FADA:细粒度的对抗学习的方法实现跨域的语义分割

论文:Classes Matter: A Fine-grained Adversarial Approach to Cross-domain Semantic Segmentation
代码:https://github.com/JDAI-CV/FADA
这篇论文主要思想是在语义分割领域通过对抗来实现特征对齐。
背景
语义分割领域的数据标注通常难以获取。由于数据标注需要大量的时间人力,因此在训练时所使用的训练数据往往难以完美匹配测试时的要求。
作者提出了两种场景,分别为跨城市迁移和真实合成样本迁移。
- 跨城市迁移:由于不同城市数据因为建筑风格等一系列差异,在用A城市数据训练出的模型,在B城市做测试时可能很难达到理想的效果。
- 真实合成样本迁移:由于数据标注困难,因此有研究者提出使用计算机合成数据进行训练。如图下图左上角为GTA5游戏的图像。游戏图像是由计算机建模形成,因此很容易获取其标注数据,并且理论上游戏图像数据量是无限的。但同样将合成数据应用到现实真实数据中,效果通常不令人满意。
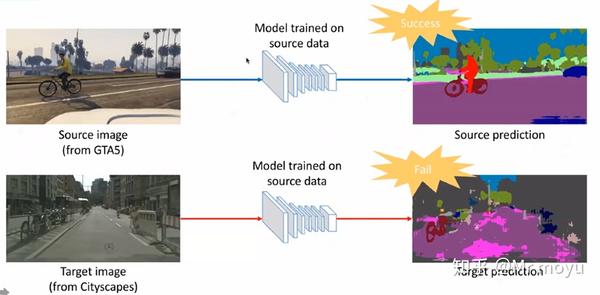

因此,论文的应用场景可以总结为。拥有有标注的source domain和无标注的target domain。我们希望使用这些数据进行训练,使模型能够在target domain上测试得到较好的效果。
很自然的想法是我们希望缩小source domain和target domain的gap。
方法
传统的特征对齐
之前有研究者提出通过对抗网络来实现特征对齐。
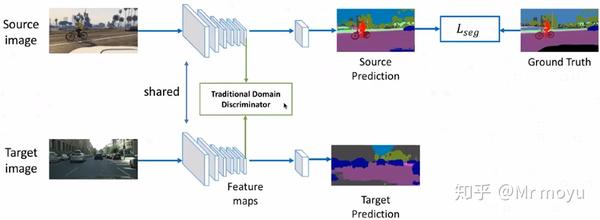

网络主要分为两部分,特征生成器,辨别器。辨别器的目标是识别送来的特征是属于source domain还是target domain,而特征生成器用来将source domain和target domain的特征对齐,迷惑辨别器使其分辨不出特征是来自source domain还是target domain。通过对抗,使特征生成器具有缩小gap的功能。
问题
但是传统方法有个问题,特征对齐仅仅是在全局上的对齐,无法保证其在类别上也对齐。
如图所示,蓝色代表source domain,红色代表target domain,加号减号代表样本类别。
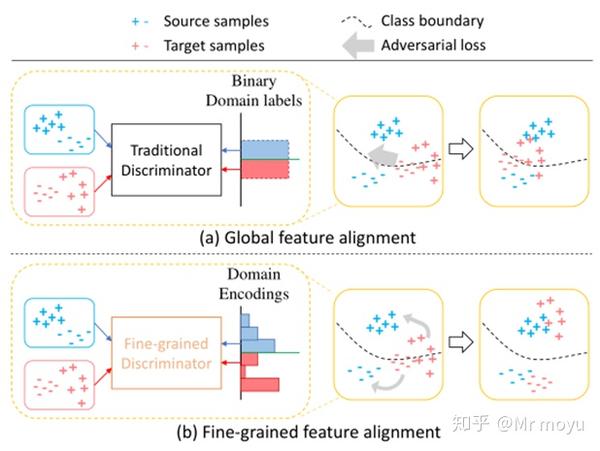

