
Kubernetes Scheduler分析

调度是Kubernetes集群中进行容器编排工作重要的一环,在Kubernetes中,Controller Manager负责Pod等副本管理,Kubelet负责拉起Pod,而Scheduler就是负责安排Pod到具体的Node,它通过API Server提供的接口监听Pods,获取待调度pod,然后根据一系列的预选策略和优选策略给各个Node节点打分排序,然后将Pod调度到得分最高的Node节点上,然后由kubelet负责拉起Pod。架构流程如下:
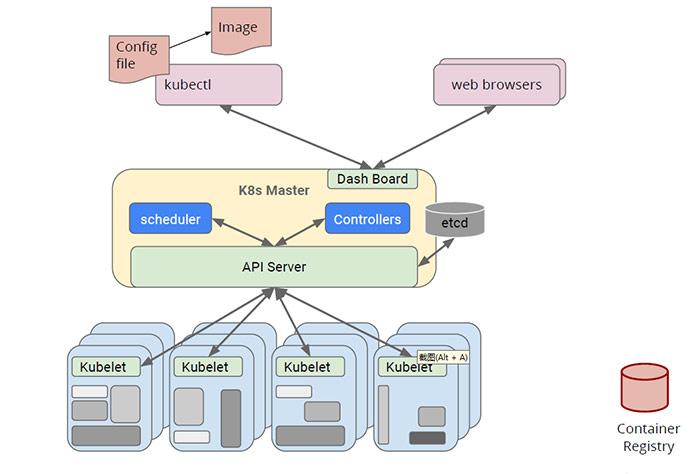

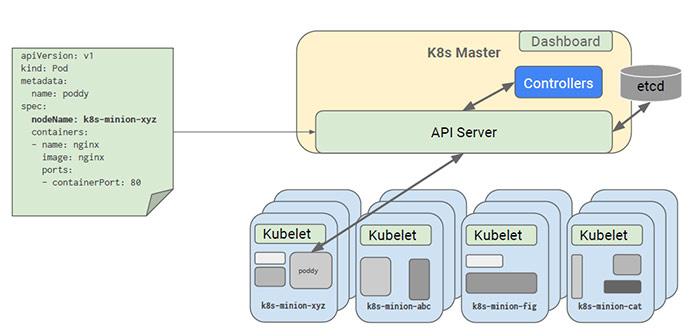
如果Pod中指定了NodeName属性,则无需Scheduler参与,Pod会直接被调度到NodeName指定的Node节点
1 调度策略
Kubernetes的调度策略分为Predicates(预选策略)和Priorites(优选策略),整个调度过程分为两步:
- 预选策略,是强制性规则,遍历所有的Node,按照具体的预选策略筛选出符合要求的Node列表,如没有Node符合Predicates策略规则,那该Pod就会被挂起,直到有Node能够满足;
- 优选策略,在第一步筛选的基础上,按照优选策略为待选Node打分排序,获取最优者;
1.1 预选策略
随着版本的演进Kubernetes支持的Predicates策略逐渐丰富,v1.0版本仅支持4个策略,v1.7支持15个策略,Kubernetes(v1.7)中可用的Predicates策略有:
- MatchNodeSelector:检查Node节点的label定义是否满足Pod的NodeSelector属性需求
- PodFitsResources:检查主机的资源是否满足Pod的需求,根据实际已经分配的资源(request)做调度,而不是使用已实际使用的资源量做调度
- PodFitsHostPorts:检查Pod内每一个容器所需的HostPort是否已被其它容器占用,如果有所需的HostPort不满足需求,那么Pod不能调度到这个主机上
- HostName:检查主机名称是不是Pod指定的NodeName
- NoDiskConflict:检查在此主机上是否存在卷冲突。如果这个主机已经挂载了卷,其它同样使用这个卷的Pod不能调度到这个主机上,不同的存储后端具体规则不同
- NoVolumeZoneConflict:检查给定的zone限制前提下,检查如果在此主机上部署Pod是否存在卷冲突
- PodToleratesNodeTaints:确保pod定义的tolerates能接纳node定义的taints
- CheckNodeMemoryPressure:检查pod是否可以调度到已经报告了主机内存压力过大的节点
- CheckNodeDiskPressure:检查pod是否可以调度到已经报告了主机的存储压力过大的节点
- MaxEBSVolumeCount:确保已挂载的EBS存储卷不超过设置的最大值,默认39
- MaxGCEPDVolumeCount:确保已挂载的GCE存储卷不超过设置的最大值,默认16
- MaxAzureDiskVolumeCount:确保已挂载的Azure存储卷不超过设置的最大值,默认16
- MatchInterPodAffinity:检查pod和其他pod是否符合亲和性规则
- GeneralPredicates:检查pod与主机上kubernetes相关组件是否匹配
- NoVolumeNodeConflict:检查给定的Node限制前提下,检查如果在此主机上部署Pod是否存在卷冲突
已注册但默认不加载的Predicates策略有:
- PodFitsHostPorts
- PodFitsResources
- HostName
- MatchNodeSelector
PS:此外还有个PodFitsPorts策略(计划停用),由PodFitsHostPorts替代
1.2 优选策略
同样,Priorites策略也在随着版本演进而丰富,v1.0版本仅支持3个策略,v1.7支持10个策略,每项策略都有对应权重,最终根据权重计算节点总分,Kubernetes(v1.7)中可用的Priorites策略有:
- EqualPriority:所有节点同样优先级,无实际效果
- ImageLocalityPriority:根据主机上是否已具备Pod运行的环境来打分,得分计算:不存在所需镜像,返回0分,存在镜像,镜像越大得分越高
