
时间序列数据库漫谈

这篇文章是写给东岳网络工作室的小伙伴们的 (广告:欢迎在交大的同学加入),适用于有一定数据库背景并且想要了解时间序列数据库的同学。 PS: 中文版是在英文版之后写的,很生硬,请见谅。
目录
- 什么是时间序列数据库 (TSDB)
- 时间序列数据库数据模型
- 时间序列数据库演变
- 时间序列数据库类型
- KairosDB
- InfluxDB
- 热点话题
- 低延迟
- 数据
- 元数据索引
- Tracing
什么是时间序列数据库 (TSDB)
时间序列数据库 Time Series Database (TSDB) 相对于关系型数据库 (RDBMS),NoSQL,NewSQL 还很年轻。 但是,随着系统监控以及物联网的发展,已经开始受到更多的关注。 维基百科上对于时间序列的定义是‘一系列数据点按照时间顺序排列’, 但是我个人的理解是存储在服务端的客户端历史。 时间序列数据就是历史,它具有不变性, 唯一性以及可排序性。 比如在2017年9月3日21点24分44秒,华东区的机器001的CPU使用率是10.02%, 这个值不会像银行存款一样随着时间发生变化,它一旦产生了就不会有更新。 下一秒的使用率是一个新的数据点,其他机器的使用率在其他时间序列里。 并且数据到达服务器的顺序并不影响正确性,根据数据本身可以直接进行排序和去重。 客户端发送本地的历史到服务器端,即使服务器端挂掉了,客户端依旧继续他本来要做的事情而不受到影响。 对于很多客户端来说,发送数据到 TSDB 跟它的本职工作并没有关联。 比如一个静态文件服务器的主要职责是传送文件而不是上报 HTTP 状态码。 关系型数据库则起着完全不一样的作用,它是客户端做决定的主要依据, 这就导致时间序列数据库和关系型数据库的读写规律有很大的不同。 比如你取钱之前,银行的程序必须从数据库里找到你的那条存款记录,读出你的余额,确认不会透支才能把钱给你, 然后更新你的余额。 然而大多数时间序列数据库的客户端是只读(监控系统)或者只写(被监控的系统), 并且读取数据是并不是读取特定的某条,而是读取某个时间区间内的大量数据,比如最近1小时的CPU使用率远比 2017年9月3日21点24分44秒的CPU使用率有用,脱离上下文的时间序列数据并没有什么作用。
时间序列数据跟关系型数据库有太多不同,但是很多公司并不想放弃关系型数据库。 于是就产生了一些特殊的用法,比如用 MySQL 的 VividCortex, 用 Postgres 的 Timescale。 很多人觉得特殊的问题需要特殊的解决方法,于是很多时间序列数据库从头写起,不依赖任何现有的数据库, 比如 Graphite,InfluxDB。
时间序列数据库演变
时间序列数据库有很多, 下面列出的是一些我个人认为具有里程碑意义的数据库。 很多数据库主页上并没有最初版本的发布日期,因此以 GitHub 上最早的 tag 作为发布日期。
- 1999/07/16 RRDTool First release
- 2009/12/30 Graphite 0.9.5
- 2011/12/23 OpenTSDB 1.0.0
- 2013/05/24 KairosDB 1.0.0-beta
- 2013/10/24 InfluxDB 0.0.1
- 2014/08/25 Heroic 0.3.0
- 2017/03/27 TimescaleDB 0.0.1-beta
RRDTool 是最早的时间序列数据库,它自带画图功能,现在大部分时间序列数据库都使用Grafana来画图。 Graphite 是用 Python 写的 RRD 数据库,它的存储引擎 Whisper 也是 Python 写的, 它画图和聚合能力都强了很多,但是很难水平扩展。 来自雅虎的 OpenTSDB 使用 HBase 解决了水平扩展的问题。 KairosDB 最初是基于OpenTSDB修改的,但是作者认为兼容HBase导致他们不能使用很多 Cassandra 独有的特性, 于是就抛弃了HBase仅支持Cassandra。 有趣的是,在新发布的 OpenTSDB 中也加入了对 Cassandra 的支持。 故事还没完,Spotify 的人本来想使用 KairosDB,但是觉得项目发展方向不对以及性能太差,就自己撸了一个 Heroic。 InfluxDB 早期是完全开源的,后来为了维持公司运营,闭源了集群版本。 在 Percona Live 上他们做了一个开源数据库商业模型正面临危机的演讲,里面调侃红帽的段子很不错。 并且今年的 Percona Live 还有专门的时间序列数据库单元。
时间序列数据库数据模型
时间序列数据可以分成两部分,序列和数据点。 序列就是标识符,比如华东区机器001的CPU使用率。 数据点是时间戳和数值构成的数组。
对于序列,主要的目的是方便使用者进行搜索和筛选。 比如你需要查询华东区所有机器的CPU使用率。 序列 华东区机器001的CPU使用率 的标识符是 name=cpu.usage machine=001 region=cn-east, 查询则是 name=cpu.usage machine=* region=cn-east。 为了处理大量的序列,需要建立(倒排)索引来提高查询速度。 一些时间序列数据库选择使用外部搜索引擎来解决这个问题,比如 Heroic 使用了 Elasticsearch, 另一些则选择自己写索引,比如 InfluxDB, Prometheus。
对于数据点,有两种模型,一个数组的点 [{t: 2017-09-03-21:24:44, v: 0.1002}, {t: 2017-09-03-21:24:45, v: 0.1012}] 或者两个数组,一个存时间戳,一个存数值。前者是行存,后者是列存(不是列簇)。 大部分基于现有数据库( Cassandra, HBase ) 的是第一种。 对于新的时间序列数据库第二种更为普遍,TSDB 属于 OLAP 的一个子集,列存能有更好的压缩率和查询性能。
时间序列数据库类型
时间序列数据库可以分成两类,基于现有的数据库或者专门为时间序列数据写的数据库。 我们以 KairosDB 和 InfluxDB 为例来分析。 有很多时间序列数据库是基于 Cassandra 的, KairosDB 是其中比较早的一个。 InfluxDB 是专用于时间序列的数据库,他们尝试了很多存储引擎,最后写了自己的 Time Structured Merge Tree.
KairosDB
在看 KairosDB 之前我们先用一个简化版本的预热一下。 Xephon-K 是我写的一个有多种存储后端的时间序列数据库(专门用来对付各种课程大作业)。 它有一个非常 naive 的基于 Cassandra 的实现。
如果你对 Cassandra 不熟的话,这里有个简单的介绍。 Cassandra 是一个列簇数据库,是谷歌 BigTable 的开源实现。列簇又被称作宽列。 实质上是一个多层嵌套的哈希表。它是一个行存储,不是列存储。 一些 Cassandra 的名词可以跟关系型数据库中的对应起来。 Cassandra 中的 Keyspace 就是指的 database, 比如一个博客和一个网店虽然使用同一个 MySQL 服务器,但是各用一个数据库以进行隔离。 Cassandra 中的 Table 是一个哈希表,他的 Partition Key 是哈希表的键(也被叫做物理行键),它的值也是一个哈希表,这个哈希表的键是 Cluster Key, 它的值还是一个蛤希表。 当使用 CQL 创建一个 Table 的时候,主键中的第一个列是 Partition Key,第二个列是 Cluster Key。 比如在下面的 CQL 中, Keyspace 是 naive, Table 是 metrics,Partition Key 是 metric_name, Cluster Key 是 metrics_timestamp。 最内层的哈希表是 {value: 10.2}, 如果需要我们可以存更多的值,比如 {value: 10.2, annotation: '新 bug 上线啦'}。
CREATE TABLE IF NOT EXISTS naive.metrics (
metric_name text, metric_timestamp timestamp, value int,
PRIMARY KEY (metric_name, metric_timestamp))
INSERT INTO naive.metrics (metric_name, metric_timestamp, value) VALUES (cpu, 2017/03/17:13:24:00:20, 10.2)
INSERT INTO naive.metrics (metric_name, metric_timestamp, value) VALUES (mem, 2017/03/17:13:24:00:20, 80.3)
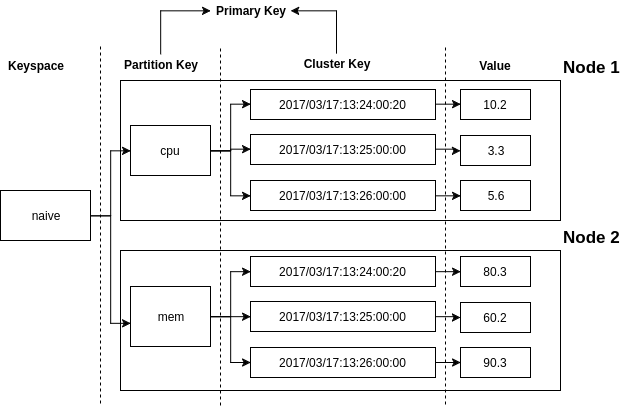

上图显示了使用 Cassandra 存储时间序列数据时 naive 的表结构, Cluster Key 存储时间戳,列的值存储实际的数值。 它 naive 之处在于序列和 Cassandra 的物理行是一一对应的。 当单一序列的数据点超过 Cassandra 的限制(20亿)时就会崩溃。
一个更加成熟的表结构是把一个时间序列按时间范围分区,(KairosDB 按照 3 周来划分,但是可以根据数据量进行不定长的划分)。 为了存储分区的信息,需要一张额外的表。 同时在 naive 里序列的名称只是一个简单的字符串,如果需要按照多种条件进行筛选的话,需要存储更多的键值对,并且对于这些键值对需要建立索引以提高查询速度。
下面是完整的 KairosDB 的表结构,data_points 表对应的是 naive 里的 metrics 表。 它看上去不像人写的,因为它就是直接导出的,KairosDB 使用的旧版 Cassandra 的 Thrift API 创建表结构,没有 .cql 文件。
CREATE TABLE IF NOT EXISTS data_points (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE;
CREATE TABLE IF NOT EXISTS row_key_index (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE;
CREATE TABLE IF NOT EXISTS row_key_time_index (
metric text,
row_time timestamp,
value text,
PRIMARY KEY ((metric), row_time)
)
CREATE TABLE IF NOT EXISTS row_keys (
metric text,
row_time timestamp,
data_type text,
tags frozen<map<text, text>>,
value text,
PRIMARY KEY ((metric, row_time), data_type, tags)
)
CREATE TABLE IF NOT EXISTS string_index (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE
有很多基于 Cassandra 的时间序列数据库,他们的结构大多相同,你可以看这个列表。 我最近正在写一个如何用 Cassandra 和 Go 自己写个时间序列数据库的博客,写好之后会把地址更新在这里。
InfluxDB
InfluxDB 在存储引擎上纠结了很久, leveldb, rocksdb, boltdb 都玩了个遍,最后决定自己造个轮子叫 Time Structured Merge Tree。
Time Structured Merge Tree (TSM) 和 Log Structured Merge Tree (LSM) 的名字都有点误导性,关键并不是树,也不是日志或者时间,而是 Merge。 写入的时候,数据先写入到内存里,之后批量写入到硬盘。读的时候,同时读内存和硬盘然后合并结果。 删除的时候,写入一个删除标记,被标记的数据在读取时不会被返回。 后台会把小的块合并成大的块,此时被标记删除的数据才真正被删除,这个过程叫做 Compaction。 相对于普通数据,有规律的时间序列数据在合并的过程中可以极大的提高压缩比。
下图是一个简化版的 TSM,每个块包含序列标识符,一组时间戳,一组值。 注意时间戳和值是分开存储的,而不是交替存储的,所以 InflxuDB 是一个列存储。 InfluxDB 会根据数据来选择压缩的方法,如果可以使用行程编码是最好的, 否则会使用 Gorilla 中提到的浮点数压缩方法以及变长编码。 时间戳和数值一般会使用不同的压缩方法,因为时间戳大多是非常大的整数而数值是非常小的浮点数。
chunk
--------------------------------------------------
| id | compressed timestamps | compressed values |
--------------------------------------------------
tsm file
-------------------------------------------------------------------
| header | chunk 0 | chunk 1 | ... | chunk 10086 | index | footer |
-------------------------------------------------------------------
热点话题
低延迟
时间序列数据库主要是用来分析的,所以提高响应速度对于诊断生产环境的问题是十分重要的。
最直接的提速方法就是把所有数据都放在内存,Facebook 写了叫 Gorilla 的纯内存时间序列数据库发表在 VLDB 上,现在已经开源,改名为 Beringei(都是猩猩…)。
另一种提速的方法是提前聚合。因为查询中经常需要对一个很长的时间区间取一些粗粒度的值,比如6月到8月每天的平均CPU使用率。 这些聚合值(均值,最大,最小) 都可以在存储数据的时候计算出来。BtrDB 和 Akumuli 都在内部节点中存储聚合值,这样在很多查询中底层的节点不需要被访问就可以得到结果。
同时一个好的数据传输格式也可以提高响应速度,虽然 JSON 被广泛使用,但是二进制的格式对于有大量数字的数据会显著的提升。 protobuf 可能会是一个更好的选择。
处理旧数据
很多时间序列数据都没有多大用处,特别是当系统长时间正常运行时,完整的历史数据意义并不大。 所以有些数据库比如 RDDTool 和 Graphite 会自动删除高精度的数据,只保留低精度的。 但是对于很多新的时间序列数据库,在聚合和删除大量旧数据的同时保证系统正常运行并不像删除一个本地文件那样简单。 如果监控系统比被监控系统还不稳定就比较尴尬了。
元数据索引
时间序列的标识符是时间序列数据库里主要的元数据。 Heroic 使用 Elasticsearch 来存储元数据, 查询首先通过 Elasticsearch 来取得符合要求的序列标识符,之后从 Cassandra 根据标识符来读取对应的数据。 但是维护一个完整的搜索引擎带来的运维压力和增加的通信时间都是不能忽视的。 因此 InfluxDB 和 Prometheus 就自己写了倒排索引来索引元数据。
Tracing
InfluxDB 的人写了一篇博客 Metrics are dead, 起因是在一个关于监控的会议 Monitorama 上有人说单纯的监控数据已经不能满足他们复杂的微服务架构了。 于是 InfluxDB 的人反驳说并不是所有人都在使用大规模的分布式系统,对于很多简单的应用单纯的监控数据已经完全够用了。 我的看法是时间序列数据库是可以用来存 Trace 的。 Trace 是更加复杂的时间序列数据,把单纯的数值变成一个包含更多信息的对象,它就是一个 Trace。 并且很多流行的 Tracer 的存储也是使用 Cassandra, 比如 Zipkin, Uber 的 Jaeger。更新: InfluxDB 现在已经支持存储 Trace 了
由于篇幅限制,有很多话题我们没有涉及,比如压缩,Pull vs Push, 写放大等,在以后的博客中会陆续介绍。
参考
- Awesome Time Series Database
- Akumuli
- Beringei
- BtrDB
- Gorilla
- Grafana
- Graphite
- Heroic
- InfluxDB
- Jaeger - Tracer
- KairosDB
- OpenTSDB
- Prometheus
- RRDTool
- Timescale - TSDB using Postgres
- VividCortex - TSDB using MySQL
- Zipkin - Tracer
许可
作者郭平雷,同步发表在个人博客和东岳团队博客上,采用知识共享署名-非商业性使用-相同方式共享 3.0 未本地化版本许可协议进行许可,非商业性转载请注明出处(东岳博客),其他需求请与我们联系。
