
Node.js 新手的 cli 工具开发初体验 - 项目目录管理工具 yuki

技术的学习一定要辅以代码的实践,菜鸟程序员扑在轮子上要像饥饿的人扑在面包上。
——沃兹基硕德
受到掘金上看到的 yddict:一个命令行查单词的工具 的启发,原来摸一个 Node.js 的 demo 不一定非要写一个服务器。恰逢最近开始看《算法(第4版)》,把练习代码和笔记传到 github 上时需要在 README.md 里放一份带链接的目录,方便在线跳转查阅。两者综合,就有了开发一个能够将项目内文件结构自动映射并生成为 README.md 的项目目录管理工具的灵感。
看上去是一个简单的小工具,实际上花了 3 天才基本成型(当然不是整的)。随着思路从项目目录管理到图书管理再到书籍再到文艺社,我决定将这个小工具命名为 yuki,蕴含了我个人满满的宅趣味。
幸运的是,这个日语里常见的词竟然在 NPM 里还没被抢用。我也因此不用为其加个后缀,直接就可以用这个名字传上 NPM,以供使用。
这篇文章剩下来的篇幅一是介绍这个小工具的使用场景、实际用法等,二是大概谈一谈开发过程中稍微值得一记的东西。
关于 yuki
使用 Node.js 开发的项目目录管理工具,能够将项目内文件结构自动映射并生成为 README.md

项目地址
适用场合
当一份 README.md 的主体内容是项目目录,而你又厌倦了每次增加、修改、删除项目中文件时都要对 README 进行维护,那么不妨试试 yuki!
它可以在极短时间内帮你生成符合要求的 README.md 文档。你更可以通过配置一份 yuki.config.json 来满足你的以下需求:
- 固定文档标题
- 目录前后增加固定内容
- 映射时忽略指定文件夹、文件、扩展名
- 根据指定扩展名选择是否去掉文件名的扩展名或加上书名号
- 让每个文件都带上 Github 的链接以方便在线跳转查看
你可以用 yuki 帮助你轻松维护 github 上类似博客、笔记、代码汇总等项目!
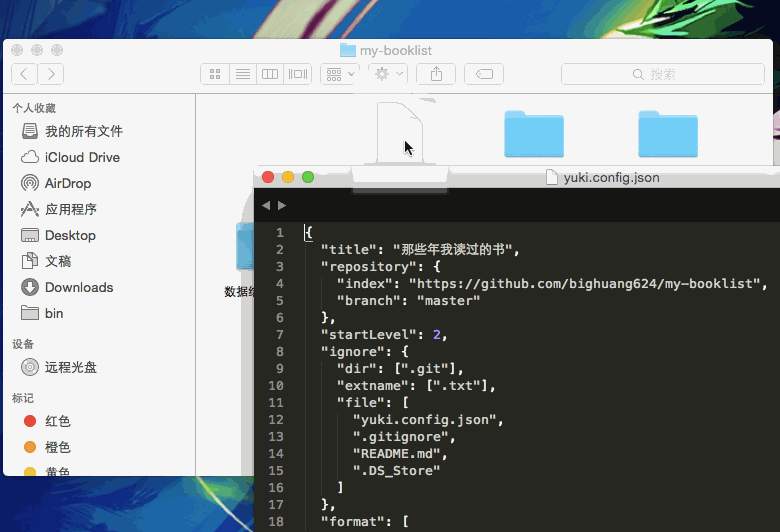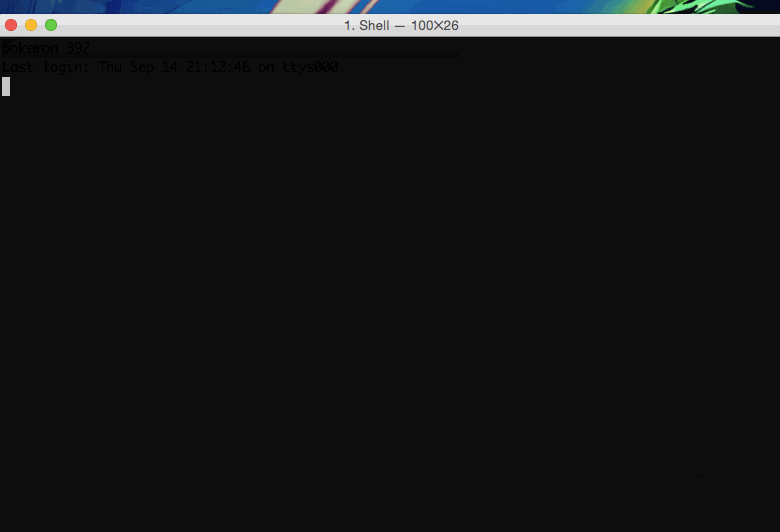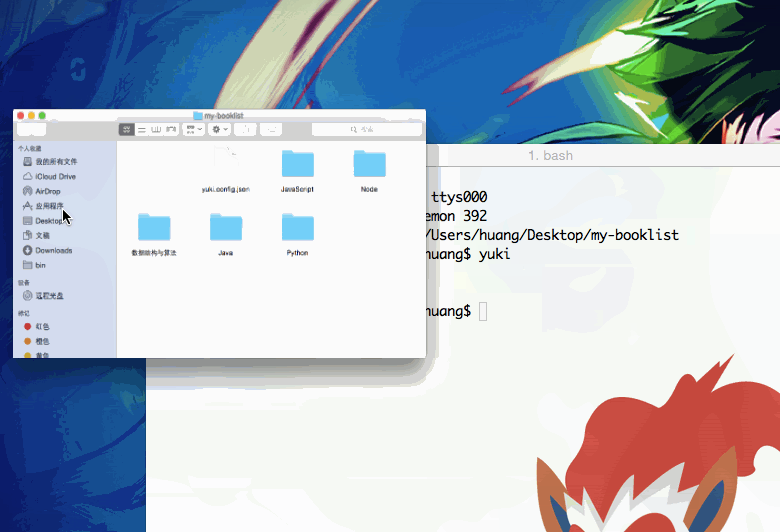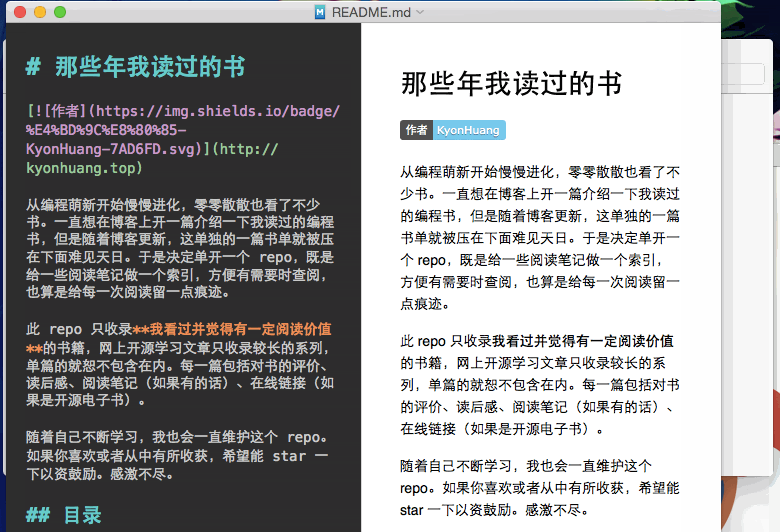
效果示例
我的《算法》笔记及代码项目的 README.md 完全通过 yuki 生成。你可以点击以查看效果。
使用方法
请确认你使用的电脑有 Node 环境,越新越好。
安装 yuki
npm install -g yuki进入需要生成 README.md 的文件夹
# 请将 <dirname> 换为文件夹路径
cd <dirname>创建 yuki.config.json(可选)
touch yuki.config.json配置 yuki.config.json(可选)
{
// README.md的大标题(h1),默认为所在文件夹名
"title": "《算法(第4版)》笔记及代码",
// github库地址,如果配置了这项会给每个文件加上超链接
// 如果配置,请保证index填写无误,且所有文件名不含空格(否则链接无法正确表示)
// branch默认为master
"repository": {
"index": "https://github.com/bighuang624/Algorithms-notes",
"branch": "master"
},
// 目录开始的标题等级
// 默认为2,即该目录下的文件夹名等级从3开始,随层级深入递减
"startLevel": 2,
// 需要忽略的目录、扩展名和文件,都以数组表示
"ignore": {
"dir": [".git"],
"extname": [".json"],
"file": [
"yuki.config.json",
".gitignore",
"README.md",
".DS_Store"
]
},
// 根据扩展名选择对展示的文件名做一些处理
// 每个扩展名的配置需要单独一个对象
// 目前支持省略扩展名"withoutExt": true
// 和加上书名号"withBookmark": true
"format": [
{
"extname": ".md",
"withoutExt": true,
"withBookmark": true
}
],
// 在大标题之后,目录之前添加的内容
// 每个对象可选择包含标题、标题等级和内容
// 其中,标题和标题等级需在一个对象中一同填写
"prefix": [
{
"content": "[](http:\//kyonhuang.top)"
}, {
"title": "目录",
"level": 2
}
],
// 在README.md末尾添加的内容
// 和prefix相同,每个对象可选择包含标题、标题等级和内容
"append": [
{
"title": "维护",
"level": 2,
"content": "本文档由 [yuki](https://github.com/bighuang624/yuki) 维护"
}
]
}
因为 JSON 标准中不含注释,请在使用时将注释去掉。项目中也提供一份不带注释、可供修改使用的 yuki.config.json 模版。
不需要的配置选项请全部删除。
创建 README.md
yukiLICENSE
开发中的那些事
Cli 命令工具开发的准备工作
我们来了解一下围绕 NPM 开发的准备工作。第一步自然是在文件夹下使用命令npm init生成 package.json 文件。
注册
可以通过以下命令在 NPM 资源库中注册用户:
npm adduser之后跟着要求填写 Username、Password、Email 就 ok 了。项目发布前可能需要npm login一下。
版本号
NPM 使用语义版本号来管理代码。语义版本号分为 X.Y.Z 三位,分别代表主版本号、次版本号和补丁版本号。当代码变更时,版本号按以下原则更新:
- 如果只是修复 bug,需要更新 Z 位。
- 如果是新增了功能,但是向下兼容,需要更新 Y 位。
- 如果有大变动,向下不兼容,需要更新 X 位。
当然我这个小项目比较随便,bug 修的多了次版本号看心情也往上升一次。
你可以用npm view <pkg> version来查看你发布到 NPM 项目的现在版本号。
测试小窍门
这两个小窍门可以节省你在一边开发一边测试的时间(没发现之前,3 天的开发时间花在这上面的不少...)。
- 在 package.json 所在目录下使用npm install . -g可先在本地安装当前命令行程序,可用于发布前的本地测试。
- 使用npm update <pkg> -g可以把全局安装的对应命令行程序更新至最新版。
编写
想要在全局使用你编写的 cli 工具,你需要在 package.json 加一个 bin 属性:
"bin": {
"yuki": "./index.js"
},yuki 换做你启动这个程序所要在命令行输入的命令。属性的值是项目的入口文件。添加这个属性后,在命令行执行yuki就等同于执行node ./index.js。
发布项目
项目写了一个版本准备发布,先在 package.json 所在目录下用npm version看一下版本号,然后就可以 publish 了。
cd yuki
npm version
npm publish之后就可以通过全局安装来使用:
npm i -g yuki获得程序运行的路径
说实话,一个我很不擅长的东西就是 API,哪怕是那些非常常用的。这次我一开始就遇到了麻烦:如何获得程序开始遍历的“根目录”路径?
在查找的同时顺便了解了一下获得各种路径的方法,有以下几种:
- process.cwd()获得 Node.js 进程当前工作的路径(即执行命令行时候的路径,而非代码路径。例如在根目录下执行node ./xxx/xxx/example.js,则process.cwd()返回的是根目录地址);
- __dirname: 获得代码存放的位置(例如运行位于/usr/a目录下的example.js文件:node example.js,则__dirname返回/usr/a);
- process.execPath: 返回返回启动 Node.js 进程的可执行文件所在的绝对路径(也就是当前执行的 Node 自身的路径,例如:/usr/local/bin/node)。
根据查询结果和实际需求,应该使用process.cwd()(我们要求在 package.json 所在目录下使用 yuki)。不过实际上使用的是path.resolve()。path.resolve()不含参数时,返回返回当前工作目录的绝对路径,也符合要求。
yuki 的编写也帮助我熟悉了 Node 里的很多 API,尤其是和 path 和 fs 相关的。
先遍历文件再深度遍历文件夹
开发的过程中发现一个问题:遍历文件夹 a 下的所有文件时,经常先深度遍历了其中的文件夹,导致文件排在这些文件夹深度遍历的结果之后,在生成的 README 中无法看出其准确位置。
解决方法还比较简单,就是在每一次递归的遍历方法中都建立一个队列,遍历到文件夹先推入队列,遍历到文件则展示。所有文件遍历结束后,将队列中的文件夹依次取出并遍历。这样既满足了要求,也没有对深度优先遍历造成影响。
更好的是,JS 的数组原生支持了push方法,使得我不用再写一个队列的实现。
结语
尽管只是一个微不足道的小工具,我还是很开心能够根据自己的实际需求开发了 yuki,更开心有机会开发一个能在名字中夹私货的项目(早在看到 vue 的版本名时我就一直心心念念了)。
如果你觉得这个小工具还不错,或者使用时觉得很方便、减轻了重复的工作负担,那么不妨为 yuki 点一个 star,因为我憧憬着能在毕业前拥有一个自己的 100+ star 项目。

当然,我更希望这些 star 是凭借我自己的开发创意和技术所得到的认可的。而我的开发经验确实不太足,所以如果你觉得这个工具不太好使、代码糟糕、发现了 bug,或是有可以增加的功能,也欢迎你开 issue 或者提交 PR 来告知我。
本文首发于我的个人博客:大黄菌的个人博客
