
raft 经典场景分析

1. 基本概念
- Raft 是一种用来管理日志复制的一致性算法
- Raft 比 Paxos 更容易学会
- Raft提供一种一致性场景,就是客户端调用put(x) = y, 一旦写入成功,则x的值在raft集群存在且能提供服务的情况下,一定会返回get(x) = y(但并不保证在每台raft机器上都是get(x)=y)
- 一般的应用场景:
- WAL(write ahead log)大家都知道,其实也没那么高端,就是数据写入前先记一条日志,类似会计记账,某账户消费20,然后再去修改账户余额,这样在余额本丢了的情况下,就可以用账户消费本重新算余额本
- WAL只能保证数据在单台机器上不丢且一致,场景上来说还是十分单一的,而目前大部分的数据都是主备的背景下,异步同步的数据会长期存在不一致
- 主备同步写入是一个解决异步同步数据的好办法,但是这种方法IO等待太高了(考虑一主四,五备的场景)
2. 基础场景
2.1 角色
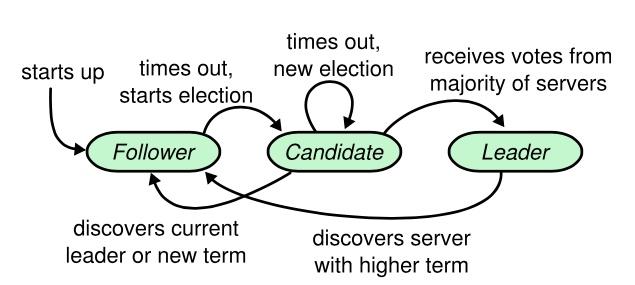
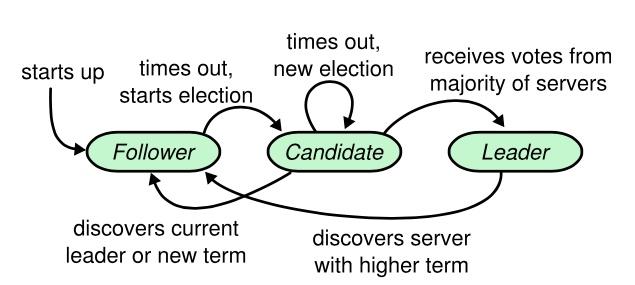
角色讲解,Raft一共分为三种角色,leader,follower,candidate,字面意思十分明了;
- leader为集群主节点,整个集群仅有一个leader节点可以存在
- follower为跟随节点,follower知晓自己的leader,并与leader通信
- candidate为follower无法联系上leader节点后转化而成,candidate的作用就是在自己无法联系上leader的情况下联系leader
- 几个角色的转换关系如下图,值得注意的几个点:
- 集群启动时,没有leader,而是全部初始化为 follower
- leader 只能退化为follower,原因显而易见,leader只会在发现有其他更高term(任期)的leader后退居二线(一般发生在脑裂合并的场景)
- 理解的时候可以把角色代入级别,follower,candidate,leader的升级序列,角色不会跨级别提升(和现实公司中 不能跨级别晋升很像,而且没有例外)
2.2 节点状态说明
根据协议,节点并不是无状态的,节点自身的状态是持久化且保存的(也就是重启后不会丢失),节点需要注意的状态中,比较重要的有:
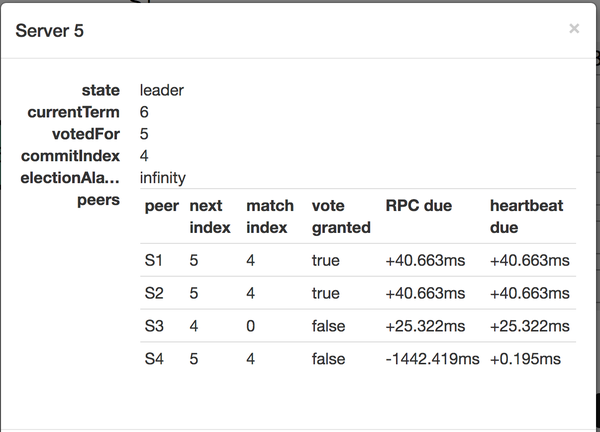

