机器学习五要素之Optimizer Survey -SGD variants

填一下机器学习模型设计五要素埋的坑,讲讲sgd variants之间的关系。
机器学习的终极问题都会转化为目标函数的优化问题,给定一个充分表达的模型空间,我们能找到一个好的模型吗?这就是优化算法要解决的问题。
大量不同的网络架构,其表现力是同等的,任何性能上的差异都是由于某些架构比其他架构更容易优化导致的,不是模型的表现力不够,而是我们没有把它训练好。借用文献[8]中的一幅图来看一下优化算法的发展脉络:
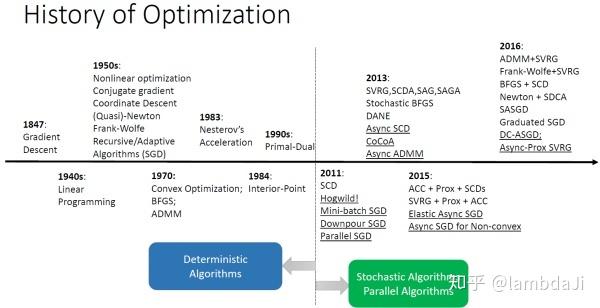

本文仅讨论工业界常用的sgd及其variants之间的区别与联系,包括:GD/SGD/Momentum/Nesterov/SVRG/Adagrad/Adadelta/RMSprop/Adam/Downpour SGD/Hogwild!
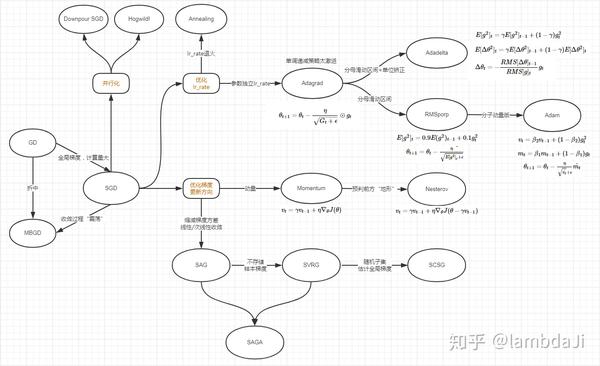

如上图,SGD的变种主要围绕3个方向展开:
#1 优化learn_rate → 自适应学习率
--Annealing 全局共享learn_rate 所有的参数以相同的幅度进行更新
* 随步数衰减
* 指数衰减
* 1/t衰减
--Adagrad 参数独立learn_rate 更新幅度取决于参数本身#2 优化梯度方向 → 方向感,减小震荡
--动量Momentum,Nesterov
--SAG/SVRG/...#3 并行化 → Scalable
--Hogwild!
--Downpour SGD参考文献:
[1] http://sebastianruder.com/optimizing-gradient-descent/?url_type=39&object_type=webpage&pos=1
[2] 自适应学习率调整:AdaDelta - Physcal - 博客园
[4] What are differences between update rules like AdaDelta, RMSProp, AdaGrad, and AdaM?
[6] 《An overview of gradient descent optimization algorithms》
[7] 随机梯度下降综述
[8] 王太峰-浅谈分布式机器学习算法和工具.pdf
[9] A Stochastic Gradient Method with an Exponential Convergence Rate for Finite Training Sets
[10] Accelerating Stochastic Gradient Descent using Predictive Variance Reduction
[11] A Fast Incremental Gradient Method With Support for Non-Strongly Convex Composite Objectives
[12] Less than a Single Pass Stochastically Controlled Stochastic Gradient Method
