如何画XGBoost里面的决策树(decision tree)

最近用XGBoost很多, 训练完模型后, 一般只是看看特征重要性(feature importance score). 我对这种黑箱模型一般是不放心的, 所以喜欢把结果尽可能的画出来看看. XGBoost是一种Boosting Tree方法, 模型中每个决策树是可以画出来看看的. 以为这是个很简单问题, 后来发现其实坑还挺多的, 这里简单总结一下.
XGBoost有个plot_tree 函数, 训练好模型后, 直接调用这个函数就可以了:
from xgboost import XGBClassifier
from xgboost import plot_tree
import matplotlib.pyplot as plt
model = XGBClassifier()
model.fit(X, y)
plot_tree(model)
plt.show()可以得到类似下面这个的图, plot_tree有些参数可以调整, 比如num_trees=0表示画第一棵树, rankdir='LR'表示图片是从左到右(Left to Right). 图片来自这里.
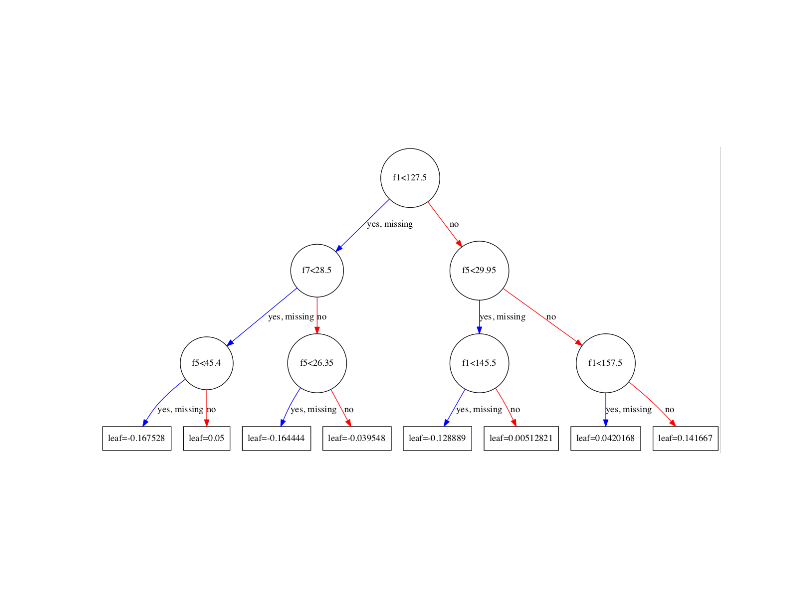
下面问题就来了:
1. f1,f2是feature ID, 我的变量名跑哪里去了? 怎么加上去?
2. 怎么调整图片大小? 我常用的plt.figure(figsize=(10,10))怎么不管用
3. 怎么改变图中字体大小? 字太小看着伤眼睛啊
4. 怎么把图存成pdf或者其它格式?
下面就一个个问题来解决.
如何改图中的feature ID? 这估计是XGBoost里面最大的一个坑了. XGBoost很多函数会用的一个参数fmap (也就是feature map),但是文档里面基本没解释这个fmap是怎么产生的. 花了九牛二虎之力之后, 发现Kaggle上有好心人提供了解决方案.
def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1
outfile.close()
ceate_feature_map(train_data.columns)这个函数就是根据给定的特征名字(我直接使用了数据的列名称), 按照特定格式生成一个xgb.fmap文件, 这个文件就是XGBoost文档里面多次提到的fmap, 注意使用的时候, 直接提供文件名, 比如fmap='xgb.fmap'.
有了fmap, 在调用plot_tree函数的时候, 直接指定fmap文件即可:
plot_tree(fmap='xgb.fmap')这里又有个坑. 虽然使用了fmap函数, 画出来的图仍然是feature ID. 我查看了一下本机上plot_tree函数, 发现并没有fmap这个参数. 去XGBoost github上看了一下相关的函数, fmap这个函数是存在的. 用pip把XGBoost重装一下, 问题仍然存在. 然后去github上下载了最新版本, 重新编译安装, 发现还是不行. 我猜测是本机已经有XGBoost而且版本号是最新的0.6(但有些函数其实在github上被更新了), 安装的时候发现版本号一样, 所以实际并没有覆盖老的版本. 所以尝试卸载老版本重新安装github版. 可是画图还是使用feature ID! 最后发现时import的问题, 需要使用reload重新import xgboost.
如何改变图中字体大小? 我发现XGBoost里面的tree如果超过3层, 基本字会很小, 很难看清楚. 所以想调大字体. 研究了很久XGBoost的源代码, 发现XGBoost是使用了graphviz做图, 可是XGBoost本身的wrapper只使用了graphviz里面的一个参数graph_attr, 还有另外两个参node_attr, edge_attr 都没有用到, 直接后果就是属于node_attr, edge_attr 的字体大小属性不能更改.
我索性把XGBoost的源码拷贝到我的程序, 然后做了相应的修改.
import re
_NODEPAT = re.compile(r'(\d+):\[(.+)\]')
_LEAFPAT = re.compile(r'(\d+):(leaf=.+)')
_EDGEPAT = re.compile(r'yes=(\d+),no=(\d+),missing=(\d+)')
_EDGEPAT2 = re.compile(r'yes=(\d+),no=(\d+)')
def _parse_node(graph, text):
"""parse dumped node"""
match = _NODEPAT.match(text)
if match is not None:
node = match.group(1)
graph.node(node, label=match.group(2), shape='plaintext')
return node
match = _LEAFPAT.match(text)
if match is not None:
node = match.group(1)
graph.node(node, label=match.group(2).replace('leaf=',''), shape='plaintext')
return node
raise ValueError('Unable to parse node: {0}'.format(text))
def _parse_edge(graph, node, text, yes_color='#0000FF', no_color='#FF0000'):
"""parse dumped edge"""
try:
match = _EDGEPAT.match(text)
if match is not None:
yes, no, missing = match.groups()
if yes == missing:
graph.edge(node, yes, label='yes, missing', color=yes_color)
graph.edge(node, no, label='no', color=no_color)
else:
graph.edge(node, yes, label='yes', color=yes_color)
graph.edge(node, no, label='no, missing', color=no_color)
return
except ValueError:
pass
match = _EDGEPAT2.match(text)
if match is not None:
yes, no = match.groups()
graph.edge(node, yes, label='yes', color=yes_color)
graph.edge(node, no, label='no', color=no_color)
return
raise ValueError('Unable to parse edge: {0}'.format(text))
from graphviz import Digraph
booster = xgboost_model.get_booster()
tree = booster.get_dump(fmap='xgb.fmap')[0]
tree = tree.split()
kwargs = {
#'label': 'A Fancy Graph',
'fontsize': '10',
#'fontcolor': 'white',
#'bgcolor': '#333333',
#'rankdir': 'BT'
}
kwargs = kwargs.copy()
#kwargs.update({'rankdir': rankdir})
graph = Digraph(format='pdf', node_attr=kwargs,edge_attr=kwargs,engine='dot')#,edge_attr=kwargs,graph_attr=kwargs,
#graph.attr(bgcolor='purple:pink', label='agraph', fontcolor='white')
yes_color='#0000FF'
no_color='#FF0000'
for i, text in enumerate(tree):
if text[0].isdigit():
node = _parse_node(graph, text)
else:
if i == 0:
# 1st string must be node
raise ValueError('Unable to parse given string as tree')
_parse_edge(graph, node, text, yes_color=yes_color,no_color=no_color)
graph.render('XGBoost_tree.pdf')
graph这里有几点要说明:
程序里面有几处shape='plaintext',在XGBoost源码里面是shape='circle'或者shape='box', 我改成shape='plaintext'是想是图更紧凑一些,这样看得更清楚. 不好的地方是, 圆圈大小代表了样本多少, 这也是很重要的信息. (有朋友留言提到这里圆圈大小并没有样本多少的信息, 我研究了一下XGBoost dump file, 自己试验了一下, 发现圆圈大小的确和样本大小无关, 只跟圆圈里面变量名长度有关系, 这里更正一下)
程序里面label=match.group(2).replace('leaf=','')是因为XGBoost原图的叶节点会有leaf=XXX, 我觉得很占空间, 所以也去掉了.
这里 tree = booster.get_dump(fmap='xgb.fmap')[0], fmap就是前面生成的fmap文件, [0]表示第一棵树, 如果你想要其他树, 修改这个数字即可.
这里graph = Digraph(format='pdf', node_attr=kwargs,edge_attr=kwargs,engine='dot')就是控制画图的主要参数, 格式是PDF,你可以改成PNG等. 这里的graph_attr, node_attr, edge_attr 分别控制图片不同部分的属性, 这里我修改了node和edge的字体大小. XGBoost源码里面只有graph_attr, 也就是说只能控制graph属性.
基本就这样了, 你可以直接复制我以上的程序使用. 看来有必要提交一个PR了.