- LeastRequestedPriority:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优,得分计算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
- BalancedResourceAllocation:节点上各项资源(CPU、内存)使用率最均衡的为最优,得分计算公式:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10
- SelectorSpreadPriority:按Service和Replicaset归属计算Node上分布最少的同类Pod数量,得分计算:数量越少得分越高
- NodeAffinityPriority:节点亲和性选择策略,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求)
- TaintTolerationPriority:类似于Predicates策略中的PodToleratesNodeTaints,优先调度到标记了Taint的节点
- InterPodAffinityPriority:pod亲和性选择策略,类似NodeAffinityPriority,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求),两个子策略:podAffinity和podAntiAffinity,后边会专门详解该策略
- MostRequestedPriority:动态伸缩集群环境比较适用,会优先调度pod到使用率最高的主机节点,这样在伸缩集群时,就会腾出空闲机器,从而进行停机处理。
已注册但默认不加载的Priorites策略有:
- EqualPriority
- ImageLocalityPriority
- MostRequestedPriority
PS:此外还有个ServiceSpreadingPriority策略(计划停用),由SelectorSpreadPriority替代
2 源码解析
scheduler在整个集群中负责pod的调度,对机器(node)进行筛选和过滤,选择最合适的机器运行pod。这部分组件是以插件的形式存在的,如果需要定制调度算法也是比较方便
scheduler是作为plugin放在k8s里面,代码在/plugin下面。代码结构如下:
├── cmd
│ └── kube-scheduler
│ ├── app
│ │ └── server.go
│ └── scheduler.go
└── pkg
└── scheduler
├── algorithm
...还是按照一贯的风格, main函数在plugin/cmd目录下面, 新建app.NewSchedulerServer(),解析命令行参数,执行Run函数。
在Run这个接口,首先是生成masterClient的配置, 因为配置指定会有多种方式,因此需要进行合并,规则如下:
- 启动的时候通过kubeconfig显示(ExplicitPath)指定, 优先级最高,其次是Precedence字段指定的其他文件,优先级以此降低,也就是先解析的配置覆盖后面解析的配置项,但是如果遇到新的配置项,就会被加入。
- ClusterInfo: clientcmdapi.Cluster{Server: s.Master} 指定 api-server(master)的信息,这里会覆盖前面文件指定的集群信息
- .kubeconfig 文件,如果解析到相对路径,就会以.kubeconfig的父文件夹为父路径,合并成绝对路径
合并完配置, 新建一个RESTClient,
kubeClient, err := client.New(kubeconfig)
...
configFactory := factory.NewConfigFactory(kubeClient, util.NewTokenBucketRateLimiter(s.BindPodsQPS, s.BindPodsBurst))
config, err := s.createConfig(configFactory)
createConfig会依次,直到调用
- CreateFromConfig
- CreateFromProvider
- CreateFromKeys
来决策对应的调度算法,默认情况下使用CreateFromProvider, providerName是AlgorithmProvider: factory.DefaultProvider, 也就是DefaultProvider调度算法,然后调用CreateFromKeys,通过getFitPredicateFunctions获得对应的调度算法。 那这个算法provider是什么时候注册进去的呢?
