
【西瓜书】周志华《机器学习》学习笔记与习题探讨(一)续

旅游结束,发现知识记忆模糊了。
本篇将用西瓜书中的灵魂角色——西瓜,来对第一章的术语进行比喻性的解释,以作为【探讨(一)】的续篇。
一、基本概念
【模型】:从数据中得到的结果,如一棵判断什么是好瓜的决策树。
eg:(此为该决策树的一部分)
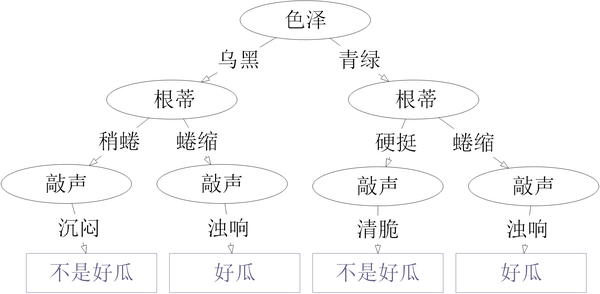

【模式】:局部性结果,如一条判断好瓜的规则
eg:色泽青绿、根蒂蜷缩、敲声浊响的是好瓜。
【学习算法】:在计算机上从数据中产生“模型”的算法。
二、数据相关
如图所示,假定我们收集了一批西瓜的数据。


【记录】:对任意一个西瓜的描述
eg:x1=(色泽=青绿;根蒂=蜷缩;敲声=浊响),x2=(色泽=乌黑;根蒂=稍蜷;敲声=沉闷),x3=(色泽=浅白;根蒂=硬挺;敲声=清脆),......
【示例、样本】:对一个西瓜的描述
eg:x1=(色泽=青绿;根蒂=蜷缩;敲声=浊响)
【数据集】:D={x1,x2,x3...xm} 一组记录的集合,一组“对西瓜的描述”的集合。(此为有m个示例的数据集,即有m个西瓜描述的集合。)
eg:D={x1=(色泽=青绿;根蒂=蜷缩;敲声=浊响),x2=(色泽=乌黑;根蒂=稍蜷;敲声=沉闷),x3=(色泽=浅白;根蒂=硬挺;敲声=清脆)...xm}
【属性、特征】: xid (i表示第i个样本,d表示有d个属性)
eg: xi1 :色泽, xi2 :根蒂, xi3 :敲声
【属性值】:(第一个样本的三个属性的属性值)
eg: x11 =青绿, x12 =蜷缩, x13 =浊响
【属性空间、样本空间、输入空间】:以西瓜的三种属性为三个坐标轴,建立坐标系得到的空间。(此图系在假设属性值为连续而非离散的基础上绘制)
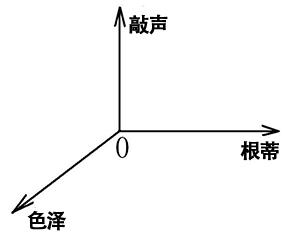
【特征向量】:西瓜的三个属性的属性值可以在属性空间坐标轴上找到属于自己的坐标,由此找到空间中符合三个属性值的一个坐标点。由于空间中每一个点对应一个坐标向量,故一个示例可以在d个属性围成的d维属性空间中表示成一个向量。


三、学习过程
【学习、训练】:从数据中学得模型的过程
eg:从西瓜样本数据集中得到判断好瓜的决策树的过程
【训练数据】:训练过程中使用的数据
eg:为得到判断好瓜的决策树,使用了100000个西瓜的三个属性值的记录集合训练样本集合,这3×100000个属性值就是训练过程中使用的数据
【训练样本】:每一个样本,即训练采用的对一个西瓜的描述
eg:x1=(色泽=青绿;根蒂=蜷缩;敲声=浊响)
【假设】:学得的判断好瓜的决策树对应了某种潜在的规律,(所以学得的模型,即判断好瓜的决策树,只是一种假设)
【真相、真实】:判断好瓜决策树对应的“客观上判断好瓜的规律”(可能与学习得到的判断好瓜决策树有出入)
【学习过程】:找出或逼近真相,即让学习出来的“判断好瓜的决策树”(假设),能够更加接近现实世界中判断好瓜的客观规律。(所以有时也将模型称为学习器,看做学习算法在给定数据和参数空间上的实例化。)
四、监督学习的预测原理
但是只有瓜的属性值,而没有关于瓜好坏的最终结果,是没有办法进行监督学习的。
这意味着,每当探测一个瓜的色泽、根蒂、敲声之后,还需要把瓜切开吃一口,给出这个瓜是好是坏的最终结论。这样才能积累到判断瓜好坏的经验。只观察不检验,是无法积累经验的。
(这是否意味着监督学习某种意义上是机器进行的经验积累?)
【预测】:依靠机器学习得到的模型(如决策树),对新示例进行结果判断。
eg:通过好瓜决策树,判断老婆新买的瓜是否是好瓜。
【标记】:关于示例(对一个西瓜的描述)得到的结果的信息
eg:好瓜、坏瓜
【样例】:拥有了标记信息的示例(对一个西瓜的描述),即(xi,yi),其中i表示第i个样例
eg:(x1,y1)=((色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜)
【标记空间、输出空间】:所有标记的集合。
当标记值是离散值的时候,Y={y1,y2,y3,...yj,...yn}(此时y的序号j并不代表第几个样例,而代表标记的第几个取值,n表示标记可以取n个值)在好瓜与坏瓜的问题上,n=2,即标记可以取两个值。
eg:Y={好瓜,坏瓜}
当标记值是连续值的时候,Y={yi=f(xi)}(此时yi则代表在取序号为i的示例xi时,标记的取值示例xi做自变量的函数f(xi)),如对西瓜的色泽、根蒂、敲声进行量化的统计,则可归纳出某种函数f(xi),用以表达西瓜的成熟程度值,从而判断西瓜的好坏。
故如上可知:
【分类】:预测的是离散值。
eg:判断瓜的好坏。
【回归】:预测的是连续值。
eg:判断瓜的成熟度。
【正类】eg:好瓜。【负类】eg:坏瓜。
【多分类】eg:沙瓤瓜、水瓤瓜、半沙半水瓤瓜。。。。
【测试】:预测的过程。
eg:“通过好瓜决策树,判断老婆新买的瓜是否是好瓜”的过程。
【测试样本】:被预测的样本。
eg:老婆买回来的瓜的属性的描述。
五、无监督学习的原理
【聚类】:将训练集中的瓜分为若干组。
eg:将训练决策树时所用的100000个西瓜分为:本地瓜、北方瓜、南方瓜、进口瓜等。
【簇】:每组称为一个簇。
eg:本地瓜、北方瓜、南方瓜、进口瓜,是四个簇。
注意:这些簇,并非主动划分,而是自动划分。也就是说,无监督学习只负责分类,不负责解释每个类是什么。意思是,这100000个瓜,被无监督学习分为了四类。分好之后,我一看,发现它分的第一类是本地瓜,第二类是北方瓜,第三类是南方瓜,第四类是进口瓜。
但是,还有可能分的这四类是:深色瓜、较深色瓜、较浅色瓜、浅色瓜。
簇的含义是在分类后得知的。
当然,我当然可以说我就要让它按地域给我分出这四类来。
只不过结果却有可能是按颜色分了四类。
那么无监督学习如何分出好瓜和坏瓜?
理论上就需要调整一系列参数,让聚类算法可以刚好将好瓜和坏瓜通过聚类区分为两类。
六、机器学习的目标
机器学习的目标是使学得的模型可以更好的适用于“新样本”,这和学习的过程——“找出或逼近真相”的目标一致。
【泛化】:学得模型适用于新样本的能力。
泛化能力一定程度上体现出假设与真相之间的差距。
假设样本空间的全体样本服从一个未知分布Ɗ。


一般而言,训练样本越多,得到关于D的信息就越多,越有可能通过学习获得强泛化能力的模型。
七、假设空间(结合三看)
【假设空间】:机器学习中所有的假设组成的空间。
eg:每一种假设代表着一种判断是否为好瓜的决策树。
假设空间就是这群决策树组成的空间。
【学习过程2】:前面提到学习过程是:
找出或逼近真相,即让学习出来的“判断好瓜的决策树”(假设),能够更加接近现实世界中判断好瓜的客观规律。
但如果众多假设形成了假设空间,则逼近真相的好方法,就是在假设空间中,对所有假设进行搜索,找到与训练集匹配的假设,则其会最为逼近真相。
【版本空间】:当找到的与训练集匹配的集合很多时,将这些假设另外组成一个集合,就是版本空间了。
eg:判断好瓜,一共有100棵决策树,这100棵决策树组成了一个假设空间。学习的过程是在这100棵决策树组成的假设空间中,通过搜索找到与这100000个瓜的好坏相匹配的决策树,从而逼近真相。经过搜索,能够匹配这100000个瓜的决策树只有10棵。故这10棵决策树的集合就是一个版本空间。
这次通过更具体的例子,应该让西瓜书中描述的机器学习的基本原理更加清晰了,如果有什么错误之处,欢迎各位及时指正,我会尽快作出说明修改。
西瓜书系列合集:
