
一文读懂语义分割与实例分割

以人工智能为导向的现代计算机视觉技术,在过去的十年中发生了巨大的变化。今天,它被广泛用于图像分类、人脸识别、物体检测、视频分析以及机器人及自动驾驶汽车中的图像处理等领域。图像分割技术是目前预测图像领域最热门的一项技术,原因在于上述许多计算机视觉任务都需要对图像进行智能分割,以充分理解图像中的内容,使各个图像部分之间的分析更加容易。 本文会着重介绍语义分割和实例分割的应用以及原理。
Email: williamhyin@outlook.com
知乎专栏: 自动驾驶全栈工程师
在开始这篇文章之前,我们得首先弄明白,什么是图像分割?
我们知道一个图像只不过是许多像素的集合。图像分割分类是对图像中属于特定类别的像素进行分类的过程,因此图像分割可以认为是按像素进行分类的问题。
那么传统的图像分割与今天的图像分割的区别在哪?
传统的图像分割算法均是基于灰度值的不连续和相似的性质。而基于深度学习的图像分割技术则是利用卷积神经网络,来理解图像中的每个像素所代表的真实世界物体,这在以前是难以想象的。
基于深度学习的图像分割技术主要分为两类:语义分割及实例分割。
语义分割和实例分割的区别又是什么?
语义分割会为图像中的每个像素分配一个类别,但是同一类别之间的对象不会区分。而实例分割,只对特定的物体进行分类。这看起来与目标检测相似,不同的是目标检测输出目标的边界框和类别,实例分割输出的是目标的Mask和类别。
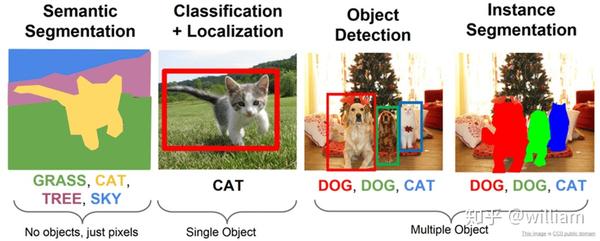

智能图像分割的应用
了解完图像分割的基本概念,我们来看看图像分割在实际中的应用有哪些?
由于图像分割技术有助于理解图像中的内容,并确定物体之间的关系,因此常被应用于人脸识别,物体检测, 医学影像,卫星图像分析,自动驾驶感知等领域。在我们生活中,图像分割技术的应用实例也很常见,如智能手机上的抠图相机,在线试衣间,虚拟化妆,以及零售图像识别等,这些应用往往都需要使用智能分割后的图片作为操作对象。
下面让我们来看看图像分割技术是怎么应用在这些实例上的。
人脸识别
人脸识别技术作为类别检测技术几乎被应用于每一台智能手机及数码相机上。通过这项技术,相机能够很快的检测并精确定位人脸的生物特征,实现快速自动聚焦。在定位人脸的生物特征后,算法还能够分割图像中人的五官及皮肤,实现自定义美颜,美容甚至实现换脸的效果。


抠图相机及肖像模式
谷歌最近发布了一个可以实时去除背景的 App: YouTube stories,通过分割图像中的前景和后景,内容创作者可以在创作故事时显示不同的背景。


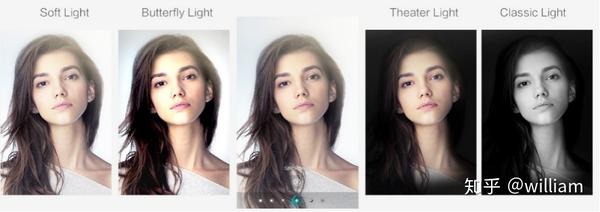
除了抠图相机外,手机相机中的肖像模式也是常见的图像分割应用。
如荣耀手机上的肖像打光模式,我们可以看到随着布光的角度和强度变化,除了图像的背景产生了显著的变化,人脸的细节,皮肤色彩,明暗度对比甚至阴影角度都产生了变化。这种惊艳的效果离不开精确的图像前后景及面部组分分割技术。

虚拟化妆
虚拟化妆常见于亚马逊,道格拉斯等美妆在线商城。在图像分割技术的帮助下,人们甚至不需要去专柜试色号,就可以直观的通过虚拟化妆功能看到模特或者自身使用不同化妆品组合的效果。可以预见,随着美妆市场的继续扩大,AR虚拟试妆会成为未来的一项趋势。


