
前端知识点总结——堆内存与栈内存

首先 JavaScript 中的变量分为基本类型和引用类型。
基本类型就是保存在栈内存中的简单数据段,而引用类型指的是那些保存在堆内存中的对象。
1 、基本类型
基本类型有 Undefined、Null、Boolean、Number 和String。这些类型在内存中分别占有固定大小的空间,他们的值保存在栈空间,我们通过按值来访问的。
2 、引用类型
引用类型,值大小不固定,栈内存中存放地址指向堆内存中的对象。是按引用访问的。如下图所示:栈内存中存放的只是该对象的访问地址, 在堆内存中为这个值分配空间 。 由于这种值的大小不固定,因此不能把它们保存到栈内存中。但内存地址大小的固定的,因此可以将内存地址保存在栈内存中。 这样,当查询引用类型的变量时, 先从栈中读取内存地址, 然后再通过地址找到堆中的值。对于这种,我们把它叫做按引用访问。
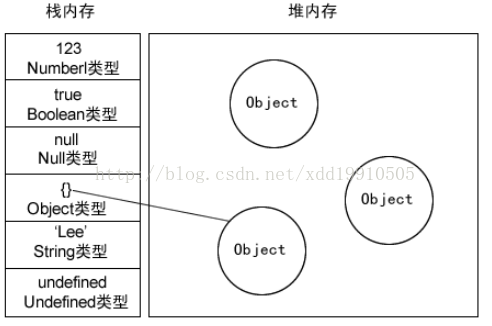

当我们看到一个变量类型是已知的,就分配在栈里面,比如INT,Double等。其他未知的类型,比如自定义的类型,因为系统不知道需要多大,所以程序自己申请,这样就分配在堆里面。
为什么会有栈内存和堆内存之分?
通常与垃圾回收机制有关。为了使程序运行时占用的内存最小。
当一个方法执行时,每个方法都会建立自己的内存栈,在这个方法内定义的变量将会逐个放入这块栈内存里,随着方法的执行结束,这个方法的内存栈也将自然销毁了。因此,所有在方法中定义的变量都是放在栈内存中的;
当我们在程序中创建一个对象时,这个对象将被保存到运行时数据区中,以便反复利用(因为对象的创建成本通常较大),这个运行时数据区就是堆内存。堆内存中的对象不会随方法的结束而销毁,即使方法结束后,这个对象还可能被另一个引用变量所引用(方法的参数传递时很常见),则这个对象依然不会被销毁,只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在核实的时候回收它。
js中如果创建两个个对象p1,p2,使用p1为p2赋值会怎样?
var p1 = new Person();
p1.name = ‘zhangsan’;
p1.age = 30;
var p2 = p1;
这时,p1和p2会指向同一内存
function person(){
}
var p1 = new person();
p1.name= 'zhangshan';
var p2= p1;//对象之间赋值,现在p1 和 p2指向的是同一个内存空间
// alert(p2.name);
var p2 = 'apple'; //将p2的值发生改变会影响p1的值
// alert(p1.name);
p2 = null ;//这里是指将p2的栈内存清除了,但是p2指向的堆内存还是存在!
// alert(p2.name);
alert(p1.name);//所以这里可以输出结果!
栈(操作系统):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由
OS回收,分配方式倒是类似于链表。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些
堆(数据结构):堆可以被看成是一棵树,如:堆排序
栈(数据结构):一种后进先出的的数据结构
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。