
左手用R右手Python系列16——XPath与网页解析库

最近写了不少关于网页数据抓取的内容,大多涉及的是网页请求方面的,无论是传统的RCurl还是新锐大杀器httr,这两个包是R语言中最为主流的网页请求库。
但是整个数据抓取的流程中,网页请求仅仅是第一步,而请求获取到网页之后,数据是嵌套在错综复杂的html/xml文件中的,因而需要我们熟练掌握一两种网页解析语法。
RCurl包是R语言中比较传统和古老的网页请求包,其功能及其庞大,它在请求网页之后通常搭配XML解析包进行内容解析与提取,而对于初学者最为友好的rvest包,其实他谈不上一个好的请求库,rvest是内置了(默认加载了xml2包)解析库,所以我们在解析HTML/xml文件的时候感觉很顺手,但是它的请求功能极其有限,对于一些高级请求设置(比如cookie管理、身份验证、报头伪装、代理设置、进程管理)几乎无能为力,当然这也是有原因的。
rvest包的作者是哈德利大神,他对rvest的定位是一个及其精简的、高效、友好的网页获取与交互包,如果你看过rvest的源文档,那么你肯定知道,rvest其实是封装了httr(请求库)和xml2(解析库),同时默认加载了httr、selectr、magrittr,所以你可以只加载rvest包就很方面的完成简单网页请求、解析任务、同时支持管道操作符和css/XPtah表达式,但是如果涉及到复杂网页结构和异步加载,很多时候我们需要原生的请求库来助阵,比如RCurl和httr,rvest更适合作为解析库来用。
但是今天这一篇暂不涉及rvest,RCurl和httr作为请求库的功能在之前的几篇中已经涉及到了主要的GET和POST请求操作,今天我们集中精力来归纳总结两大解析语法之一的XPath,主要使用工具是XML包。(至于CSS,那是rvest的默认支持解析语法,我会单列一篇进行加讲解)
本文演示的目标xml文件是我的个人博客:博客地址——raindu.com,选择的页面是博客rss源文件,是一个.xml格式的文件,内容主要包含博客发布过的文章名称、分类、标签、阅读量发布日期等
R:
library("RCurl")
library("XML")
library("dplyr")
content<-xmlParse("atom.xml",encoding="UTF-8")(备注:这里为了加快读取速度,我将atom.xml文件下载到了本地,因为该xml文件含有命名空间,可能会影响解析效果,所以你必须删除首行的命名空间之后才能正常解析,我会将删除命名空间后的atom.xml文件共享到GitHub上,如果你想要自己直接读取网页版的话,记得删除命名命名空间)
xmlns="http://www.w3.org/2005/Atom"xmlParse函数是XML中针对xml文件的解析语句,接下来分为几个部分来解析本案例文件:
1、XPath表达式中的特殊符号:
从对象从属关系上来说,xml文档主要对象分为三类:节点、文本、属性及其属性值。
通常我们使用的XPath选择工具是getNodeSet函数或者xpathSApply函数(是sapply的一个简单封装)。
在使用XPath解析式时,你需要理解四个最为重要的特殊符号:“/”,“//”,“*”,“.”,“|”。
- “/”代表绝对路径,何为绝对路径,就是不可跳转的没有任何捷径的路径,再简单的说,就是假如你在走一个100阶的台阶,如果你要按照绝对路径走过去,那么你必须从第一块台阶一个一个走过去不能省却任何一个。
- “//”代表相对路径,上面解释了绝对路径,那么相对路径就好理解多了,就是假如你腿特别长,一次跳很远,过100阶台阶想要省事儿的话,你可以一次跨过去很多阶,假如说,你腿无限长,然后可以随心所欲的跨过任何数量台阶的话(甚至可以从第一阶一次跨到最后一阶台阶),那么这种情况就和相对路径差不多了,相对路径就是可以随意跨越的,不必严格按照节点层次和顺序遍历的路径,相对路径可以使得我们在获取想要的信息时写出相对简洁的路径表达式。
- “.”指代某路径本身,该符号专门用于需要对路径进行二次引用的需求,你可以把它理解为占位符,或者管道符号传参过程中处理左侧传入参数占位所用的特殊符号。
- “*”指代任何内容,如果你了解过正则表达式的话,对此应该并不陌生。
- “|”符号代表或条件,无论是在正则中还是在函数逻辑符号中都是如此,在XPath中也是如此,使用Xath分割两个单XPath表达式,即可同时返回符合两个条件的所有信息。
在以上四个符号中第一个和第二个符号占据着绝对的高频地位,所以一定要谨记。甚至可以说,在所有的解析过程中,你仅需使用“/”,“//”两个符号即可提取所有文档信息,只是后期的内容清洗需要借助其他内置函数辅助。
getNodeSet(content,"//title",fun = xmlValue) %>% unlist
xpathSApply(content,"//title",xmlValue)

<feed>
<entry>
<title>一篇文章教你搞定JSON素材,从此告别SHP时代~</title>
<link href="http://www.raindu.com/2017/08/28/%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0%E6%95%99%E4%BD%A0%E6%90%9E%E5%AE%9AJSON%E7%B4%A0%E6%9D%90%EF%BC%8C%E4%BB%8E%E6%AD%A4%E5%91%8A%E5%88%ABSHP%E6%97%B6%E4%BB%A3/"/>
<id>http://www.raindu.com/2017/08/28/一篇文章教你搞定JSON素材,从此告别SHP时代/</id>
<published>2017-08-28T03:59:58.000Z</published>
<updated>2017-08-29T12:27:24.629Z</updated>
<content type="html">...</content>
<summary type="html">...</summary>
<category term="数据可视化" scheme="http://www.raindu.com/categories/%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%86%E5%8C%96/"/>
<category term="数据可视化" scheme="http://www.raindu.com/tags/%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%86%E5%8C%96/"/>
<category term="R语言" scheme="http://www.raindu.com/tags/R%E8%AF%AD%E8%A8%80/"/>
<category term="ggplot2" scheme="http://www.raindu.com/tags/ggplot2/"/>
</entry>
<feed/>因为rss页面的代码结构并不十分复杂,每一篇文章信息结构都是相同的,这里我将其中一篇文章及其祖先节点提取出来。我们可以很清晰的看到,按照绝对路径来看,以上应该写成:
getNodeSet(content,"/feed/entry/title",fun = xmlValue) %>% unlist
xpathSApply(content,"/feed/entry/title",xmlValue)

你会惊讶的发现,除了”raindu’s home”这个记录之外,剩余的信息和上述”//title”路径的查询结果是一样的,第一条是因为”raindu’s home”在原始xml中是feed的一个直接子节点title的值,而剩余的title节点全部都包含在feed》entry》中,第一遍使用相对路径时,因为可以自由跳转和跨越,也就时找到文档中所有含有title节点的对象值,所以路径表达式返回了所有文档中title节点值,但是第二次使用绝对路径之后,已经明确了我们要的title节点是存放在feed内的entry内的title节点,所以有了绝对路径限定之后,返回的所有节点值均为feed内的entry内的title节点。
getNodeSet和xpathSApply函数在很多情况下功能相同。但是有一个明显区别是sapply输出内容更为整齐,如何符合条件即可输出向量,而getNodeSet则一直输出list,所以提倡大家使用xpathSApply。
绝对路径和相对路径可以交叉混用,想想一下你走台阶的时候,心情好不赶时间就一步一个台阶慢慢品味,要是有事着急的话,突然一跃五步垮了好几阶台阶,然后走累了就又恢复了一步一个台阶,这个过程是很随意无拘无束的,这就是XPath路径表达式相对路径的核心理念,一定要熟记。
在原始的xml文档中,有很多的id属性和link属性,而且这些节点分布在不同层级的节点内部。
xpathSApply(content,"//*/id",xmlValue)
xpathSApply(content,"//entry/id",xmlValue)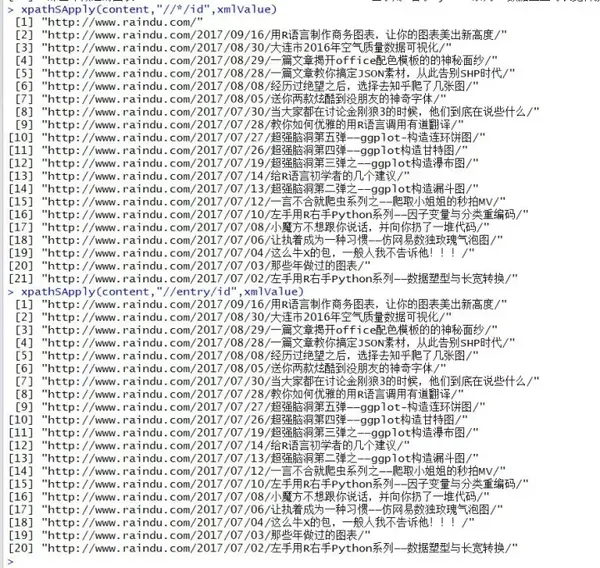

你可以很清楚的看到第一个返回多出了”http://www.raindu.com/"链接。“*”这里遍历了所有相对路径中的id属性,而第二个只能捕获到entry中的id对象。
xpathSApply(content,"//*/id | //*/title",xmlValue)

以上表达式中使用“|”符号合并了两个字句,所以返回了文档中所有的id值和title值。
2、文本谓语:
以上所有操作针对的都是节点以及节点值,而很多时候我们需要的不是节点值而是属性值,涉及到属性值捕获,则需要熟记文本谓语。
在原始文档中,每一篇本科中均有分类信息,我们想要找出含有ggplot2类别的节点并获取其链接,则公式可以写成如下形式。
xpathSApply(content,"//entry/category[@term='ggplot2']/@scheme") %>% unname
xpathSApply(content,"//entry/category[@term='ggplot2']",xmlGetAttr,"scheme")

以上两种写法是等价的,这里我们主要关注XPath文本谓语的使用,其实非常简单,每一篇博客中结构都是如下这样,category是一个闭合节点,我们仅需定位到所有tern属性值为“ggplot2”的category节点并将其对应scheme捕获就OK了)。
<entry>
<category term="R语言" scheme="http://www.raindu.com/categories/R%E8%AF%AD%E8%A8%80/"/>
<category term="数据可视化" scheme="http://www.raindu.com/tags/%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%86%E5%8C%96/"/>
<category term="R语言" scheme="http://www.raindu.com/tags/R%E8%AF%AD%E8%A8%80/"/>
<category term="ggplot2" scheme="http://www.raindu.com/tags/ggplot2/"/>
</entry>所有属性的文本谓语定位时,是紧跟着其节点,使用方括号包围,“@”号引用节点属性名,可以为节点赋值也可以不赋值。
如果这里不赋值,我们只是选择了所有含有term属性的节点。
xpathSApply(content,"//entry/category[@term]",xmlGetAttr,"scheme")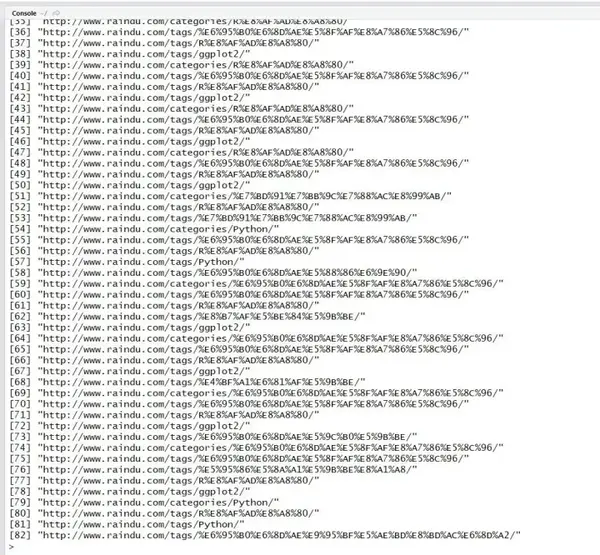

