
10分钟带你看透区块链和云计算之底层技术三要素



谢文杰
智链ChainNova CTO
金钰
智链ChainNova 高级区块链研发工程师
渡鸦区块链专栏作者


概述,区块链与云计算相似的地方


底层三要素之云计算
1. 计算虚拟化
计算虚拟化就是在虚拟系统和底层硬件之间抽象出CPU和内存等,以供虚拟机使用。计算虚拟化技术需要模拟出一套操作系统的运行环境,在这个环境你可以安装Windows也是可以安装Linux,这些操作系统被称作Guest OS。他们相互独立,互不影响(相对的,因为当主机资源不足会出现竞争等问题,导致运行缓慢等问题)。计算虚拟化可以将主机单个物理核虚拟出多个vcpu,这些vcpu本质上就是运行的进程,考虑到系统调度,所以并不是虚拟的核数越多越好;内存相似的,把物理机上面内存进行逻辑划分出多个段,供不同的虚拟机使用,每个虚拟机看到的都是自己独立的一个内存。除了这些还需要模拟网络设备、BIOS等。这个虚拟化软件叫做hypervisor,著名的有ESXI、xen、KVM等,通常分为两种,第一种是直接部署到物理服务器上面的,如下图ESXI
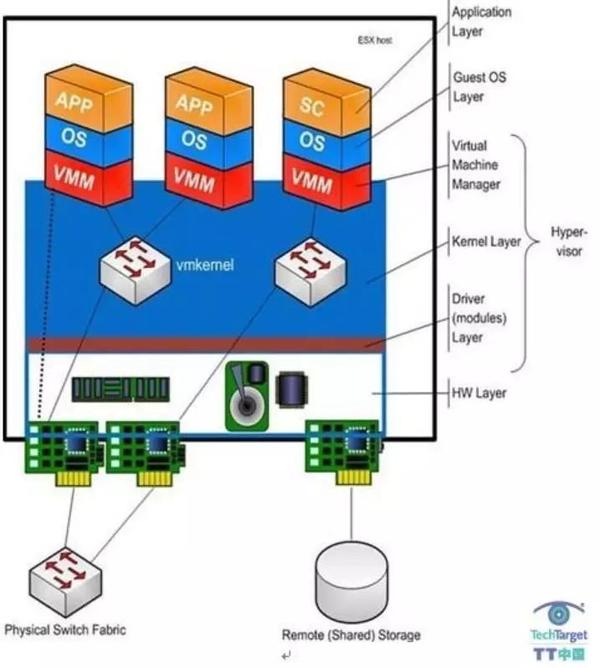

由于直接部署到裸机上面,hypervisor需要自带各种硬件驱动,虚拟机的所有操作都需要经过hypervisor。还有另一种虚拟化hypervisor,以KVM最为流行(个人电脑上面安装的virtualbox以及workstations也是),它们依赖与宿主机操作系统,这样的好处就是可以充分利用宿主机的各种资源管理以及驱动,但效率上面会打一些折扣。下图是KVM的在使用IO时候的流程图。


当然也可以从全虚拟化、半虚拟化、硬件辅助虚拟化的角度去说,现在数据中心基本都是硬件辅助虚拟化了,全虚拟化就是完全靠软件模拟、半虚拟需要修改操作让其知道自己运行在虚拟环境中、硬件辅助由硬件为每个Guest OS提供一套寄存器、Guest OS可以直接运行在特权级,这样提高效率。
虽然当前数据中心商用的虚拟化软件仍然以VMware的ESXI为主,但在OpenStack的推动下,KVM正在慢慢追赶,并且KVM是开源的,下面简单介绍一下KVM。KVM是基于内核的,从内核2.6以后就自带了,可以运行在x86和power等主流架构上。 KVM主要是CPU和内存的虚拟化,其它设备的虚拟化和虚拟机的管理则需要依赖QEMU完成。一个虚拟机本质上就是一个进程,运行在QEMU-KVM进程地址空间,KVM(内核空间)和qemu(用户空间)相结合一起向用户提供完整的虚拟化环境。
2. 网络虚拟化
网络虚拟化是一种重要的网络技术,该技术可在物理网络上虚拟多个相互隔离的虚拟网络,不依赖于底层物理连接,能够动态变化网络拓扑,提供多租户隔离,从而使得不同用户之间使用独立的网络资源切片变成可能,从而提高网络资源利用率,实现弹性的网络。这里面目前最为火热的即软件定义网络(Software Defined Network, SDN),SDN的出现使得网络虚拟化的实现更加灵活和高效,同时网络虚拟化也成为SDN应用中的重量级应用。其核心技术OpenFlow通过将网络设备控制面与数据面分离开来,从而实现了网络流量的灵活控制,使网络作为管道变得更加智能。
通过SDN实现网络虚拟化包括物理网络管理,网络资源虚拟化和网络隔离三部分。而这三部分内容往往通过专门的中间层软件完成,我们称之为网络虚拟化平台。虚拟化平台需要完成物理网络的管理和抽象虚拟化,并分别提供给不同的租户。此外,虚拟化平台还应该实现不同租户之间的相互隔离,保证不同租户互不影响。虚拟化平台的存在使得租户无法感知到网络虚拟化的存在,也即虚拟化平台可实现用户透明的网络虚拟化。
(1)虚拟化平台
虚拟化平台是介于数据网络拓扑和租户控制器之间的中间层。面向数据平面,虚拟化平面就是控制器;而面向租户控制器,虚拟化平台就是数据平面。所以虚拟化平台本质上具有数据平面和控制层面两种属性。在虚拟化的核心层,虚拟化平台需要完成物理网络资源到虚拟资源的虚拟化映射过程。面向租户控制器,虚拟化平台充当数据平面角色,将模拟出来的虚拟网络呈现给租户控制器。从租户控制器上往下看,只能看到属于自己的虚拟网络,而并不了解真实的物理网络。而在数据层面的角度看,虚拟化平台就是控制器,而交换机并不知道虚拟平面的存在。所以虚拟化平台的存在实现了面向租户和面向底层网络的透明虚拟化,其管理全部的物理网络拓扑,并向租户提供隔离的虚拟网络。
网络虚拟化平台示意图
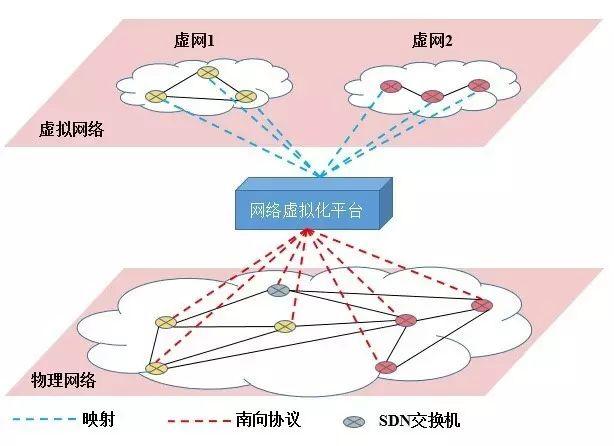

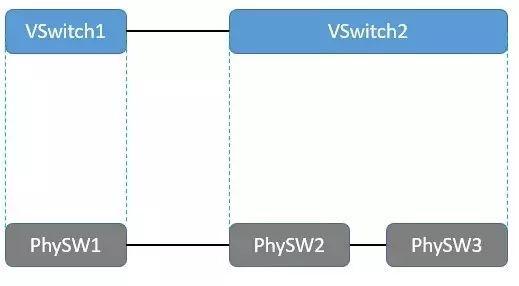
虚拟化平台不仅可以实现物理拓扑到虚拟拓扑“一对一”的映射,也应该能实现物理拓扑“多对一”的映射。而由于租户网络无法独占物理平面的交换机,所以本质上虚拟网络实现了“一虚多”和“多虚一”的虚拟化。此处的“一虚多”是指单个物理交换机可以虚拟映射成多个虚拟租户网中的逻辑交换机,从而被不同的租户共享;“多虚一”是指多个物理交换机和链路资源被虚拟成一个大型的逻辑交换机。即租户眼中的一个交换机可能在物理上由多个物理交换机连接而成。
单虚拟节点映射到多物理节点

(2)网络资源虚拟化
为实现网络虚拟化,虚拟化平台需要对物理网络资源进行抽象虚拟化,其中包括拓扑虚拟化,节点资源虚拟化和链路资源虚拟化。
拓扑虚拟化
拓扑虚拟化是网络虚拟化平台最基本的功能。虚拟平台需要完成租户虚网中的虚拟节点和虚拟链路到物理节点和链路的映射。其中包括“一对一”和“一对多”的映射。“一对一”的映射中,一个虚拟节点将会映射成一个物理节点,同理虚拟链路也是。而在“一对多”的映射中,一个虚拟节点可以映射成由多个连接在一起的物理节点;一条逻辑链路也可能映射成由链接在一起的多条链路。而对于物理节点而言,一个物理节点可以被多个逻辑节点映射。
节点资源虚拟化
节点资源的虚拟化包括对节点Flow tables(流表)、CPU等资源的抽象虚拟化。流表资源本身是交换机节点的稀缺资源,如果能对其进行虚拟化,然后由虚拟化平台对其进行分配,分配给不同的租户,那么就可以实现不同租户对节点资源使用的分配和限制。拓扑抽象仅仅完成了虚拟节点到物理节点的映射,而没有规定不同用户/租户对物理节点资源使用的分配情况。若希望进行更细粒度的网络虚拟化,节点资源虚拟化非常有必要。
链路资源虚拟化
和节点资源一样,链路资源也是网络中重要的资源,而拓扑抽象并没有规定某些用户可使用的链路资源的多少。所以在进行更细粒度的虚拟化时,有必要对链路资源进行虚拟化,从而实现链路资源的合理分配。可被抽象虚拟化的链路资源包括租户可使用的带宽以及端口的队列资源等等。
(3)网络隔离
网络资源虚拟化仅仅完成了物理资源到虚拟资源的抽象过程,为实现完全的网络虚拟化,还需要对不同的租户提供隔离的网络资源。网络隔离需要对SDN的控制平面和数据平面进行隔离,从而保证不同租户控制器之间互补干扰,不同虚网之间彼此隔离。此外,为了满足用户对地址空间自定义的需求,虚拟化平台还需要对网络地址进行虚拟化。
控制面隔离
控制器的性能对SDN整体的性能产生极大的影响,所以虚拟化平台需保证租户的控制器在运行时不受其他租户控制器的影响,保证租户对虚拟化平台资源的使用。虚拟化平台在连接租户控制器时需保证该进程可以得到一定的资源保障,比如CPU资源。而虚拟化平台本身所处的位置就可以轻易实现租户的控制器之间的相互隔离。
数据面隔离
数据面的资源包括节点的CPU、Flow Tables等资源以及链路的带宽,端口的队列资源等。为保证各个租户的正常使用,需对数据面的资源进行相应的隔离,从而保证租户的资源不被其他租户所占据。若在数据面上不进行资源的隔离,则会产生租户数据在数据面上的竞争,从而无法保障租户对网络资源的需求,所以很有必要在数据面对资源进行隔离。
地址隔离
为使租户能在自己的虚拟租户网中任意使用地址,虚拟化平台需要完成地址的隔离。实现地址隔离主要通过地址映射来完成。租户可任意定制地址空间,而这些地址对于虚拟化平台而言是面向租户的虚拟地址。虚拟化平台在转发租户控制器南向协议报文时,需要将虚拟地址转化成全网唯一的物理地址。租户的服务器的地址在发送到接入交换机时就会被修改成物理地址,然后数据包的转发会基于修改之后的物理地址进行转发。当数据到达租户目的地址主机出端口,控制器需将地址转换成原来租户设定的地址,从而完成地址的虚拟化映射。地址的虚拟化映射使得租户可以使用完全的地址空间,可以使用任意的FlowSpace(流空间:流表匹配项所组成的多维空间),而面向物理层面则实现了地址的隔离,使得不同的租户使用特定的物理地址,数据之间互不干扰。
3. 存储虚拟化
存储虚拟化是一种贯穿于整个IT环境、用于简化本来可能会相对复杂的底层基础架构的技术。存储虚拟化的思想是将资源的逻辑映像与物理存储分开,从而为系统和管理员提供一幅简化、无缝的资源虚拟视图。在没有云计算之前存储虚拟化已经发展了很久,可以说和云计算没有特别关系,而云计算存储通常指的是亚马逊的S3存储或者EBS存储等,将统一的资源池划分给多个用户。
对于用户来说,虚拟化的存储资源就像是一个巨大的“存储池”,用户不会看到具体的磁盘、磁带,也不必关心自己的数据经过哪一条路径通往哪一个具体的存储设备。
从管理的角度来看,虚拟存储池是采取集中化的管理,并根据具体的需求把存储资源动态地分配给各个应用。值得特别指出的是,利用虚拟化技术,可以用磁盘阵列模拟磁带库,为应用提供速度像磁盘一样快、容量却像磁带库一样大的存储资源,这就是当今应用越来越广泛的虚拟磁带库(VTL, Virtual Tape Library),在当今企业存储系统中扮演着越来越重要的角色。
主流的存储虚拟化有以下三种技术,在云计算场景中通常会根据实际场景选择合适的技术。
SAN
先从高端存储说起,现在高端存储应该EMC、IBM和HDS的天下,这些年外置存储跟随着廉价磁盘不断提升容量和性能,推动了SAN网络、主机FC接口不断成熟,在数据中心变得很普遍,尤其在金融领域。


SAN提供的是块存储,譬如磁盘阵列里面有10块I T的数据盘,然后可以通过做RAID或者逻辑卷(LVM)的方式划分出10个的数据盘,但这个10个数据盘已经和之前的物理盘不一样了,一个逻辑盘可能有第一个物理盘提供100G,第二个物理盘提供300G。对于操作系统来说,完全无法感知是物理盘还是逻辑盘,这是存储资源池的理念。通过RAID或者LVM不仅可以提供数据保护还能够重新划分盘的大小,提高读写速率。
但SAN也不是毫无缺点,它价格也是比较昂贵的,光纤口,光纤交换机价格高,所以才有了IPSAN存储,通过IP协议承载存储协议;无法提供数据共享,一个盘只能挂给一个主机,所以这就有了NAS存储。
NAS
NAS是文件存储,文件存储相比块存储最大的优势是能共享数据,它基于标准的网络协议,SAN是有自己一套存储协议的。常见的NAS包括NFS、FTP和HTTP文件服务器等,由于这种设备通常都有一个IP,所以一般客户机充当数据网关服务器可以直接对其访问。NAS建立在传统网络之上,所以可以更远距离的传输,并且NAS具有安装容易易于维护的特点,但其速度通常要比SAN慢很多。
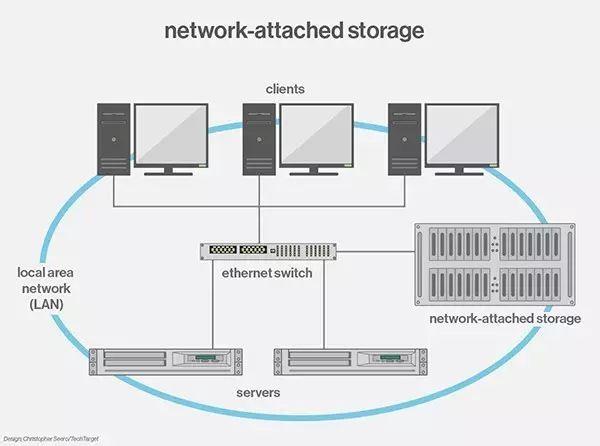

分布式存储
伴随着x86性能提升,以x86芯片构建的小型存储系统在中端存储领域开始崭露头角。通过将X86本地的磁盘利用起来构建一个大存储集群。分布式存储通常能够同时提供块存储和文件存储的能力。这里不得介绍一个和OpenStack结合紧密的分布式存储ceph,下图是ceph官网的一个整体模块图,它提供了CEPH FS文件存储系统和POSIX接口、对象存储以及最常用的快存储。


它的基石是下面的RADOS,再下面就是系统组件,包括:
- CEPH OSDs:CEPH的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补,平衡数据分布。并将数据相关的一些监控信息提供给CEPH Moniter,以便CEPH Moniter来检查其他OSD的心跳状态。一个CEPH存储集群,要求至少两个CEPH OSDs,才能有效的保存两份数据。注意,这里的两个CEPH OSD是指运行在两台物理服务器上的,并不是在一台物理服务器上开两个CEPH OSD的守护进程。
- Moniters:CEPH的Moniter守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map 、PG(Placement Group) map、CRUSH map。
- MDSs:CEPH的MDS (Metadata Server)守护进程,主要保存的是CEPH Filesystem的元数据。注意,对于CEPH的块设备和CEPH对象存储都不需要CEPH MDS守护进程。CEPH MDS 为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等等,这样可以很大层度上降低CPEH 存储集群的压力。
还有一个开源的对象存储就是openstack的Swift,Swift的初衷就是用廉价的成本来存储容量特别大的数据,swift使用容器来管理对象,允许用户存储、检索和删除对象以及对象的元数据,而这些操作都是通过用户友好的RESTful风格的接口完成。
底层三要素之区块链
1. 共享帐本
共享账本准确的说应该是分布式账本技术,这个技术从实质上说就是一个可以在多个站点、不同地理位置或者多个机构组成的网络里进行分享的资产数据库。在一个网络里的参与者可以获得一个唯一、真实账本的副本。账本里的任何改动都会在所有的副本中被反映出来,反应时间会在几分钟甚至是几秒内。在这个账本里存储的资产可以是金融、法律定义上的、实体的或是电子的资产。在这个账本里存储的资产的安全性和准确性是通过公私钥以及签名的使用去控制账本的访问权,从而实现密码学基础上的维护。根据网络中达成共识的规则,账本中的记录可以由一个、一些或者是所有参与者共同进行更新。
分布式账本技术使用密码哈希算法和数字签名来确保交易的完整性,同时确保共享账本是精确副本,并降低了发生交易欺诈的风险,因为篡改需要同时在许多地方同时执行。密码哈希算法(比如 SHA256 计算算法)能确保对交易输入的任何改动 — 甚至是最细微的改动 — 都会计算出一个不同的哈希值,表明交易输入可能被损坏。数字签名则确保交易源自发送方(已使用私钥签名)而不是冒名顶替者。
2. 共识算法
这里主要讲述区块链在发展过程中出现的五种典型共识算法:PoW、PoS、DPoS、PBFT和联合共识。
早期,比特币Bitcoin作为区块链技术的第一个成功应用率先引入了工作量证明机制(PoW,Proof of Work),工作量证明机制利用了Hash算法在随机性上这个非常重要的特性。PoW机制俗称挖矿,这里挖的是比特币里的每一个区块。每个区块用包含的交易、时间、以及一个自定义数值来计算这个区块的Hash。一个合格的区块的Hash必须满足前N位为零,因此需要不断的调整刚才那三个参数来寻找满足条件的Hash。由于Hash算法足够随机,零的个数越多,算出这个Hash的概率越低。此时,要得到合理的Block Hash需要经过大量尝试计算,计算时间取决于机器的哈希运算速度。当某个节点提供出一个合理的Block Hash值,说明该节点确实经过了大量的尝试计算,这就是工作量证明。当然,并不能得出计算次数的绝对值,因为寻找合格的Hash是一个概率事件。当节点拥有占全网n%的算力时,该节点即有n%的概率率先发布一个合格的区块。
随后,由于PoW这种算法极其耗费计算资源,截至写本文时(2017年8月),据测算,比特币网络消耗的电力就已经高达15TW。因此,随后的NXT等新兴密码学货币提出了一种新的思路即股权证明(PoS,Proof of Stake)。这种模式会根据你持有数字货币的量和时间,决定你可以发布下一个区块的概率。在PoS模式下,有一个名词叫币龄,每个币每天产生1币龄,比如你持有100个币,总共持有了30天,那么,此时你的币龄就为3000,然后按照所有人的币龄根据一个随机算法决定谁来发布下一个区块。这个时候,如果你被选中发布了一个POS区块,你的币龄就会被清空为0重新再来。
PoS也不是没有缺点,最大的缺点就是在于效率上。因此,比特股BitShares提出了委托股权证明机制(DPoS,Delegated Proof of Stake)。它的原理是让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。从某种角度来看,DPoS有点像是议会制度或人民代表大会制度。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。
以上的这些共识机制都依赖密码学货币,因为不管是PoW还是PoS,驱动寻找区块的源动力都是发布新区块的货币奖励。对于无代币的系统如HyperLedger Fabric,如何选择共识机制?这时,我们可以回过头看看PBFT。BFT(Byzantine Fault Tolerance,拜占庭容错算法)是很早就提出的分布式容错算法,可以查找拜占庭问题来进一步了解,这里不做详述。PBFT作为BFT的一种实现,是一种状态机副本复制算法,即服务作为状态机进行建模,状态机在分布式系统的不同节点进行副本复制。每个状态机的副本都保存了服务的状态,同时也实现了服务的操作。将所有的副本组成的集合使用大写字母R表示,使用0到|R|-1的整数表示每一个副本。为了描述方便,假设|R|=3f+1,这里f是有可能失效的副本的最大个数。尽管可以存在多于3f+1个副本,但是额外的副本除了降低性能之外不能提高可靠性。
除此之外,还有一种基于投票的联合共识(Voting),以Ripple为代表。这种共识使网络能够基于特殊节点列表达成共识。初始特殊节点列表就像一个俱乐部,要接纳一个新成员,必须由51%的该俱乐部会员投票通过。共识遵循这核心成员的51%权力,外部人员则没有影响力。这种共识方式同样极大的提高了效率,但是却需要确保特殊节点中恶意节点不能超过51%,牺牲的是整个网络的去中心化。
3. P2P网络
P2P为大众所熟知主要要归功于BitTorrent及BT的流行,而P2P网络的核心概念即彼此连接的多台计算机之间都处于对等的地位,各台计算机有相同的功能,无主从之分,一台计算机既可作为服务器,设定共享资源供网络中其他计算机所使用,又可以作为工作站,整个网络一般来说不依赖专用的集中服务器,也没有专用的工作站。网络中的每一台计算机既能充当网络服务的请求者,又对其它计算机的请求做出响应,提供资源、服务和内容。通常这些资源和服务包括:信息的共享和交换、计算资源(如CPU计算能力共享)、存储共享(如缓存和磁盘空间的使用)、网络共享、打印机共享等。
区块链为了实现分布式账本的能力,同样也采用了P2P网络。分布式账本会分发给网络中的所有成员节点,同时可以阻止任何单个或一组参与者控制底层基础架构或破坏整个系统。网络中的参与者是平等的,都遵守相同的协议。


作者简介:
谢文杰 智链ChainNova CTO
区块链技术专家。原金山云技术产品专家,百度移动事业部技术经理,搜狐高级工程师。毕业于南京邮电大学计算机系,十余年大型软件技术架构经验,擅长高性能高可用服务设计,对云计算、移动APP、手游、社交、P2P网络等多种类型产品的开发运营均有深度研究。从14年开始研究区块链,对众多主流区块链技术平台均有深入研究,专注于区块链技术在海量数据以及高性能、高可用软件体系内的应用实践。
金钰 智链ChainNova 高级区块链研发工程师
原IBM GBS区块链技术专家,移动应用软件架构师。互联网从业8年,在金融领域,制造业领域有丰富的行业经验。从16年开始研究区块链,曾参与邮储银行,农业银行等多家银行区块链实践项目,有丰富的咨询及实施经验。
智链ChainNova (http://www.chainnova.com)
智链由A股上市公司中南建设和美国硅谷技术公司PeerNova合资成立的一家高科技公司。定位于服务金融科技产业实践,融合区块链、云计算、大数据以及人工智能等科技板块,共同为国内乃至全球用户实现行业应用场景落地,构建互联网新金融、区块链+产业、商业认知等解决方案。目前已有行业解决方案涵盖:供应链(商品)追踪溯源、金融科技(FinTech)、IP信息公正、知识产权交易、企业外部成本交易。智链是Linux基金会和Hyperledger成员。
本文为渡鸦原创专家专栏,转载请联系后台授权。