在线试衣间
虚拟化妆都能有了,虚拟试衣间肯定也不会少。在智能图像分割技术的帮助下,不用脱衣也能实现完美试穿。东芝的一款虚拟试衣间利用图像分割技术将二维图像创建为三维模型,并实现不同衣物与人体表面的完美叠合。


零售图像识别
图像分割技术还被广泛应用在零售及生产领域。零售商和生产商会将图像分割后的图片作为图像搜索引擎的输入,以便于理解货架上货物布局。这项算法能够实时处理产品数据,以检测货架上是否有货物。如果一个产品不存在,他们可以识别原因,警告跟单员,并为供应链的相应部分提出解决方案。


手写字符识别
手机上有很多手写文字提取的App,它们的原理绝大部分也是基于智能图像分割技术从手写文档中层层提取单词,来识别手写字符。


医学影像
图像分割技术在医学影像学中的应用,往往被很多外行人忽略。但是实际上在过去的十年中,智能图像分割技术几乎遍布医学影像学的各项检查中。不仅是因为医学图像分割能够准确检测人类不同部位的疾病的类型,例如癌症,肿瘤等,更重要的是它能够有助于从背景医学影像(例如CT或MRI图像)中识别出器官病变的像素,这是医学影像分析中最具挑战性的任务之一。


自动驾驶汽车
近几年,随着自动驾驶汽车的兴起,图像分割技术也被广泛应用在这一领域,目前主要被用来识别车道线和其他必要的交通信息,或者将图像语义分割的结果与激光传感器的点云数据做数据匹配,实现像素级的多传感器融合。


智能图像分割的任务描述
我们已经在上文中讨论了很多基于深度学习的图像分割技术的应用,现在让我们来看看这项技术的输出究竟是什么?
简单来说,图像分割技术的目标是输出一个 RGB 图像或单通道灰度图像的分割映射,其中每个像素包含一个整数类标签。
不同于目标检测输出的是目标整体的边界框和类别,语义分割输出图像中每个像素的类别,而实例分割输出的是目标的Mask和类别。
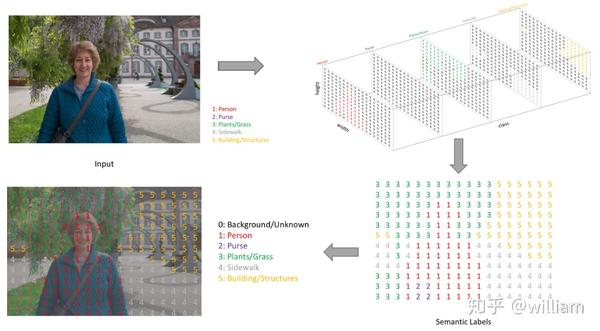
下面我们通过jeremyjordan的例子了解智能图像分割的输出是什么。
首先我们对左上的输入图片进行图像分割,预测图像中的每一个像素,为每个可能的类创建一个输出通道,使用 one-hot 对类标签进行编码(右上)。通过获取每个通道的argmax,可以将多通道的预测结果压缩为单通道分割图(右下)。当我们使用单通道分割图覆盖我们观察目标的单一通道时,图像中出现特定类的区域会被高亮,我们称之为掩膜(Mask)。我们可以将掩膜覆盖在观察目标上,来检查目标中的对象(左下)。值得注意的是,为了更容易了解图像分割的过程,作者使用了一个低分辨率的预测图做效果展示,而在实际的图像分割中,预测图会被Resize到原始输入图像的尺寸。

语义分割
在上文中,我们介绍了智能图像分割技术的任务究竟是什么,而接下来我们会介绍完成这项任务的方法。语义分割便是其中之一。
语义分割的目的是为了从像素级别理解图像的内容,并为图像中的每个像素分配一个对象类。

Semantic Segmentation by Patch Classification
基于像素块分类的卷积分割网络是最原始的智能图像分割网络,该算法将待分类像素周围的一个图像块作为卷积神经网络的输入,用于训练与预测。

paper:2012-Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images
作者采用滑窗预测的方法遍历整张图像的内容,将每一个滑动窗口内的像素块馈送到神经网络中进行类别预测,将预测结果的编码标注在原图像中的对应位置,以实现近似像素级的分割。
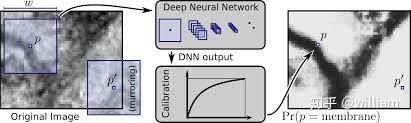
但是这种方法存在显而易见的缺点:
- 采用滑窗预测的方法,图像块的储存开销很大,并且窗口重叠区域存在重复计算,非常没有效率
- 像素块的大小限制了感受域, 只能提取局部特征,图像不同区域的特征无法共享,分类性能很受限
- 没有充分利用到图像的上下文
FCN for Semantic Segmentation
基于像素块分类的语义分割在结果上只是近似像素级的分割,如何实现完全的像素级分割是接下来的发展方向。
2015年J.Long 给出了当时全像素级分割的最佳解决方案,Fully Convolutional Network 全卷积神经网络。FCN在网络架构上不再使用全连接层,直接从抽象的特征中恢复每个像素所属的类别。这种端对端的网络架构,不仅在速度上远快于像素块分类的方式,而且能够适用于任何大小的图像。
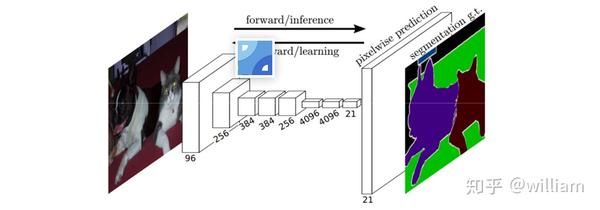

paper:2015-Fully Convolutional Networks for Semantic Segmentation
FCN的作者描述了一种Dense prediction的预测方式。这种方式的特点在于将VGG-16等传统卷积分类网络的最后几个全连接层都换成了卷积层,最终的输出结果不再是一维的类别概率信息,而是二维特征图中每个像素点的分类概率信息。
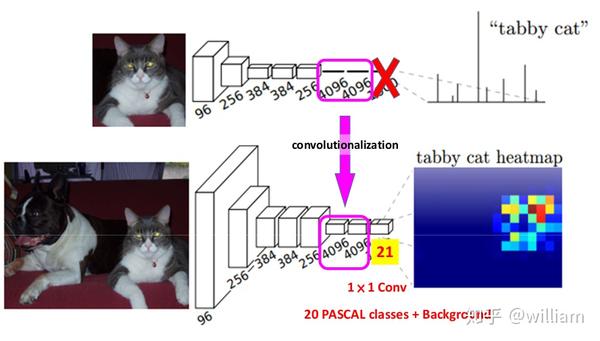

我们可以看到在上图中,作者删除了卷积分类网络的最后一层,并将之前几个全连接层都换成了卷积层,然后经过softmax层,获得每个像素点的分类概率信息。
那么问题来了,在上图中我们最终得到的二维特征图只有64x64的大小,如何保证我们输入和输出图像的尺寸一致?
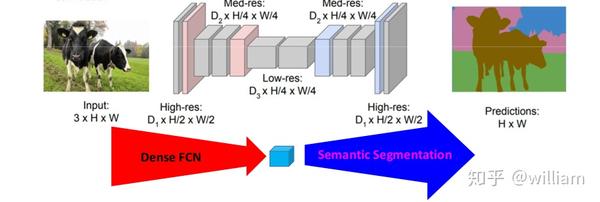

我们已经在Dense prediction的过程中实现了Downsampling,现在我们需要找到一个Upsampling的方式。
常见的Upsampling方案有两种:Shift-and-Stitch 和Bilinear Interpolation。
FCN的作者在这里给出了另外一种方案:转置卷积(Transpose Convolution)。通过转置卷积层和激活函数的堆栈,FCN可以学习非线性上采样。
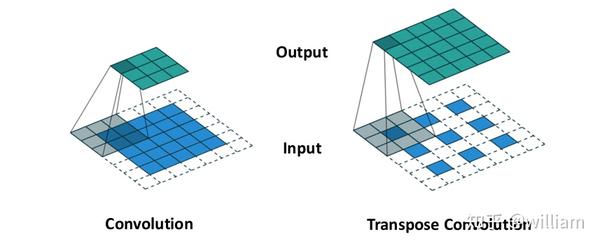