文档中一共含有82条内含term属性的类别信息。(每一篇文章都会包含若干个节点)
文本谓语可以搭配绝对路径和相对路径一起使用,并不会相互影响。
3、匹配操作:
文本谓语中可以执行特殊的匹配操作,功能类似于Excel中的left、right以及mid函数。就是匹配文本中以什么开始、结束或者包含有某些文本的记录。
查找博客文章标题中含有ggplot的id并捕获。
xpathSApply(content,"//entry/id[contains(text(),'ggplot')]",xmlValue) #根据属性值包含内容选择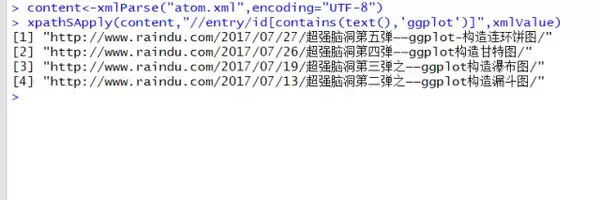

xpathSApply(content,"//entry/category[starts-with(./@term,'R')]",xmlGetAttr,"scheme")
#根据属性值以R开头的内容(结尾同理)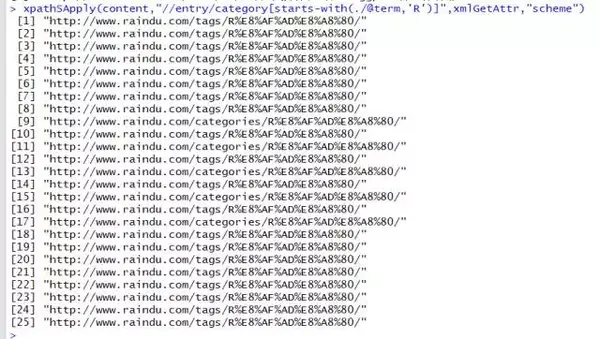

xpathSApply(content,”//entry/category[contains(./@term,’ggplot2’)]”,xmlGetAttr,”scheme”)
#根据属性值内容所含字符串进行提取
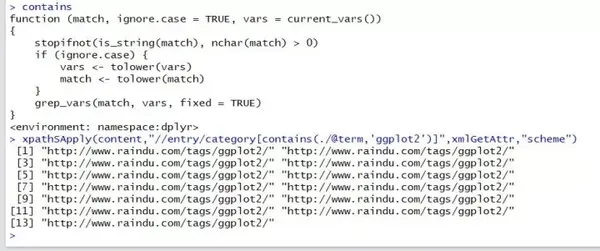

以上函数中,匹配函数内部有两个参数,前者是外部节点表达式的自然延伸,后者是匹配模式,所以第一个匹配可以解释为找到文档中所有的entry节点(相对路径)的id节点(绝对路径),并提取出这些id节点中内容含有“ggplot”字样的记录,第二条可以解释为找到 文档中所有entry节点中的category(绝对路径)节点,并提取出节点内term属性值包含“R”的节点,提取出来这些节点对象的scheme属性值。
路径表达式中如果包含匹配函数,其中的匹配模式需要使用单引号/双引号,这里往往与外部的XPath表达式的单引号/双引号冲突导致代码无法运行,所以出现这种情况时你一定要决定好内层和外层分别使用单引号/双引号,不能同时使用单引号或者双引号。
以上便是本次XPath的主要讲解内容,关于XPath的内容,可能是一本书的体量,但是对于网页解析而言,以上这些已经可以满足我们大部分需要,还有些涉及到根节点、子孙节点与父辈节点、兄弟节点甚至命名空间和DTD等内容,虽然对于深入了解XML很有帮助,但是通常在解析与获取内容中用到的机会不多,你可以自行了解。
Python:
接下来使用Python中的lxml解析库重复以上结果:
from lxml import etree
content = etree.parse('atom.xml')1、XPath表达式中的特殊符号:
content.xpath('//title/text()')
content.xpath('/feed/entry/title/text()')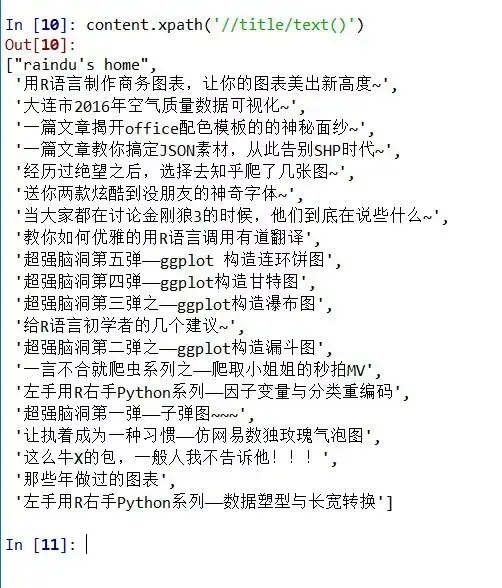



同样是第一个句子比第二个句子多输出一个title。
需要你随时分辨清楚“/”与“//”之间的区别,绝对路径与相对路径在取节点时非常重要。
content.xpath("//*/id/text()")
content.xpath("//entry/id/text()")

这里的*号指代所有可能的路径,因而第一句函数意思就是在所有可能的路径中搜寻具有子节点id的节点内容。
content.xpath("//*/id/text()| //*/title/text()")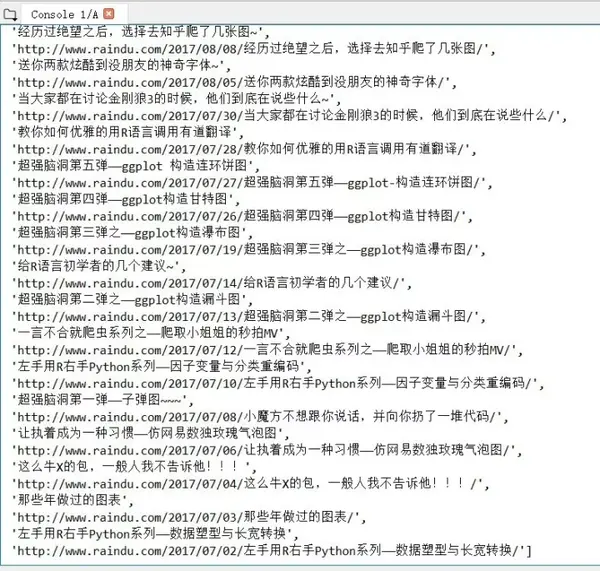

以上是依据多条件语法,可以将符合两个条件的所有条目全部取出!
2、文本谓语:
以上所有操作针对的都是节点以及节点值,而很多时候我们需要的不是节点值而是属性值,涉及到属性值捕获,则需要熟记文本谓语。
在原始文档中,每一篇本科中均有分类信息,我们想要找出含有ggplot2类别的节点并获取其链接,则公式可以写成如下形式。
content.xpath("//entry/category[@term='ggplot2']/@scheme")

如果这里不赋值,我们只是选择了所有含有term属性的节点的scheme属性内容,一共有82条之多。
content.xpath("//entry/category[@term]/@scheme")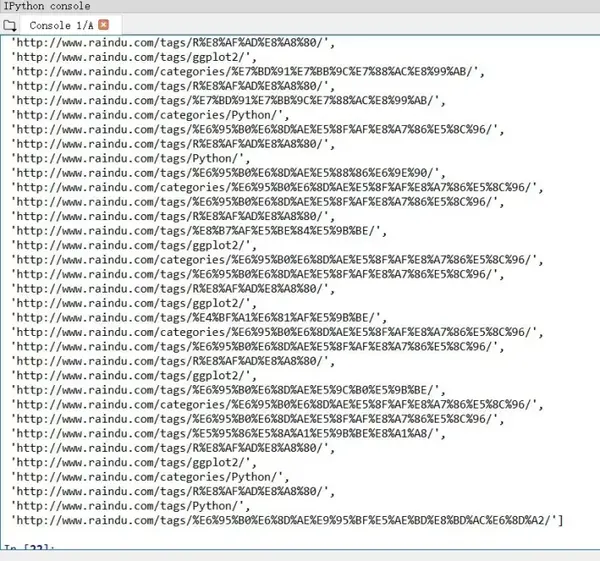

3、匹配操作:
文本谓语中可以执行特殊的匹配操作,功能类似于Excel中的left、right以及mid函数。就是匹配文本中以什么开始、结束或者包含有某些文本的记录。
我们主要关注XPath文本谓语的使用,其实非常简单,每一篇博客中结构都是如下这样,category是一个闭合节点,我们仅需定位到所有tern属性值为“ggplot2”的category节点并将其对应scheme捕获就OK了)。
<entry>
category term="R语言" scheme="http://www.raindu.com/categories/R%E8%AF%AD%E8%A8%80/"/>
<category term="数据可视化" scheme="http://www.raindu.com/tags/%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%86%E5%8C%96/"/>
<category term="R语言" scheme="http://www.raindu.com/tags/R%E8%AF%AD%E8%A8%80/"/>
<category term="ggplot2" scheme="http://www.raindu.com/tags/ggplot2/"/>
</entry>查找博客文章标题中含有ggplot的id并捕获。
content.xpath("//entry/id[contains(text(),'ggplot')]/text()")
#根据节点内容所含字符串进行提取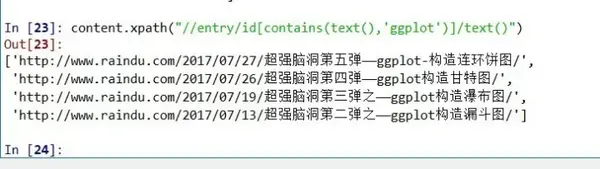

content.xpath("//entry/category[starts-with(./@term,'R')]/@scheme")
#提取属性值内容所含字符串"R"的条目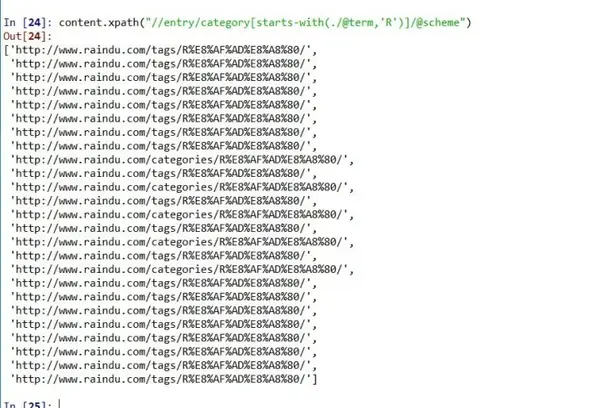

content.xpath("//entry/category[contains(./@term,'ggplot2')]/@scheme")
#根据属性值内容所含字符串进行提取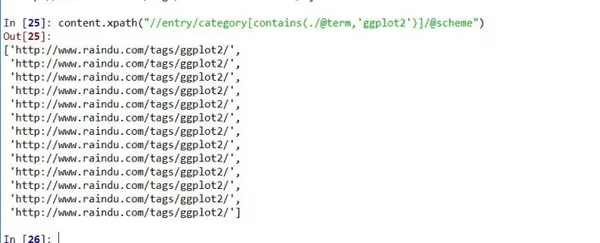

当然Python中也是支持全套的XPath语法,除此之外,还有很多lxml包的扩展语法,这些内容都将成为我们学习网络数据抓取过程中宝贵的财富,以上即是本次分享的全部内容,用好以上XPath表达式的三大规则(当然仅是所有表达式的中九牛一毛),你的网页解析能力一定可以提升的棒棒哒~
本文参考文献:
https://cran.r-project.org/web/packages/XML/XML.pdf
http://lxml.de/xpathxslt.html
在线课程请点击文末原文链接:
Hellobi Live | 9月12日 R语言可视化在商务场景中的应用
往期案例数据请移步本人GitHub: https://github.com/ljtyduyu/DataWarehouse/tree/master/File