【object detection】目标检测之Fast-RCNN

本人之前总结了RCNN的实现过程,rgb提出Fast R-CNN 进行改进:Complexity arises because detection requires the accurate localization of objects, creating two primary challenges. First, numerous candidate object locations (often called “proposals”) must be processed. Second, these candidates provide only rough localization that must be refined to achieve precise localization. 第一需要处理无数的候选区域(SS+SVM)。第二,候选区域需要修订(bounding-boxes regression)。
简单对比一下Fast-RCNN和RCNN的性能:
1.Training is a multi-stage pipeline .RCNN需要CNN+SVM+bounding-boxes regression,而
Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,降低计算量。
2.Training is expensive in space and time .在相同的数据集和硬件条件下,RCNN的Train时间是84h,而Fast-RCNN是Train时间是9.5h,
3.Object detection is slow. RCNN识别时间是47s,Fast-RCNN识别时间是0.3s
网络结构
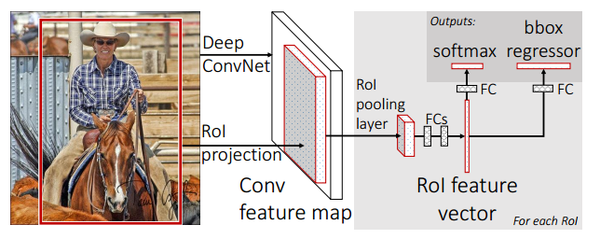

对比RCNN的网络结构,Fast RCNN主要有两个改进:
- 最后一个卷积层后加了一个RoI pooling layer。
- 损失函数使用了多任务损失函数(multi-task loss),将bbox回归直接加入到CNN网络中训练。
Fast RCNN网络结构图省略了通过ss获得proposal的过程,第一张图中红框里的内容即为通过ss提取到的proposal,中间的一块是经过深度卷积之后得到的conv feature map,图中灰色的部分就ROI feature vector过程,经过两个全连接之后,一方面用来做softmax回归用来进行分类,另一个经过全连接之后用来做bbox回归。
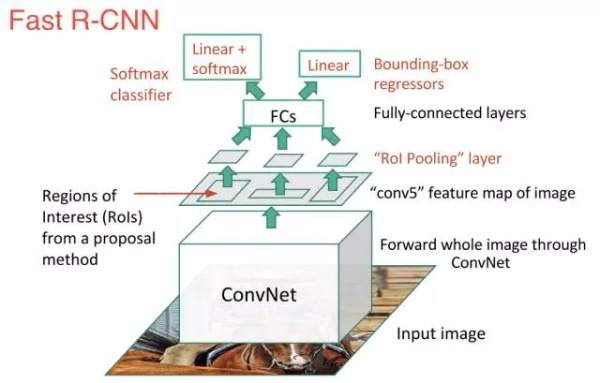

RoI pooling layer
RoI max pooling works by dividing the h × w RoI window into an H × W grid of sub-windows of approximate size h=H × w=W and then max-pooling the values in each sub-window into the corresponding output grid cell.
RoI pooling layer一个是将image中的RoI定位到feature map中对应patch,另一个是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。

实验结论
1. multi-task training help
2.Scale invariance: to brute force or finesse? 使用多尺度的图像金字塔,性能几乎没有提高
3.Do we need more training data 倍增训练数据,能够有2%-3%的准确度提升
4.Do SVMs outperform softmax? 网络直接输出各类概率(softmax),比SVM分类器性能略好
5.Are more proposals always better? 更多候选窗不能提升性能
