
论文篇:Matrix Factorization Techniques for RS

首次看本专栏文章的小伙建议先看一下介绍专栏结构的这篇文章:专栏文章分类及各类内容简介。
【注:由于字数受限,题目中的RS代表Recommender Systems】
本篇文章介绍一篇在推荐系统领域里非常经典、频繁被引用的论文:Matrix Factorization Techniques for Recommender Systems 。该论文于2009年发表在IEEE下的“COMPUTER”期刊上,是推荐系统领域第一篇比较正式、全面介绍融合了机器学习技术的矩阵分解算法,对于近几年基于矩阵分解的推荐算法的研究起到了非常大的影响,一作是雅虎的研究人员Y.Koren。虽然该篇论文在推荐系统领域有着很重大的影响,但是论文所介绍的核心算法无论是在理论理解还是编程实现上都是比较容易的,这也符合“一个好的数学模型一定是简单的”的原则,所以在本专栏的第一篇论文篇文章中,笔者选择这篇文章进行讲解。
本文所需基础知识
随机梯度下降(后面会有介绍梯度下降的专题文章,敬请期待);矩阵运算、矩阵求导;特征值与特征向量的概念与求法;求偏导运算;推荐系统中的冷启动现象
特征分解与奇异值分解
在正式开始本文之前先来简要介绍一下在线性代数中的两种很常见的矩阵分解算法:特征分解和奇异值分解。
特征分解又称谱分解,其原理来源于线性代数中的相似矩阵变换,是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。需要注意只有对可对角化矩阵(即可以通过相似变换变为对角矩阵的矩阵)才可以施以特征分解。分解公式如下所示:


我们发现特征分解的前提条件是待分解矩阵必须是可对角化的方阵,然而在实际应用中我们大多数用来进行操作的矩阵都是非方阵,所以特征分解本身用途并不广,那么如果我们想把非方阵的矩阵分解要用什么方法呢?于是后来就有了奇异值分解(SVD)法。
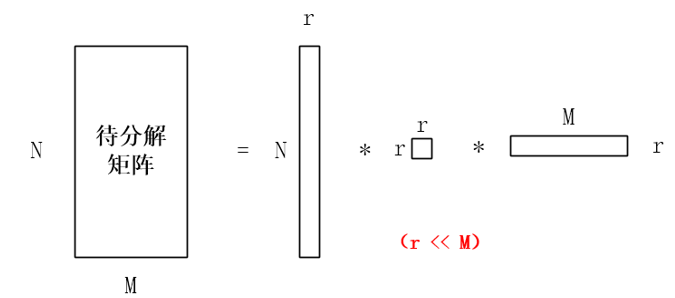
假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),VT(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),下图反映了待分解的矩阵和分解出来的矩阵之间的大小关系:


不过一般进行矩阵分解的时候我们都希望通过分解来把一个大矩阵压缩为三个小矩阵以减少时空上的开销,可是从上图中并没有看出SVD起到什么压缩的作用,那“压缩版”的SVD是否可行呢?我们先看一个普通的矩阵以及它对应的奇异对角矩阵:


我们可以看到矩阵的奇异值从大到小的衰减速度是非常快的,第一个奇异值就占了所有奇异值综合的93%。所以我们完全可以用第一个奇异值去代替全部的奇异值,这个方法可以扩展到非常大的矩阵SVD中,比如用前10个奇异值去代替全部的1000个奇异值,这样就可以大幅度压缩原矩阵。“压缩版”的SVD分解示意图如下图所示:

推荐系统中的常见的三大算法及各自优缺点
下面开始介绍本文的主要部分。推荐系统的研究从上世纪90年代初发展至今,目前有三大主流算法作为几乎全部的推荐算法的基石,它们就是基于内容的过滤算法(content-based filtering,简称CBF)、邻域算法(neighborhood methods)、隐语义模型(latent factor
models,简称LFM),其中后两者统称为协同过滤算法(collaborative filtering,简CF)。下面是三者的关系示意图:
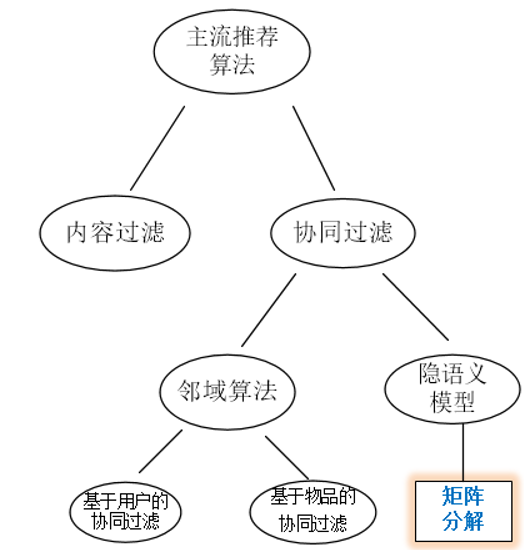
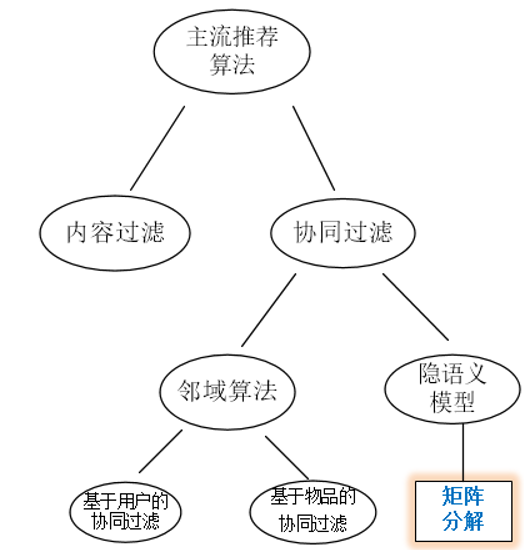
CBF通过给用户、物品定义显式的属性(通常会找所涉及的推荐领域的人类专家来定义)来描述他们的本质,然后为用户推荐与他们本质“门当户对”的物品;CF则是通过发动“群体的力量”,从其他用户、物品中学习到宝贵的信息,无需显式地定义属性:CF下的邻域算法着重于学习用户与用户、物品与物品之间的关系,为目标用户推荐与目标用户相似的用户所选择的物品(user-based)或者与目标用户所选择的物品相似的物品(item-based);CF下的隐语义模型则是通过学习用户与用户、物品与物品之间的关系来自动获得用户、物品的隐属性(这里的“隐”指的是学习到的属性是不可解释的),相当于把用户-评分矩阵分解成用户隐属性矩阵和物品隐属性矩阵,然后通过用户隐属性向量u与物品隐属性向量i作点乘来获取到该用户对该物品的评分,以此为依据进行推荐。下面的表格列出了三种主流方法优缺点:


矩阵分解的主要思想
如前面的图所示,矩阵分解是构建隐语义模型的主要方法,即通过把整理、提取好的“用户—物品”评分矩阵进行分解,来得到一个用户隐向量矩阵和一个物品隐向量矩阵。假设现在有一个M * N的矩阵,M代表用户数,N代表物品数,想将用户、物品分别训练出两个隐属性,即每个用户、每个物品都对应着一个二维向量,即得到了一个M * 2的用户隐向量矩阵和一个N * 2 的矩阵,分解示意图如下所示:


在得到用户隐向量和物品隐向量(均是2维向量)之后,我们可以将每个用户、物品对应的二维隐向量看作是一个坐标,将其画在坐标轴上。虽然我们得到的是不可解释的隐向量,但是可以为其赋予一定的意义来帮助我们理解这个分解结果。比如我们把用户、物品的2维的隐向量赋予严肃文学(Serious)vs.消遣文学(Escapist)、针对男性(Geared towards males)vs.针对女性(Geared towards females),那么可以形成论文中那样的可视化图片:
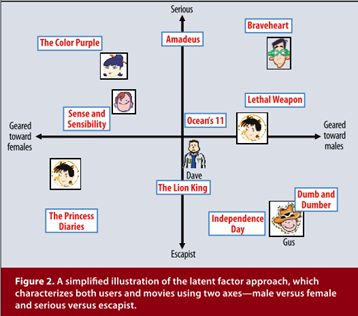
从上图我们可以看到,用户对于与其处于同一象限的物品的喜爱度/评分是会很高的,因为他们相比于其它的组合更加“门当户对”一些。而实例人物Dave对应的坐标恰好处于坐标系的中央,这说明他对图中所有物品的喜爱程度差不多,没有特别喜欢的也没有特别讨厌的。
矩阵分解中的显式反馈与隐式反馈
推荐系统、推荐算法的设计依赖于多种输入。在上部分中,我们针对用户—物品评分矩阵来对其进行分解,得到了两个隐向量矩阵。这里我们用到的输入就是这个评分矩阵。在推荐系统中,用户的评分信息输入最重要的输入信息,也是一种显式反馈。不过,显式反馈的信息往往是很稀有的,也就是说我们要分解的评分矩阵往往是一个很稀疏的矩阵,可能里面70%以上的元素都是0,只有30%的部分是稀稀落落的评分,所以单纯地依赖显式反馈信息在如今会得到正确率较低的推荐结果。不过矩阵分解的好处在于,它可以融入多种额外的信息。用户的购买、浏览、点击行为虽然不如评分那样有着很大的信息量,但是也是一种隐式反馈的信息,利用好它们,我们可以组成一个很稠密的矩阵,以此来改良推荐结果。本篇文章不介绍融合隐式反馈信息的矩阵分解,后续会有专门的文章来介绍。
矩阵分解过程
开始本文的最重要的部分:介绍矩阵分解的过程以及参数训练的方法,并且会在介绍中间插入具体的实现代码,代码是笔者自己手工编写的,运行结果目前是正确的,不过可能有些地方不太符合编程规范(Python:3.6,numpy:1.11.3,matplotlib:2.0.0),全部的代码在Github上:代码在这里~
接下来,先把之后需要用到的全部的数学符号或者缩略语都统一列到下表中:

如前面所介绍的,矩阵分解可以融入多种额外信息,不断地对待分解矩阵进行升级、改良,按照论文中所介绍的,整体的矩阵分解框架如下图所示:


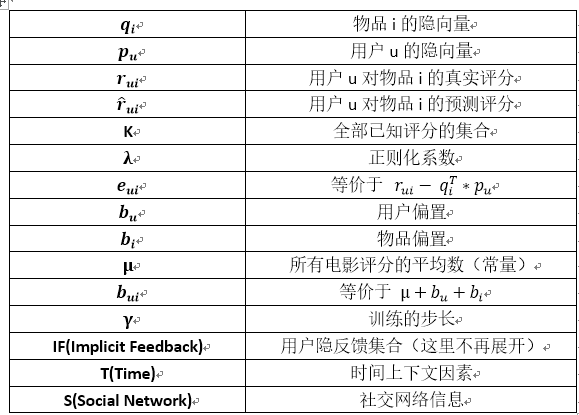
我们首先看一下没有融合额外信息的时候,是如何来预测评分的:
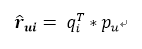
可以看出,其实很简单的。当我们要预测u对i评分的时候,就直接把对应的用户隐向量、物品隐向量直接点乘起来就好了,就得到预测的评分了。但是这两个矩阵是怎么来的呢?当然是训练出来的啦,我们要通过优化下面这个目标函数来训练出这两个矩阵,这就是标准的“机器学习版”的矩阵分解算法,也是推荐系统领域非常重要的算法:
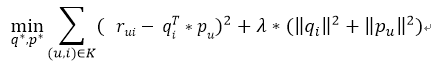

按照论文中所述,我们采用随机梯度下降(SGD)算法来训练两个隐向量矩阵:

整个SGD的函数代码如下所示:
def sgd(data_matrix, user, item, alpha, lam, iter_num):
for j in range(iter_num):
for u in range(data_matrix.shape[0]):
for i in range(data_matrix.shape[1]):
if data_matrix[u][i] != 0:
e_ui = data_matrix[u][i] - sum(user[u,:] * item[i,:])
user[u,:] += alpha * (e_ui * item[i,:] - lam * user[u,:])
item[i,:] += alpha * (e_ui * user[u,:] - lam * item[i,:])
return user, item这样我们就训练出了两个隐向量矩阵,将他们相乘便得到了预测版的评分矩阵,可以和真实评分矩阵对比一下,如果训练的次数足够,训练步长不大的话其实预测的评分已经比较准了。
但是,有一个问题我们需要考虑一下。如果有的用户比较苛刻,对他来说,烂片最多打1分,好的片子也就得3-4分,有的用户比较宽容,他认为人家拍个电影挺不容易的,烂片也给了3分,好的片子一律给5分,那对于这两种用户,我们要采取同样的对待方式进行预测吗?如果有的电影拍的真心好,普遍评分都很高,有的电影烂出了新高度,基本上上3分那都是绝对的高分了,那这两种电影真的都处于0-5分这一分段吗?
在这种情况下,我们其实需要为每个用户和每个物品加入一些偏置元素bu和bi,代表了他们自带的与其他事物无关的属性,融入了这些元素,才能区别且正确地对待每一个用户和每一个物品,才能在预测中显得更加个性化。所以,预测评分的计算公式就变成了这样:
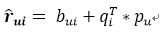
我们要优化、训练参数的目标公式也就变成了下图所示,要训练的参数除了用户、物品隐向量还要加上用户、物品偏置值,训练的方法同样是采用随机梯度下降法:
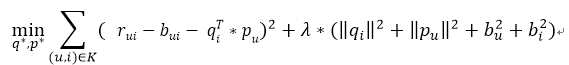

整个SGD_bias的函数的代码如下所示:
def sgd_bias(data_matrix, user, item, alpha, lam, iter_num, miu):
b_u = [1] * rating_matrix.shape[0]
b_i = [1] * rating_matrix.shape[1]
for j in range(iter_num):
for u in range(data_matrix.shape[0]):
for i in range(data_matrix.shape[1]):
if data_matrix[u][i] != 0:
b_ui = b_u[u] + b_i[i] + miu
e_ui = data_matrix[u][i] - b_ui - sum(user[u,:] * item[i,:])
user[u,:] += alpha * (e_ui * item[i,:] - lam * user[u,:])
item[i,:] += alpha * (e_ui * user[u,:] - lam * item[i,:])
b_u[u] += alpha * (e_ui - lam * b_u[u])
b_i[i] += alpha * (e_ui - lam * b_i[i])
return user, item, b_u, b_i在加入偏置后,预测的就更加准确一些了。在编程实验中,笔者采用了推荐系统算法常见的评测标准——MSE来进行两种分解算法的评测,两者的结果如下所示(注:训练步长0.001,正则化系数0.1,训练次数:1000次):


可以看到,效果的提升幅度还是很大的。
在实验中,笔者也采用了可视化的方法将用户、物品的隐向量画在了二维坐标图中,如下图所示(其中,蓝色的点代表物品的隐向量坐标、黄色的点代表用户的隐向量坐标),如果想预测某一评分(u, i),直接用黄点坐标点乘蓝点坐标即可:
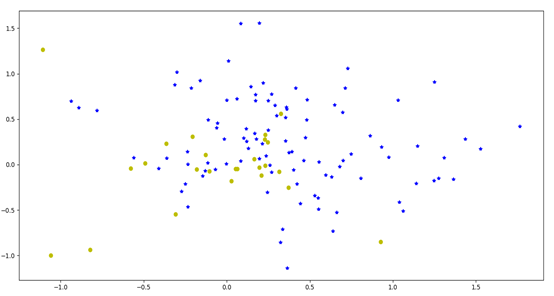

关于后三种的融合信息,由于暂时训练数据,本文就不再涉及了。
总结
本文讲解了推荐系统领域非常著名的一篇介绍矩阵分解的论文。矩阵分解算法和邻域算法、内容过滤算法是推荐系统领域的三大主流算法,但是矩阵分解算法相比于前两者来说,更好地考虑了用户和物品之间的交互信息,具有线下进行、推荐准确率稳定等优点,然而,作为协同过滤算法的一种,它也会遇到冷启动的问题。不过,矩阵分解算法具有的融合多种信息的特点也让算法设计者可以从隐式反馈、社交网络、评论文本、时间因素等多方面来弥补显示反馈信息不足造成的缺陷,在2009年之后到如今,全世界范围内仍然有很多学者在研究如何改良矩阵分解算法、更恰当巧妙地融入多种信息来提高推荐的准确率并赋予完善的推荐解释性能,在本专栏的后序的论文篇文章中,笔者会继续介绍近几年融合了评论文本挖掘算法的矩阵分解算法,我们一起来看看融入了评论信息,推荐的准确率和可解释性会得到多大的提升~