特征对齐的目标是两点:
- 红色(target domain)和蓝色(source domain)尽可能靠近。
- 虚线(分类器)能够将加减号(样本类别)划分开。
由于传统的辨别器只是分辨特征是来自source domain还是target domain,因此带来的问题就如图所示。
虽然红色(target domain)和蓝色(source domain)靠近,但仅仅只全局上的靠近,分类器(虚线)很难将样本类别(加减号)分离。
因此作者尝试在辨别器中加入类别信息,使辨别器的输出不再是单纯的域类别,而是既包含域类别,又包含类别信息。通过辨别器的监督,使特征生成器也能将类别信息区分开,使红色加号靠近蓝色加号,红色减号靠近蓝色减号。
细粒度的对抗学习
由此作者提出FADA网络,网络结构如下图所示。
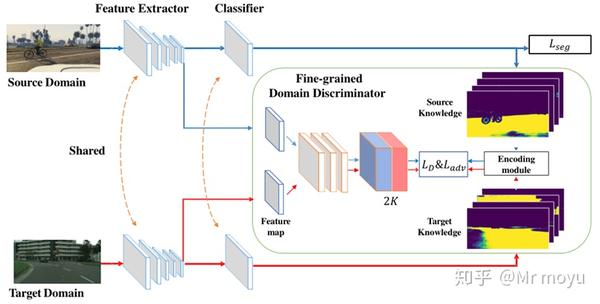

该网络与传统的对抗方法相比最大的差异在辨别器,传统的辨别器输出两通道的特征,分别代表source domain和target domain。而FADA网络,它在此处输出2K个通道,K为样本类别数。因此在对特征生成器监督的过程中附加了类别信息,使特征类别也具有对齐的趋势。
训练过程中,辨别器的损失函数为:
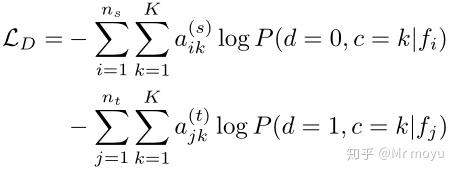

其中 a_{ik}^{(s)} , a_{jk}^{(t)} 分别代表source domain的样本 i 和target domain的样本 j 的第 k 个类别。 f_i , f_j 代表特征来自源域 x_i^{(s)} 和目标域 x_j^{(t)} 。 d 代表域变量,其中0代表源域,1代表目标域。 P(d|f) 是辨别器输出概率。
对于生成器,其损失函数为:
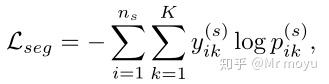
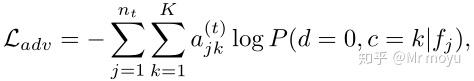

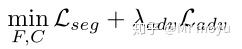
其中 \mathcal{L}_{seg} 用来在源域上进行训练,提升语义分割的能力。
\mathcal{L}_{adv} 用对抗损失来迷惑辨别器,提高来自目标域的特征被判为源域的概率,同时不损害类之间的关系。
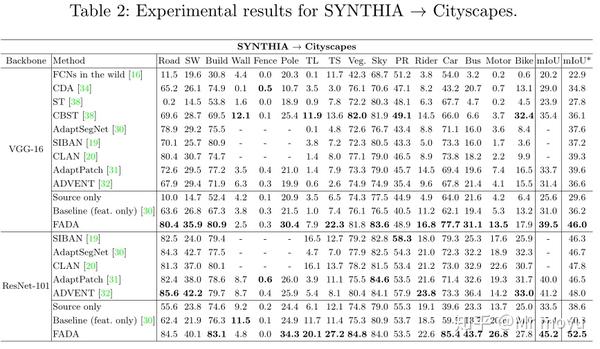
实验
对于跨城市的提升,其实效果不是非常明显
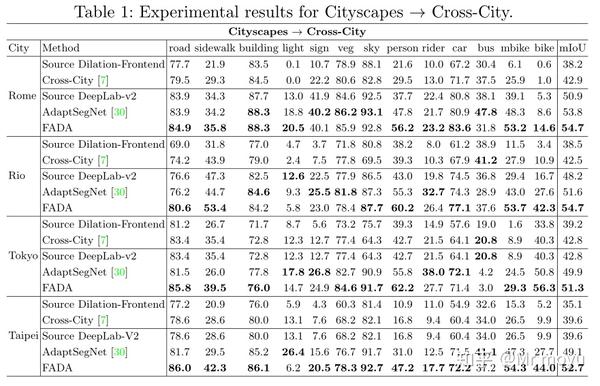

但是对于合成真实样本的对齐,FADA相比之前的效果大幅提高。