PolarDB-X 的诞生和发展

关系数据库起源
数据库系统是一个历史悠久却又生机勃勃的领域,1970s Edgar F. Codd 提出关系模型,随后有了 IBM System R 关系数据库原型的故事。1974~1979年,System R 引入 SQL 关系语法、Access Path 来描述索引、回表等、Join Method 等概念( Index Join 和 Sort Join 的实现),在用户管理上有了 Grant、View 等运维命令,数据库的宕机恢复、事务 Lock 机制基本已经成型,除此以外在系统层面已经在考虑平衡生成 Codegen 的 CPU 开销和带来的加速,有了分层的 B 树做存储和索引的概念。经过一段时间的发展后,关系数据库架构基本就成型了,核心就是 Query 和 Storage。


参考论文:《A History and Evaluation of System R》、《Architecture of a Database System》
NoSQL & NewSQL
2000 年后,伴随互联网的兴起,数据规模也在急速膨胀,传统的单机数据库在扩展性上受到了极大的挑战。为解决扩展性问题,数据库系统在多个方向上进行了探索,新型架构和产品也如雨后春笋,层出不穷。早期阶段出现了以牺牲事务、SQL 等特性换取极致扩展性的 NoSQL 系统,比如 Bigtable、Hbase、Cassandra、MongoDB 等。之后在一段时间的探索后,业界普遍认识到了 SQL、事务等的不可或缺性,2012 年 Google Spanner 论文的发表,让大家看到了不一样的分布式+数据库的工程实现。在这之后的几年中,NewSQL 概念逐步进入大家的视野。
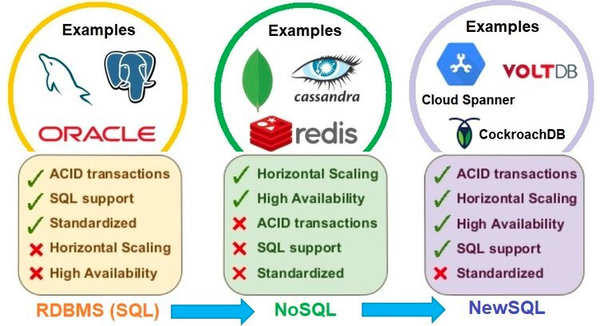

NewSQL发展
经过了10来年的发展,当前分布式数据库可以分为三个技术方向,一是以 DRDS、TDSQL 等为代表的 Sharding 技术,其最大的优势在于继承了 MySQL 存储多年的的技术积累,其稳定性可以很好满足大 B 用户的诉求;二是以 Cockroach/YugabyteDB/TiDB 为代表的 NewSQL,最大的优势在于全自研的技术栈,提供了水平伸缩和原生分布式的能力,重点以 Raft/Paxos 数据高可用、分布式强一致事务为典型技术,满足用户对于分布式下数据一致性的要求;三是以 PolarDB/Aurora 为代表的云原生 DB,特点是基于云的虚拟化的技术,提供资源池化的能力,重点以新的 RDMA 硬件 + 存储计算分离的模式,在数据库的数据库秒级备份、极速弹性、按需付费有创新的技术突破,满足用户低成本和高性能的使用要求。(ps. 有兴趣的可以看下论文《What’s Really New with NewSQL?》)。
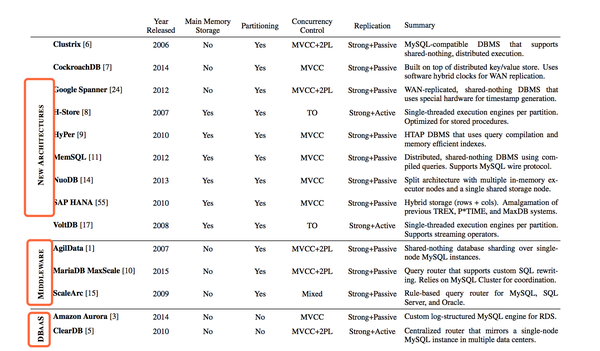

回首和展望
回顾这段历史我们可以看到,当前主流单机或分布式数据库依然沿用了 40 年前 System R 的模型和设计,Codegen、Paxos、MVCC 等很多主流技术在 80、90 年代就已经有了比较好的理论基础和技术沉淀,面对新兴场景的扩展性需求,采用分布式技术的三个新的探索方向还未成定局。一方面,分布式技术可以有效的解决扩展性问题,并降低系统成本,所以是一个非常有潜力的方向;另一方面,正如 Fred Brooks 所说,No Silver Bullet,分布式更多是帮助用户解决单机解决不了的扩展性,而不是纯定位为替换单机数据库。在小规模数据下,分布式数据库反而会增加更多的成本和运维负担。
