爬虫网址中有中文字符时如何处理

有那么一瞬间,突然就长大了
问题
python不支持中文,它是解释性语言;解析器只支持 ASCII 0-127,所以当爬虫的网址中带有中文字符的时候,会报错
UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-14: ordinal not in range(128)


解决办法
所以在进行爬取之前,需要进行中文汉字------>ASCII的转译
在不知道urllib.parse之前,我是这样做的
把需要转译的汉字单独处理:
例如:以贴吧的少年三国志吧为例:我在网址栏里面看到的是这样的:
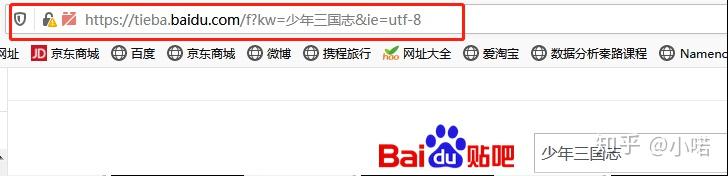
当我粘贴复制在编译器里面的时候是这样的:
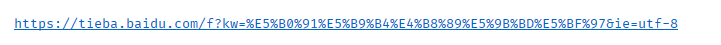

所以如果你爬取的网页带有中文字符,需要进行转译,才能在爬虫的时候请求成功,当时因为方法不对,没有找到urllib.parse库,但是我知道字符之间的转译,尝试了使用方法
print('少年三国志'.encode('utf-8'))得出的结果是:
b'\xe5\xb0\x91\xe5\xb9\xb4\xe4\xb8\x89\xe5\x9b\xbd\xe5\xbf\x97'
和编译器复制的连接做对比,发现把结果中的开始前的b'和末尾的' 去掉,并且将\x替换成%,再将小写字母大写就可以了
例如:
def text(cn):
s1 = str(cn.encode('utf-8'))
s2 = s1.lstrip("b'")
s3 = s2.rstrip("'")
s4 = s3.replace(r'\x', '%')
s5 = s4.upper()
print(s5)
text('少年三国志')输出:
%E5%B0%91%E5%B9%B4%E4%B8%89%E5%9B%BD%E5%BF%97
然后再用字符串拼接成完整的网址
def text(cn):
s1 = str(cn.encode('utf-8'))
s2 = s1.lstrip("b'")
s3 = s2.rstrip("'")
s4 = s3.replace(r'\x', '%')
s5 = s4.upper()
url1 = 'https://tieba.baidu.com/f?kw=' + s5 + '&ie=utf-8'
print(url1)
text('少年三国志')输出:


然后后来再回头看这个问题的时候,明确了搜索方向,即爬虫中网址遇到中文字符怎么处理时,看到有个包是url.parse
只需要一步就转换过来了:
def cn_utf(name):
url1 = 'https://tieba.baidu.com/f?kw=' + name + '&ie=utf-8'
post_url = urllib.parse.quote(url1,safe=string.printable)
print(post_url)
cn_utf('少年三国志')输出:


补充:有编码就会有解码,解码用到方法unquote
例如:
def cn(utfurl):
cn_url = urllib.parse.unquote(utfurl)
print(cn_url)
cn('https://tieba.baidu.com/f?kw=%E5%B0%91%E5%B9%B4%E4%B8%89%E5%9B%BD%E5%BF%97&ie=utf-8')输出:


发布于 2020-10-23 22:16