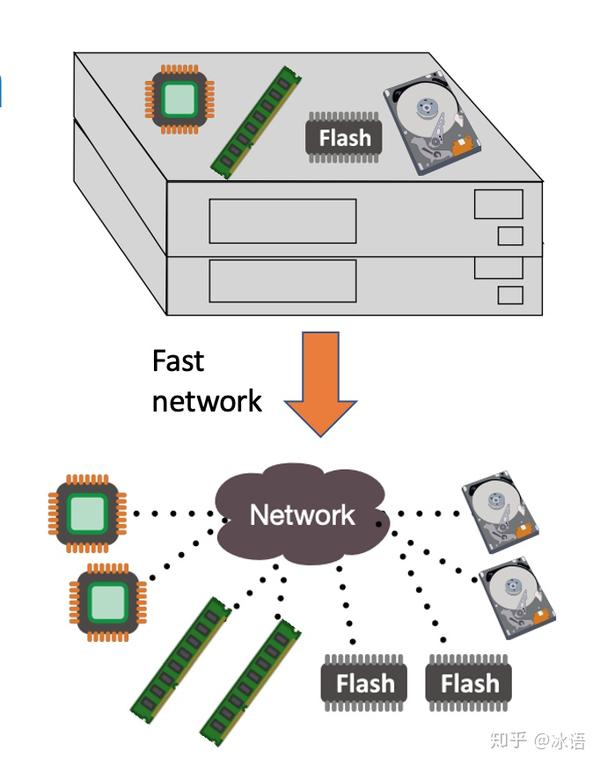

•monolithic servers =>network-attached resource pools
Why disaggregation is possible now?
- Network bandwidth/latency is sufficient to support current applications[1,2]
Current distributed file system design
- Current design paradigm: Storage disaggregation


- Separate servers from clients (files physically separate from clients)
- Client’s main memory is treated as volatile.
But it has disadvantages when
- On cache miss, multiple network RTT overhead to consult metadata servers and get data
- On failure, rebuild data and metadata caches on client from scratch (high recovery time and high network utilization during recovery)
- I/O size smaller than page block will downgrade performance


Start with measuring NVM: (some key points)
- Access NVM with RDMA is still faster than local SSD
- NVM access speed is fast to slow based on locality
NVM accessed via RDMA (NVM-RDMA), via loads and stores to another CPU socket (NVM-NUMA), or via system calls on the same socket (NVM-kernel) can be an order of magnitude slower in terms of both latency and bandwidth.
- NVM-RDMA write latency is twice higher than read, because RDMA writes have to invoke the remote CPU (to flush caches
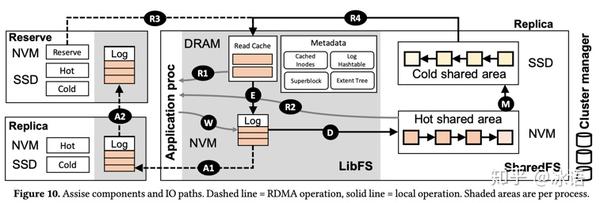

Assise IO path
Write:
- First writes to process-level cache (update log) in NVM (W)
- Update log is replicated to cache replica (remote NVM), on fsync/dsync. (A1, A2)
- The last replica sends back ack so sync returns.
- When the update log fills, a digest is initiated. (D)
Read:
- First check local DRAM cache (R1)
- If not found, check the hot shared area on SharedFS (R2)
- If not found, check remote replica (RDMA) and local SSD in parallel. (R3,R4)
- Also prefetch to local DRAM, DRAM cache evicted to NVM update log. (E)
CC-NVM (CrashconsistentcachecoherenceNVM)
- Crash consistency with prefix semantics
- Given a sequence: W1,o1,W2,o2,...,Wn,on
- If crash after fsync oi, the file system will recover to a state with W1,W2,...,Wi applied.
- Achieved with ordering guarantees of (R)DMA to write the log in order to replicas.
Sharing with linearizability with Leases
- Leases are similar to reader-writer locks. but can be revoked and expire after a timeout. (can be re-acquired)
- Use lease to grant shared read or exclusive write.
- LibFS can acquire lease from SharedFS via syscall
- SharedFS enforces the process’s private update log and cache entries are clean and replicated before lease transfer.
- The lease transfer are also logged and replicated in NVM.
- (hierarchical access) LibFS -> SharedFS -> cluster manager
- If lease is held by another SharedFS, wait.
- Minimize network communication and thus lease delegation overhead.
Assise:Recovery and fail-over strategy
- LibFS recovery:
- SharedFS will evict dead update log/expire lease, restart process.
- DRAM cache will be re-built.
- SharedFS recovery
- Restart to checkpointing. LibFS status can be recovered by the SharedFS log in NVM
- Cache replica fail-over
- In case of power failure, fail over to cache replica
- The replica’s SharedFS will take over lease management.
- The writes during failover will invalidate the cached data on the failed node. This is done by tracking a file block bitmap on an epoch basis.
- Node recovery
- First, recover the shared FS, then invalidates all written blocks since crash.
Key take-aways
- For distributed file system, NVM’s unique characteristics require cache and manage data on co-located persistent memory. (which seems to be against the trend of resource disaggregation, but it makes more sense because access NVM locally is definitely faster than access via RDMA.
[1] Is memory disaggregation feasible?: A case study with Spark SQL. ANCS’16
[2] Network Requirements for Resource Disaggregation. OSDI’16
编辑于 2020-12-05 06:06