目前分布式数据库方向还未形成明确的行业标准,单机数据库生态依然非常繁荣,所以如何在解决扩展性问题的同时,支持从单机到分布式的平滑过渡,成为实际业务系统中同样关注的能力,另外如何构建生态,实现单机数据库生态向分布式的扩展或演进,成为分布式方向能否走的更远的关键。
PolarDB-X 的发展史
2003 年淘宝网成立之初采用的是经典的 LAMP 架构,随着用户量迅速增长,单机 MySQL 数据库很快便无法满足数据存储需求,之后淘宝网进行了架构升级,数据库改用 Oracle。随着用户量的继续快速增长,Oracle 数据库也开始成批成批的增加,即使这样,仍然没有满足业务对数据库扩展性的诉求,所以阿里巴巴内部在 2009 年时发起了著名的去 IOE 运动,PolarDB-X 也开启了自己的演进之路。


PolarDB-X 0.5 时代
去 IOE 的关键一环是实现对 Oracle 的替换,当时淘宝的业务体量已很难用成熟的技术产品支撑,为了避免以后出现卡脖子情况,技术的自力更生和自主可控成为一个核心诉求。一方面,随着 x86 技术日趋成熟,稳定性与小型机的差距不断缩小,另一方面,MySQL 采用轻量化线程模型并具备高并发的支持能力,其生态逐步完善,因此新方案采用了基于 Sharding 技术 + 开源 MySQL 的分布式架构( TDDL + AliSQL ),我们称为 PolarDB-X 0.5 版本时代。这代产品的特征是以解决扩展性为目标、面向系统架构使用,尚不具备产品化能力。
PolarDB-X 1.0 时代
随着这套架构的逐渐成熟,14 年开始,我们基于阿里云走上了云数据库发展之路。作为分库分表技术的开创者,我们推出了 DRDS + RDS 的分布式云数据库服务,我们称为 PolarDB-X 1.0 时代。这代产品的特征是采用 Share-Nothing 架构、以解决存储扩展性为出发点、提供面向用户的产品化交付能力。1.0 版本是国内第一家落地分布式技术的云服务,成为云市场上分布式数据库技术方向的开创者和引领者。
针对用户使用中的痛点,我们不断进行产品能力迭代,陆续支持了分布式事务、全局二级索引、异步 DDL 等内核特性,持续改进 SQL 兼容性,实现子查询展开、Join 下推等复杂优化,并开发了平滑扩容、一致性备份恢复、SQL 闪回、SQL 审计等运维能力。这段时间我们不断扩展所谓分库分表中间件技术的能力边界,试图找到它的能力上限。这个探索的过程,一方面使我们的计算层能力更加稳定、丰富和标准化,另一方面也促使着 DRDS 从中间件到分布式数据库的蜕变。
PolarDB-X 2.0 时代
18 年开始,我们逐渐触碰到了计算层的能力边界,比如无法提供 RR 隔离级别的事务能力、计算下推受限于 SQL 表达能力、数据查询的传输效率底下、多副本的线性一致性不可控等,这些问题像一个无法穿透的屏障,我们能看到屏障的对面是什么,能看到所有障碍都指向了同一个方向:计算层需要与存储层深度融合。
值得高兴的是,我们的 AliSQL 分支从诞生起就没有停止前进的步伐,通过集团业务多年的技术锤炼,基于 AliSQL 演化而来的 X-DB 数据库(包括 X-Paxos 协议库、X-Engine 存储引擎等),在全球三副本、低成本存储等技术有了非常好的沉淀。