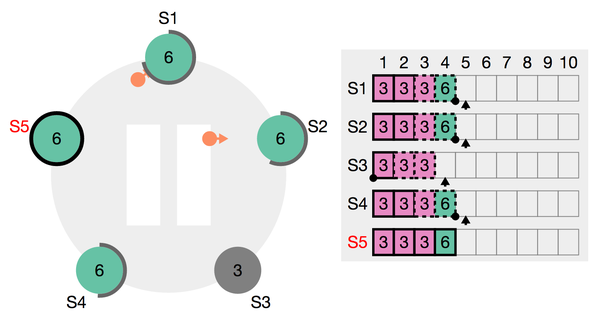
- 和选举有关的状态:server 5 处于 Leader的角色,且该leader的 termId = 6
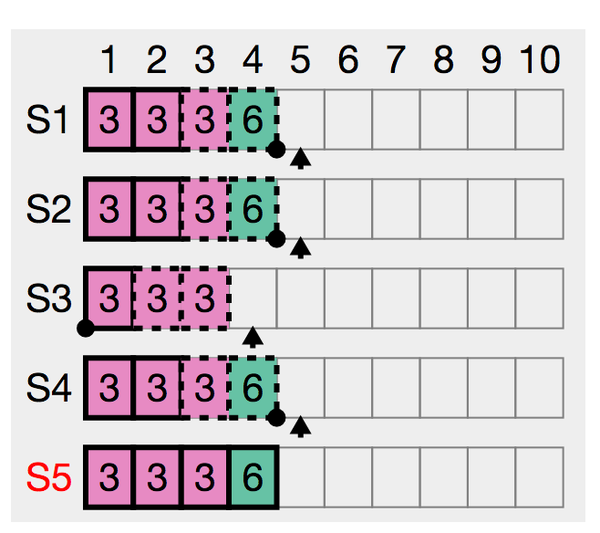
- 和日志复制有关的状态:已递交的日志index为4,下图为已递交的日志图示,其中S5的4为实现,代表已递交,虚线的为未递交

2.3 经典场景图示
2.3.1 初始化选举场景
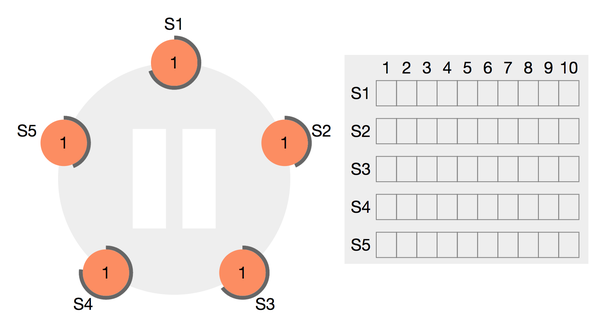

图1:初始化,所有follower都在等待成为candidate的场景
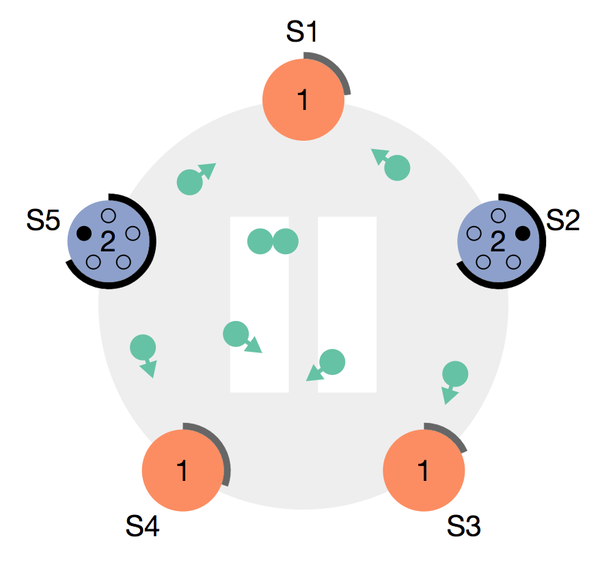

图2:两个follower先后成为candidate,并发出拉票的场景,注意term已经自动为2,表名candidate对任期,也就是term为自动+1,可以看出由于距离优势,s2的希望肯定更大
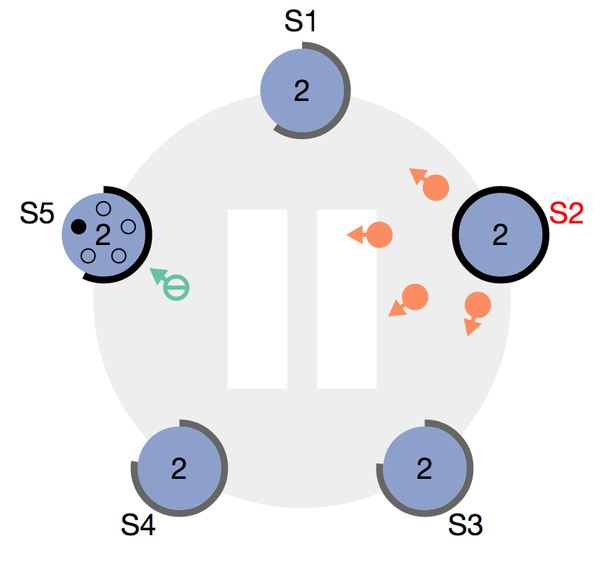

图3:由票选获得3张选票的场景(其中s5的唯一一张选票来自于自身)
初始化时,所有的node都处于follower,且在一段时间内都不成为candidate。为了防止有两个node会长期同时成为candidate且平分选票,导致长时间无法选主成功,这一段超时时间是随机的,这保证了不会出现多个candidate周期性的分散选票,选票一定会收敛。
2.3.2 log replicate场景
put(x) 或 get(x) 操作仅可以由leader发起,如果没有leader,则集群无法执行put或get。
log replication 分为两步,一步为prepare,先确定有多少节点可以成功写入,第二步为confirm,当然在用户端,这两步一起会封装为一个put(x)操作,仅当两步都成功才返回成功。
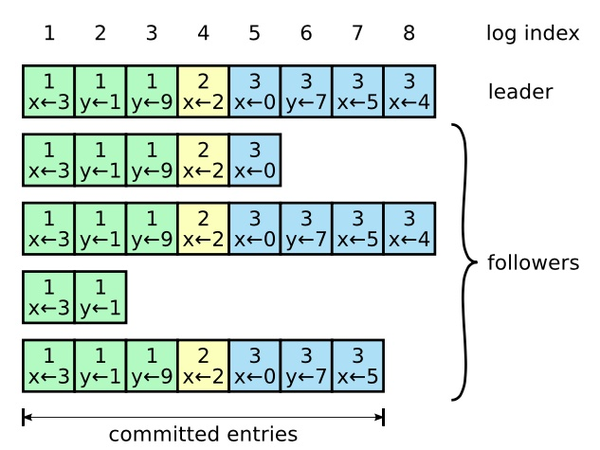
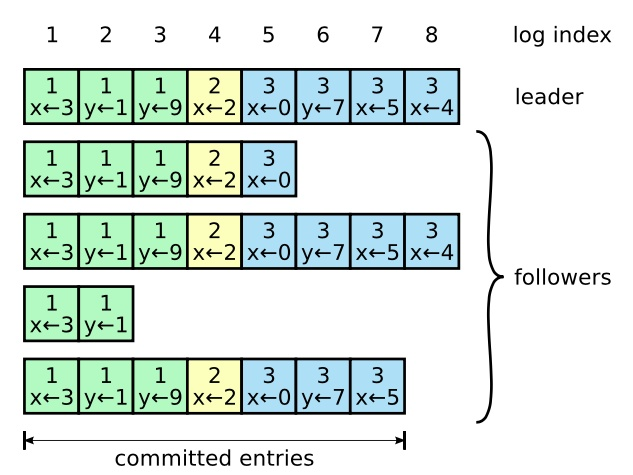
如图,日志复制snapshot, 这幅图中可以看出 1.至少有三台机器递交的才算递交成功, 2.日志可以落后,但绝不会出现中间不一致
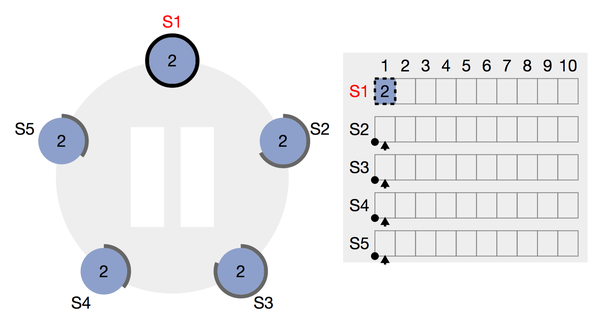