在有些研究中,这种操作又被称为反卷积(deconvolution),但是把转置卷积称作反卷积的说法有此不恰当。
转置卷积与反卷积的实际数学运算是不同的。反卷积在数学上做的是卷积的逆操作,而转置卷积进行规则卷积,但逆转其空间变换。
听起来有些令人困惑,我们来看下一个具体的例子。
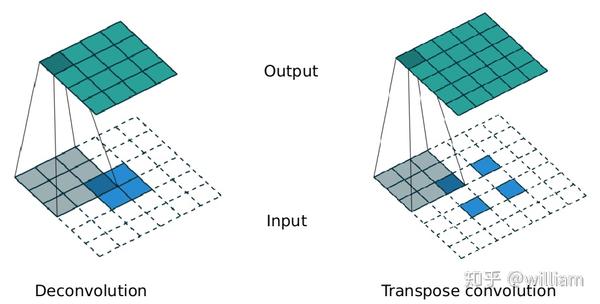

一个5x5图像输入到步长为2,无填充的3x3卷积层,这样就能得到一个2x2的图像。
如果我们想要逆转这个过程,我们需要逆数学运算,以便从我们输入的每个像素生成9个值。我们以步长为2的3x3卷积核遍历2x2的输入图像,最终输出4x4的图像。这就是反卷积。
而转置卷积要求输出一定是一个和正常卷积输入大小相同的图像,对于这个例子是5x5的图像。为了实现这一点,我们需要在输入上执行一些花哨的填充,即对2x2的输入特征矩阵进行内填充(如填充到3x3),使其维度扩大到适配卷积目标输出维度,然后才可以进行普通的卷积操作。
使用转置卷积能够从之前的卷积结果中重建空间分辨率。这虽然不是数学上的逆,但是对于编码器-解码器体系结构来说,它仍然非常有用。
现在我们来看看FCN的网络结构。


原始的FCN只在Conv6-7这一步直接进行32倍上采样的转置卷积,我们会发现输出的结果过于模糊。
那么我们如何改善这个结果呢?
这就得利用Resnet里面的skip-connection,融合不同网络层的输出信息,以获得更多的细节。在卷积神经网络中,低层网络往往有更多的细节信息,而高层网络具有更强的语义信息,但是对细节的感知能力较差。因此我们将Pool4层的输出与conv6-7上采样的结果相加,恢复到原图分辨率只需要16倍上采样。然后我们可以继续向更低层做信息融合,得到8倍上采样的结果,相比于FCN-32及16,FCN-8的结果更加精细。
总的来说,FCN作为语义分割的开山之作,无论是结构还是思路都值得后续的研究者借鉴。但是在输出结果方面还是有待提升,主要体现在即使FCN-8的输出结果还是不够精细,而且没有空间规整(spatial regularization)步骤,使得结果缺乏空间一致性,即没有充分考虑像素与像素之间的关系。
U-Net for medical engineering
生物医学对于视觉任务的要求往往很高,目标输出不仅要包括目标类别的位置,而且图像中的每个像素都应该有类标签。为了满足这些要求,Olaf Ronneberger 等人为生物医学专门开发了U-Net图像分割网络,通过使用更深的网络结构和跳层连接大幅提升了分割的精细度。
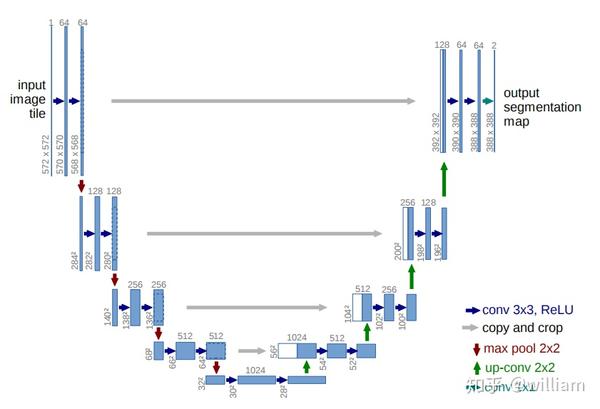