与此同时,基于云原生架构理念的 PolarDB,通过引入 RDMA 网络优化存储计算分离架构,实现一写多读的能力,并提供资源池化降低用户成本,优化并提供秒级备份恢复、秒级弹性等能力,成为公有云增速最快的数据库产品。
这些技术探索和沉淀,使 PolarDB-X 团队有底气开始思考基于云架构的分布式数据库应该是什么样的形态,从宏观角度来看,会有云原生、国产化、分布式、HTAP 等诉求,从用户角度来看,需要满足用户使用云的一些期望,比如用户的数据库数据永远不会丢,即使主机异常宕机,这里需要有数据强一致以及高可用容灾等能力。再比如随着移动互联网和 IoT 的普及,数据层面会有爆炸式的增长,以及今年疫情之后有更多的企业会关注IT成本,因此高性能、低成本和可扩展的计算和存储能力也成为普适性诉求,另外类似 Snowflake 的按查询付费的弹性能力,也是市场的另一个诉求。因此,简单总结一下,下一代的分布式数据库需要具备:金融级高可用和容灾、水平扩展、低成本存储、按需弹性、透明分布式、HTAP 混合负载、融合新硬件等。
所以,2019 年 PolarDB-X 团队完成 DRDS SQL 引擎和 X-DB 数据库存储技术的融合,并结合 PolarDB 的云原生特性,承上启下推出了新一代的云原生分布式数据库。 专注解决单机解决不好的分布式扩展性问题,满足分布式数据一致性要求,并支持从单机到分布式的平滑演进,利用云原生技术的优势提供低成本和弹性能力,在交付上具备线上公有云、线下专有云、轻量化等全形态输出。
架构演进理念
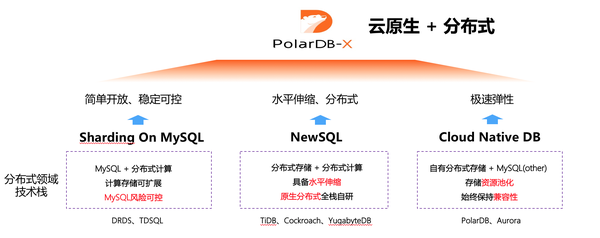
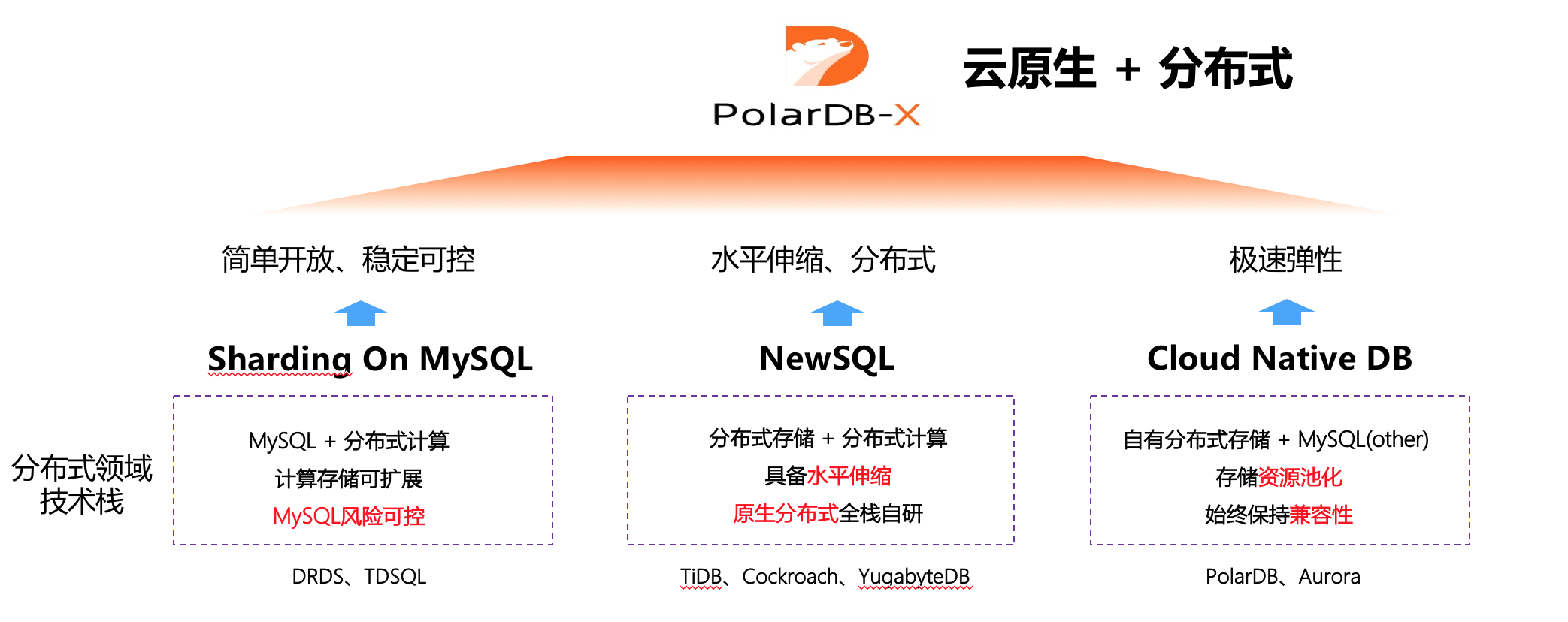
目前分布式领域的 3 个技术方向( Sharding 技术/ NewSQL 原生分布式技术/云原生 DB 技术),每种分布式都有其自己的优势和特点,PolarDB-X 的架构是站在巨人的肩膀之上,继承了 DRDS 和 X-DB 技术的稳定性、结合 PolarDB 的云原生技术、融入 NewSQL 对于分布式数据一致性的能力,为用户提供新的云原生+分布式的产品体验。
大家或许会有疑惑,基于云原生共享存储模式的分布式会有哪些不一样的优势,这里也从几个角度来分析论证一下。
- 存储成本角度。云是当前的发展趋势,而云的本质是虚拟化,目前基于安全容器、ECS等云的虚拟资源部署数据库也得到了成功的实践证明,ECS下挂的高效云盘默认已经做了3副本高可用,传统数据库三副本技术叠加虚拟化之后,会出现3*3=9份存储副本,虽然可以通过logger节点、EC技术部分消除成本,但还是存在一定程度的放大。比较理想的做法,是基于共享存储的理念,将三副本的技术下层到存储层,机头部分可以做无状态轻量化,这是面向云的架构理念。
- PolarDB全面助力分布式。 PolarDB中共享存储的设计是PolarFs(《PolarFS-An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database》),相比通用的云盘存储,PolarFs结合数据库的特点设计了一写多读、秒级备份、快速克隆、透明压缩等能力,在低成本、高性能、弹性能力上相比于传统的本地盘模式有更强的竞争力,未来PolarDB也会陆续有更强的技术爆点。比如:PolarFs针对一个PolarDB实现多点可写,基于数据库中的库、表等维度实现无数据冲突的并发多点写,结合分布式天生的分片能力,可以做到分布式更好的弹性能力。
- 想象一个场景A:PolarDB-X的多个分片数据都在一个共享存储上,我们要做分片能力扩容,其实就是重新拉起一份CN或DN节点,因数据都在一份存储之上,这样就不需要做任何数据迁移动作,整个分片扩容可以说是秒级完成,和传统的小时或者天级别的扩容是有质的区别,这就是真正意义上的极致弹性能力。基于这个PolarDB-X的极致弹性,用户就可以做更好的业务容量规划,比如只需要在大促活动的前1个小时做一下弹性扩容,而不需要提前几天做传统意义上的数据迁移扩容。
- 想象一个场景B:用户刚开始使用一个PolarDB,解决存储扩展性的问题,随着用户单表数据的膨胀,会遇到MySQL B+Tree的大表或热点表问题。这时候如果能对其中几张业务大表发起一个表分裂的Online DDL,用户可以不需要迁移数据就平滑演进到分布式PolarDB-X,基于分布式的分布式事务、分布式SQL引擎等透明分布式能力,用户可以不用停机做到平滑演进。ps. 现实情况中用户大部分只是个别大表的情况,但将全部小表也进行数据分片,反而会极大影响小表的性能和增加用户的改造成本,这也是普遍NewSQL所带来的业务问题,因为引入全新的技术栈所带来的生态兼容的问题。基于这个PolarDB-X的平滑演进,用户可以保留最好的单机使用体验的同时,满足分布式的扩展性。
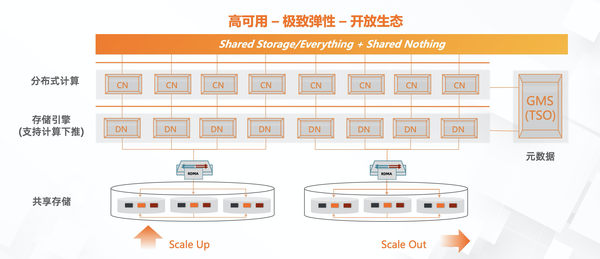

另外时下分布式数据库落地过程中,最难的或许不是纯自研带来的那种掌控感,而是生态构建,正所谓得生态者得天下,PolarDB-X 在生态的构建上有两个主要策略:
- 选择高度兼容主流生态,而不是另起炉灶、自我封闭。开源和标准是建立生态的方法之一,但不是唯一,因此在发展过程中 PolarDB-X 坚定自主可控、开放生态的发展思路,持续围绕 MySQL 开源生态构建分布式能力。因分布式特性的要求,我们也会在满足 MySQL 兼容性的要求前提下,引入分布式的计算下推和优化、RPC 访问协议、Paxos 共识协议、全局一致性事务、全局 TSO 时钟、自研存储引擎、数据动态扩缩容等,打造 NewSQL 原生分布式的能力。
- 业务多样性支持。数据库生态有一个很关键的特征是多样性,这也是为什么传统数据库领域中有 OLTP/OLAP/NoSQL 等多种分类的原因。接下来的关系数据库的发展越来越多会看到像HTAP(Hybrid Transactional/Analytical Processing)、HSAP(Hybrid Serving/Analytical Processing) 这样的技术,将在线事务处理和分析合二为一,将在线分析和离线计算合二为一。我们会越来越多的看到数据库和大数据系统的结合,为客户提供数据从生产到处理、从存储到计算分析的数据库整体方案。PolarDB-X 2.0 基于分布式下 MPP 的扩展性、以及结合低成本存储和高性能列存,HTAP 能力未来也会给大家带来不一样的体感。
云的未来已来,PolarDB-X 云原生分布式我们在路上,欢迎大家加入我们,一起以必成之心,创未有之业 !
云原生数据库PolarDB分布式版新增标准版形态,基于X-Paxos提供100%兼容MySQL的高可靠性集中式数据库服务。
阿里巴巴集团双十一同款数据库,即刻拥有:
