
AFM: Learning the Weight of Feature Interactions via Attention Networks, IJCAI 2017

这是NUS的何向南博士基于Neural Attention Network改进FM的工作,发表在IJCAI’17上。通过attention网络学习组合特征的权重,改进了所有组合特征的权重都相同的传统FM方法,在两个数据集Frappe和MovieLens上以更少的模型参数,取得比SOTA方法(Wide & Deep Learning)更好的效果。
研究背景
FM算法本身通过引入二阶feature interactions来提高线性回归模型的泛化表达能力,但它以相同的权重来对所有的特征组合进行建模。事实上很多无用特征的组合会引入噪声从而影响效果。基于这个背景下,论文提出Attentional Factorization Machine(AFM),通过neural attention network来学习每个特征组合的重要性,从而discriminate不同特征组合的权重来提升FM。
AFM模型
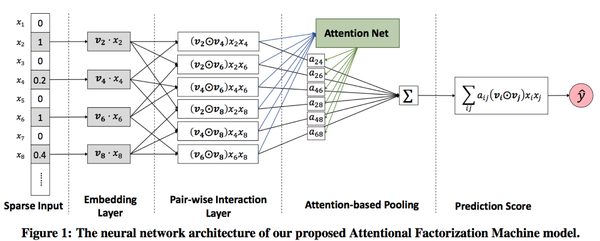

图1是整个AFM模型的框架。Input层和Embedding层和FM相同,采用稀疏表示作为特征输入,然后把每个非零特征嵌入稠密向量。AFM的主要贡献是后面两层:Pair-wise Interaction Layer和Attention-based Pooling。
Pair-wise Interaction Layer
FM采用内积来表达每对特征的组合,因此提出Pair-wise Interaction Layer,把m个向量扩展成m(m-1)/2个组合向量,每个组合向量都是两个不同(distinct)向量的element-wise product(这不就是inner product吗?)


用求和池化(sum pooling)对得到的 f_{PI}(\epsilon) 进行压缩,然后用一个全连接层来project到预测分数:
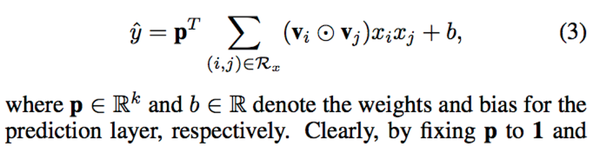

(注:把p置为1,b设为0,就得到原来的FM模型)
Attention-based Pooling Layer
Attention机制广泛应用在神经网络建模中,主要思想是在压缩不同部分到一个single representation时,允许不同部分贡献不同。结合FM同等权重地处理特征组合的缺陷,在特征组合上使用attention机制(加权求和):
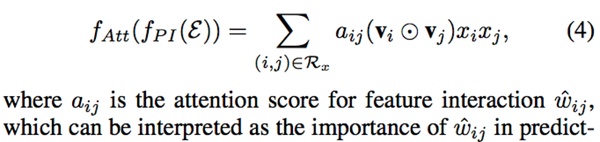

为了估计aij,可以通过最小化预测代价求得。但对于训练数据中没有共现过的特征们,它们组合的attention分数无法估计。因此论文进一步提出attention network,用多层感知器MLP来参数化attention分数。
Attention network的输入是两个特征的组合向量(在嵌入空间中编码了它们的组合信息),最后通过softmax函数来归一化attention分数。
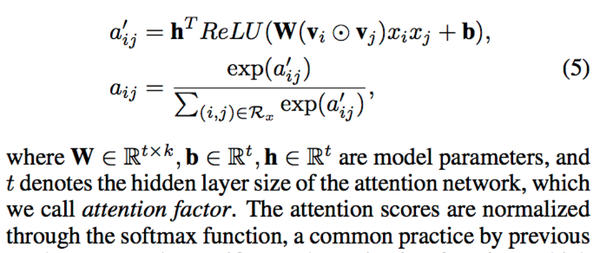

整个Attention-based Pooling Layer的输出是一个k维向量,区分不同特征组合的重要性地压缩所有特征组合到一个嵌入空间。最后project到预测分数:
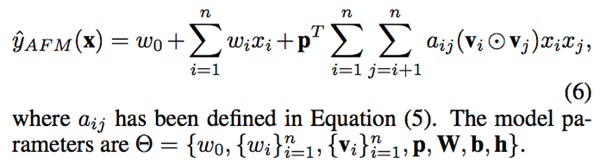

模型训练学习
AFM可以用于各种预测任务:回归、分类、排序,不同的任务决定用不同的目标函数来训练模型。对于回归,目标函数用平方误差函数。对于二分类或者带有隐式反馈的推荐任务,目标函数用logloss函数。优化目标函数采用SGD,关键在于求模型的导数,DL常用的工具包(theano或者tensorflow)都提供了自动求导的功能。
AFM比FM更容易过拟合,因此考虑dropout和L2正则化防止过拟合:
- 对于Pair-wise Interaction Layer使用dropout避免co-adaptation:AFM对所有特征组合进行建模,但不是所有的组合都有用,PIL的神经元容易彼此之间co-adapt,然后导致过拟合。
- 对于Attention network(一层MLP)加入权重矩阵W的L2正则化项阻止过拟合:这里不用dropout,实验发现PIL和AN同时用dropout带来问题性的问题,降低效果。
用求和池化(sum pooling)对得到的
f_{PI}(\epsilon)进行压缩,然后用一个全连接层来project到预测分数:
实验验证
数据集:Frappe,9万条app使用日志,常用于context-aware推荐,上下文变量都是类别变量,天气、城市、时间等。独热编码得到5382特征。MovieLens,66万电影的tag,用于标签推荐。UserID、movieID和tag转化得到90445特征。
评价指标:RMSE
对比baseline:LibFM、HOFM、W&D、DeepCross
总结
引入DNN中的Attention机制到FM模型。提出AFM通过用attention network学习特征组合的重要性,从而提升FM,不仅提升了特征表达能力,也提高了FM模型的可解释性。
个人看法
基于DNN和FM结合的改进论文已经很多了,光是IJCAI相关track就有三篇,本质上都是利用DNN的泛化能力解决FM高阶特征组合的表达能力问题,思路基本都是Google W&D模型的延续。同时,Attention机制在各种DNN中已经大量使用,和DNN以及FM结合做一个微创新也很自然想到,但并没有能给出一个相对insight的解释,为什么在推荐系统中用attention机制也有效果?印象中有长期依赖问题的RNN模型,引入attention机制可以有效改善效果已达成一定共识。
对于这篇论文,给特征组合学习权重的idea并不是一个很新的想法,加权最小二乘WLS、加权线性回归、加权SVM都是这类思想。我一直觉得像FM这类线性模型,学习的模型参数本质上就是体现特征的重要性程度,在学习之前就引入一个权重,是否多此一举呢?不能否认会让原来就重要的特征更加重要,原来无用的特征得到惩罚,的确能加强特征表达能力。但,能否在模型层面进行修正而达到这样的效果呢?
目前看来,用DNN改进FM的文章已经有点多了,AUC或者logloss等指标也已经越来越好。对于推荐系统而言,可以更加关注在线训练学习效率、系统工程实现等问题,这样才能将这些算法更好的落地应用。