图1:request请求后在leader节点写入,此时leader节点为uncommited状态,put请求处于等待
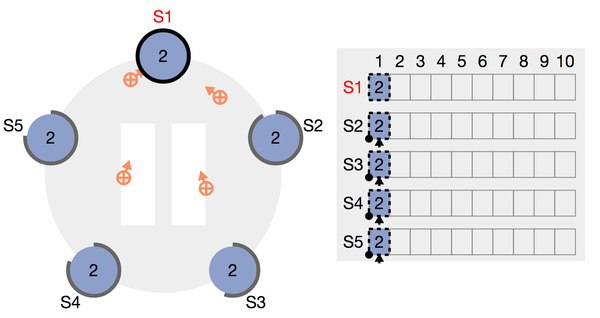

图2:由一次心跳后,子节点纷纷写入,由于心跳还没传回主节点,主节点为uncommitted状态,put请求仍在等待
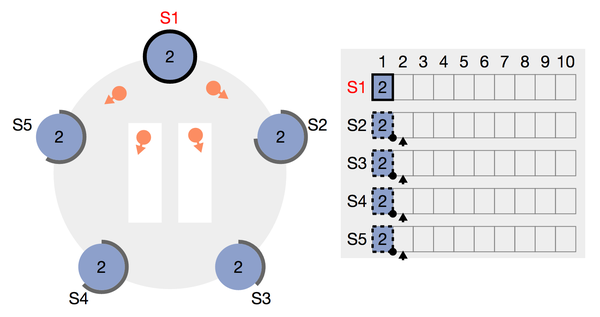

图3:RPC传回后,代表着prepared成功了,主节点发送commit请求给子节点,注意这个瞬间微妙的点在于,子节点虽然还没接受到committed信息,但子节点已经把记录写入到磁盘了,也就是处于重启不会丢弃的状态,put请求返回
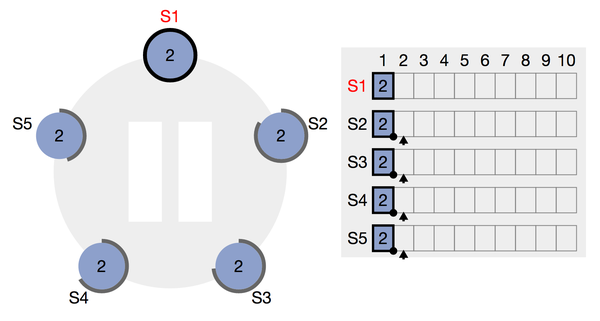

图4:在第二次心跳后,所有子节点都已知持久化状态
和日志复制机制有关的选举限制:
- 在一些一致性算法中,例如:Viewstamped Replication,即使一开始没有包含全部已提交的条目也可以被选为领导人。这些算法都有一些另外的机制来保证找到丢失的条目并将它们传输给新的领导人,这个过程要么在选举过程中完成,要么在选举之后立即开始。不幸的是,这种方式大大增加了复杂性。
- Raft 使用了一种更简单的方式来保证:也就是日志落后的候选人,无法被选中为Leader,这其实大大减小了选举和日志复制的相关性,简化了raft的算法理解难度。
和日志复制机制有关的原则:
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们之间的所有条目都是完全一样的。
这两个原则有助于在选举时减少不一样条目的检索和对比。
3.一个混合场景的讲解
在3中,会分析构造混合了leader election + log replication + fatal error的场景,有助于通过场景分析来深化理解raft协议:
3.1. 场景1,replication log落后的节点,无法获得leader权
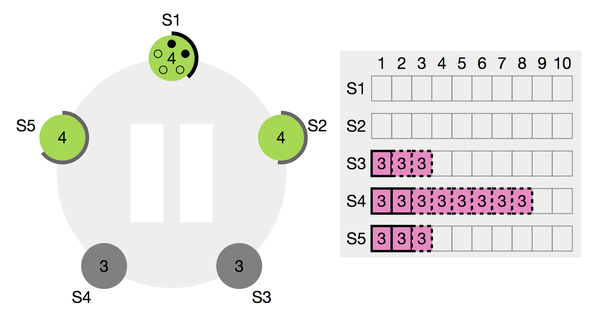

图1:在s3成为leader并写入多条log后,s3,s4挂掉,重新进行选主的场景(s1,s2是新加入的节点,在日志上落后)
如图所示,在这种场景下,由于节点s1,s2本地没有持久化任何日志,所以节点s1,s2无法获得s5的选票,所以s1或s2永远无法获得leader角色。这种场景下,s5最慢会在2*心跳时间获得leader权。
在s5获得leader后,会和s1,s2追平持久化的日志:
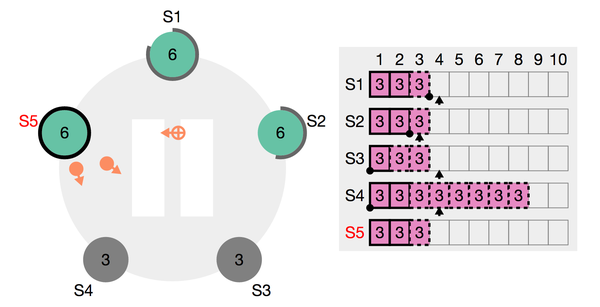

这个场景下,如果s4重新上线,则会变成如下:
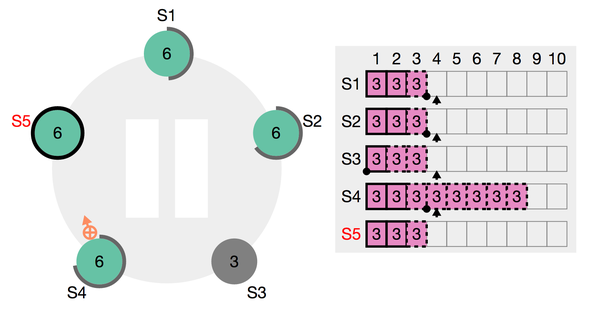

在对这个新集群进行一次append后,集群的日志变成如下:

该图示揭示了在找到最近一次索引相同的日志后,leader节点的committed log 覆盖了s4的uncommitted log
4. 资料推荐
raft一个非常友好的点,就是提供了一个可以自己模拟协议发生以及各种请求的前端开源项目,该项目就嵌入在raft协议介绍主页中,有兴趣的可以模仿一下:
Raft Consensus Algorithm另外,raft还有一个图文并茂,带有动画的介绍ppt,懒得长篇看文字的可以阅读下这个:
Raft相信在看完以上两个资料后,有一定基础的码农已经可以建立对raft的全方位理解了。
