
《机器学习实战》学习总结(二)——决策树算法

更多优质内容,欢迎关注微信公众号:口袋AI算法。
摘要
1.信息论相关知识
2.决策树算法原理
3.代码实现与解释
今天总结决策树算法,目前建立决策树有三种主要算法:ID3、C4.5以及CART。由于算法知识点比较琐碎,我分成两节来总结。
第一节主要是梳理决策树算法中ID3和C4.5的知识点;第二节主要梳理剪枝技术、CART算法和随机森林算法的知识。
信息论
1.信息熵
在决策树算法中,熵是一个非常非常重要的概念。
一件事发生的概率越小,我们说它所蕴含的信息量越大。
比如:我们听女人能怀孕不奇怪,如果某天听到哪个男人怀孕了,我们就会觉得emmm…信息量很大了。
所以我们这样衡量信息量:
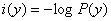
其中,P(y)是事件发生的概率。
信息熵就是所有可能发生的事件的信息量的期望:
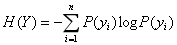
表达了Y事件发生的不确定度。
2.条件熵
条件熵:表示在X给定条件下,Y的条件概率分布的熵对X的数学期望。其数学推导如下:
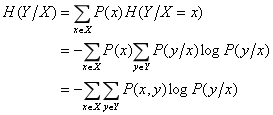
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。注意一下,条件熵中X也是一个变量,意思是在一个变量X的条件下(变量X的每个值都会取到),另一个变量Y的熵对X的期望。
举个例子
例:女生决定主不主动追一个男生的标准有两个:颜值和身高,如下表所示:
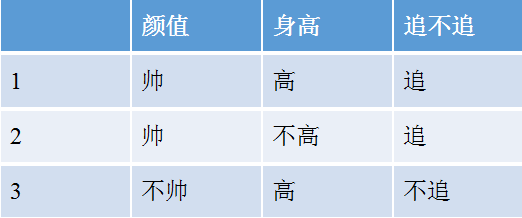

上表中随机变量Y={追,不追},P(Y=追)=2/3,P(Y=不追)=1/3,得到Y的熵:
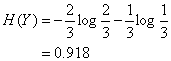
这里还有一个特征变量X,X={高,不高}。当X=高时,追的个数为1,占1/2,不追的个数为1,占1/2,此时:
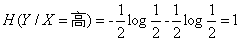
同理:
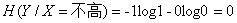
(注意:我们一般约定,当p=0时,plogp=0)
所以我们得到条件熵的计算公式:
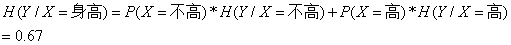

3.信息增益
当我们用另一个变量X对原变量Y分类后,原变量Y的不确定性就会减小了(即熵值减小)。而熵就是不确定性,不确定程度减少了多少其实就是信息增益。这就是信息增益的由来,所以信息增益定义如下:
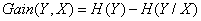
此外,信息论中还有互信息、交叉熵等概念,它们与本算法关系不大,这里不展开。
决策树算法
1.算法简介
决策树算法是一类常见的分类和回归算法,顾名思义,决策树是基于树的结构来进行决策的。
以二分类为例,我们希望从给定训练集中学得一个模型来对新的样例进行分类。
举个例子
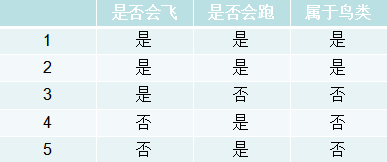
有一个划分是不是鸟类的数据集合,如下:
这时候我们建立这样一颗决策树:
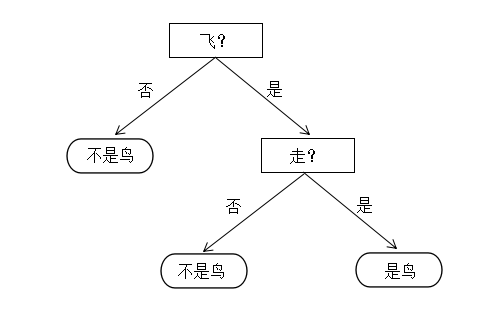

当我们有了一组新的数据时,我们就可以根据这个决策树判断出是不是鸟类。创建决策树的伪代码如下:


生成决策树是一个递归的过程,在决策树算法中,当出现下列三种情况时,导致递归返回:
(1)当前节点包含的样本属于同一种类,无需划分;
(2)当前属性集合为空,或者所有样本在所有属性上取值相同,无法划分;
(3)当前节点包含的样本集合为空,无法划分。
2.属性选择
在决策树算法中,最重要的就是划分属性的选择,即我们选择哪一个属性来进行划分。三种划分属性的主要算法是:ID3、C4.5以及CART。
2.1 ID3算法
ID3算法所采用的度量标准就是我们前面所提到的“信息增益”。当属性a的信息增益最大时,则意味着用a属性划分,其所获得的“纯度”提升最大。我们所要做的,就是找到信息增益最大的属性。由于前面已经强调了信息增益的概念,这里不再赘述。
2.2 C4.5算法
实际上,信息增益准则对于可取值数目较多的属性会有所偏好,为了减少这种偏好可能带来的不利影响,C4.5决策树算法不直接使用信息增益,而是使用“信息增益率”来选择最优划分属性,信息增益率定义为:
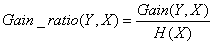
其中,分子为信息增益,分母为属性X的熵。
需要注意的是,增益率准则对可取值数目较少的属性有所偏好。
所以一般这样选取划分属性:先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.3 CART算法
ID3算法和C4.5算法主要存在三个问题:
(1)每次选取最佳特征来分割数据,并按照该特征的所有取值来进行划分。也就是说,如果一个特征有4种取值,那么数据就将被切成4份,一旦特征被切分后,该特征就不会再起作用,有观点认为这种切分方式过于迅速。
(2)它们不能处理连续型特征。只有事先将连续型特征转换为离散型,才能在上述算法中使用。
(3)会产生过拟合问题。
为了解决上述(1)、(2)问题,产生了CART算法,它主要的衡量指标是基尼系数。为了解决问题(3),主要采用剪枝技术和随机森林算法,这部分内容,下一次再详细讲述。
上述就是决策树算法的原理部分,下面展示完整代码和注释。代码中主要采用的是ID3算法。
代码实现与解读
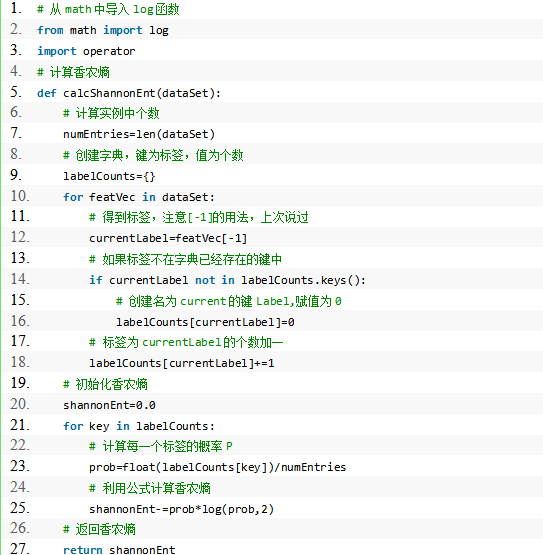
1.计算给定数据的香农熵
程序清单:

2.根据选取的数据特征属性划分数据集
程序清单:


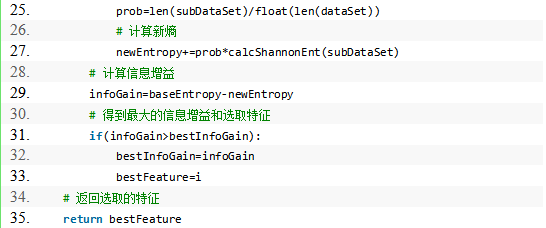
3.根据信息增益准则,选取最好的划分特征
程序清单:



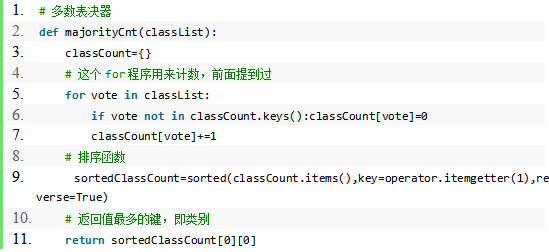
4.多数表决器
程序清单:

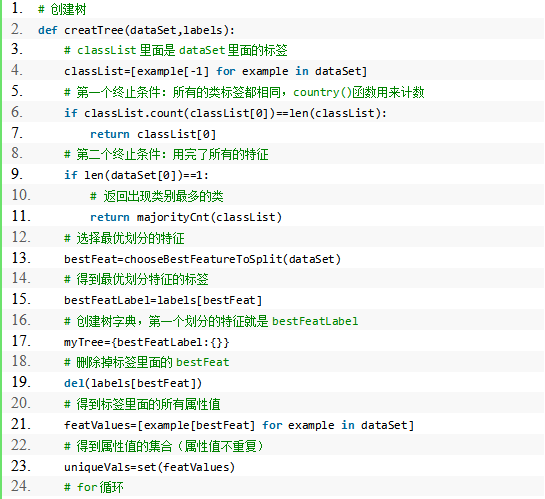
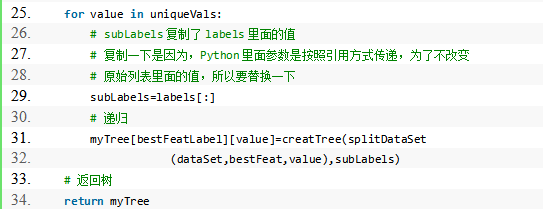
5.创建决策树
程序清单:


6.使用决策树进行分类
程序清单:


7.决策树在磁盘中的存储与导入
程序清单:


至此,我们完成了决策树算法原理和主要代码的学习。
下一节我们将学习CART算法、随机森林算法以及剪枝技术。
声明
最后,所有资料均本人自学整理所得,如有错误,欢迎指正,有什么建议也欢迎交流,让我们共同进步!转载请注明作者与出处。
以上原理部分主要来自于《机器学习》—周志华,《统计学习方法》—李航,《机器学习实战》—Peter Harrington。代码部分主要来自于《机器学习实战》,我对代码进行了版本的改进,文中代码用Python3实现,这是机器学习主流语言,本人也会尽力对代码做出较为详尽的注释。