在./plugin/pkg/scheduler/algorithmprovider/defaults/defaults.go的init可以看到
factory.RegisterAlgorithmProvider(factory.DefaultProvider, defaultPredicates(), defaultPriorities())
在这里进行了实际的注册,其中
- defaultPredicates 主要进行过滤
- PodFitsHostPorts 过滤端口冲突的机器
- PodFitsResources 判断是否有足够的资源
- NoDiskConflict 没有挂载点冲突
- MatchNodeSelector 指定相同标签的node调度
- HostName 指定机器调度
- defaultPriorities 主要进行筛选
- LeastRequestedPriority : 使用公式cpu((capacity - sum(requested)) * 10 / capacity) + memory((capacity - sum(requested)) * 10 / capacity) / 2 来计算node的score
- BalancedResourceAllocation : score = 10 - abs(cpuFraction-memoryFraction)*10,cpuFraction是已经分配的除以整机的CPU比例,也就是说资源碎片越小得分越低,表示分配更“均衡”
- SelectorSpreadPriority 降低聚集度,尽量的降低同一个service或者rc上的pods的数目,也就是在predicate的时候尽量的降低冲突的概率
每个步骤的得分进行相加,最后选出最高得分的机器,如果有多个相同得分的机器, 就从中随机选择一个。 作为pod的调度目标机器。
algo :=scheduler.NewGenericScheduler(predicateFuncs, priorityConfigs, f.PodLister, r)
创建GenericScheduler,使用筛选和过滤的函数
func NewGenericScheduler(predicates map[string]algorithm.FitPredicate, prioritizers []algorithm.PriorityConfig, pods algorithm.PodLister, random *rand.Rand) algorithm.ScheduleAlgorithm {
return &genericScheduler{
predicates: predicates,
prioritizers: prioritizers,
pods: pods,
random: random,
}
}
GenericScheduler类实现了ScheduleAlgorithm接口的Schedule方法,Scheduler方式直接选出分配到的机器
type ScheduleAlgorithm interface {
//选出machine
Schedule(*api.Pod, NodeLister) (selectedMachine string, err error)
}
回到创建配置文件的方法中:初始化scheduler.Config的NextPod接口,这里就是每次调度的数据源。最后返回scheduler.config,配置创建完成
// Creates a scheduler from a set of registered fit predicate keys and priority keys.
func (f *ConfigFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String) (*scheduler.Config, error) {
...
NextPod: func() *api.Pod {
pod := f.PodQueue.Pop().(*api.Pod)
glog.V(2).Infof("About to try and schedule pod %v", pod.Name)
return pod
},
...
}
然后新建新建一个事件广播器,同时监听对应的事件,并且通过EventSink将其存储,代码如下:
eventBroadcaster := record.NewBroadcaster()
config.Recorder = eventBroadcaster.NewRecorder(api.EventSource{Component: "scheduler"})
最后启动scheduler,此次的config就是上面创建的config
sched := scheduler.New(config)
sched.Run()
这里就会启动一个goroutine调用pkg/scheduler/scheduler.go文件的Run,也就是scheduleOne函数。
// Run begins watching and scheduling. It starts a goroutine and returns immediately.
func (s *Scheduler) Run() {
go util.Until(s.scheduleOne, 0, s.config.StopEverything)
}
// Until loops until stop channel is closed, running f every period.
// Catches any panics, and keeps going. f may not be invoked if
// stop channel is already closed. Pass NeverStop to Until if you
// don't want it stop.
func Until(f func(), period time.Duration, stopCh <-chan struct{}) {
for {
select {
case <-stopCh:
return
default:
}
func() {
defer HandleCrash()
f()
}()
time.Sleep(period)
}
}
func (s *Scheduler) scheduleOne() {
//首先获取调度的pod
pod := s.config.NextPod()
if s.config.BindPodsRateLimiter != nil {
//等待token变为可用状态
s.config.BindPodsRateLimiter.Accept()
}
glog.V(3).Infof("Attempting to schedule: %+v", pod)
start := time.Now()
defer func() {
metrics.E2eSchedulingLatency.Observe(metrics.SinceInMicroseconds(start))
}()
//进行实际调度,默认是调度算法是上面提到的DefaultProvider,也就是执行具体的调度算法
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInMicroseconds(start))
if err != nil {
glog.V(1).Infof("Failed to schedule: %+v", pod)
s.config.Recorder.Eventf(pod, "FailedScheduling", "%v", err)
s.config.Error(pod, err)
return
}
//将pod绑定到node
b := &api.Binding{
ObjectMeta: api.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name},
Target: api.ObjectReference{
Kind: "Node",
Name: dest,
},
}
// We want to add the pod to the model if and only if the bind succeeds,
// but we don't want to race with any deletions, which happen asynchronously.
s.config.Modeler.LockedAction(func() {
bindingStart := time.Now()
// 发送调度结果给master
err := s.config.Binder.Bind(b)
metrics.BindingLatency.Observe(metrics.SinceInMicroseconds(bindingStart))
if err != nil {
glog.V(1).Infof("Failed to bind pod: %+v", err)
s.config.Recorder.Eventf(pod, "FailedScheduling", "Binding rejected: %v", err)
s.config.Error(pod, err)
return
}
//记录一条调度信息
s.config.Recorder.Eventf(pod, "Scheduled", "Successfully assigned %v to %v", pod.Name, dest)
// tell the model to assume that this binding took effect.
assumed := *pod
assumed.Spec.NodeName = dest
//激活被调度的pod
s.config.Modeler.AssumePod(&assumed)
})
}