paper: 2015-U-Net: Convolutional Networks for Biomedical Image Segmentation
从上图中我们可以看到,U-Net的结构由左、右两部分组成,因为它的架构看起来像字母 U,因此被命名为 U-Net。U-Net包括一个收缩通道来捕获上下文,一个对称的扩展通道来恢复空间分辨率和一系列跨层连接来融合低层级的细节信息和高层级的语义特征,从而实现精确定位。U-Net可以根据数据集的复杂程度,通过增加和删减block来自由加深网络结构。值得注意的是U-Net的卷积过程没有Padding操作,需要选择适当的输入尺寸,使得每次池化的输入尺寸都是偶数,以确保分割的准确。
其实认真分析U-Net 和 FCN 的基本结构会发现,两者都是收缩通道和扩展通道的组合,但是还是存在一些结构上的区别。
其一是,U-Net没有使用VGG等ImageNet预训练的模型作为特征提取器,原因在于U-Net做的是医学图像的二值分割,与ImageNet的输出分类完全不同。
其二是,U-Net在进行特征融合的时候,采用的是Concat,而不是FCN中的Add。Concat是通道数的增加, Add是特征图相加,通道数不变。与Concat相比,Add的计算量少很多,但是Concat层更多用于不同尺度特征图的语义信息的融合,而Add较多使用在多任务问题上。
SegNet
FCN和U-Net,这两种网络基本上定义语义分割的基本架构,即降采样层/收缩通道和上采样层/扩展通道的组合。
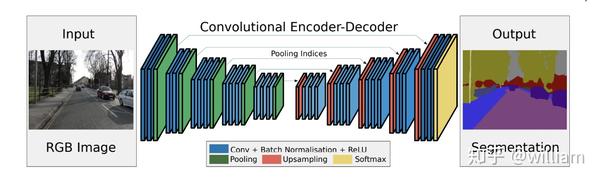

paper: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
SegNet 在FCN和U-Net的基础上,进一步优化了语义分割的网络结构,提出语义分割的模型由编码器Encoder和解码器Decoder组合,取代了收缩通道和扩展通道的说法,被后来的研究人员所引用。SegNet的编码器网络由13个卷积层组成,对应于 VGG16网络中用于对象分类的前13个卷积层。而解码器网络的任务是将编码器学习的低分辨率特征语义投影到高分辨率的像素空间上,得到一个像素级的密集分类。
值得注意的是,解码网络使用最大池化层索引进行非线性上采样,以生成稀疏的特征映射,然后通过可训练的卷积模块进行卷积,使特征映射更加密集。最终解码器输出的特征映射被提供给Softmax层进行逐像素分类。
那么最大池化层索引上采样与FCN的转置卷积层上采样区别在哪?


从上图中我们可以看到,使用池化层索引进行上采样最显著的一个优势就是减少训练的参数量,减少内存开销。其次可以提升边缘刻画度。并且这种上采样模式具有广泛适用性,可以被用在到任何编码解码器网络中。
DeepLab
我们在上文中已经讨论了FCN,U-Net和Segnet这些经典的语义分割网络,接下来我们会讨论代表着语义分割最前沿技术的Deeplab系列。
Deeplab是由谷歌研究人员开发的,目前被广泛应用的语义分割模型,它最重要的特性是以更低的计算成本获得更好的输出。
从2016年谷歌首次推出Deeplab V1,到最新的Deeplab V3+,已经三代半了。
本文将主要介绍Deeplab v3+。
我们首先来看看Deeplab V3+的由来。
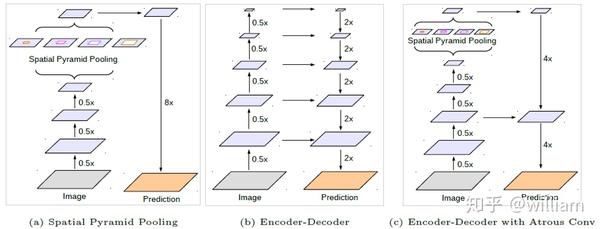
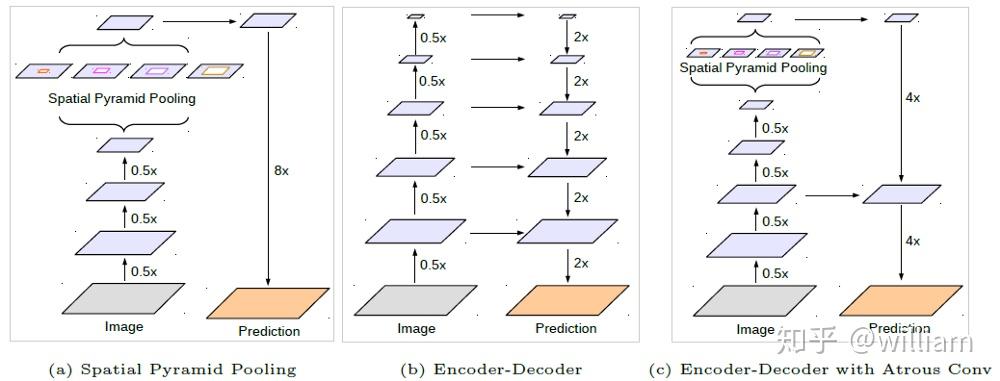
paper:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
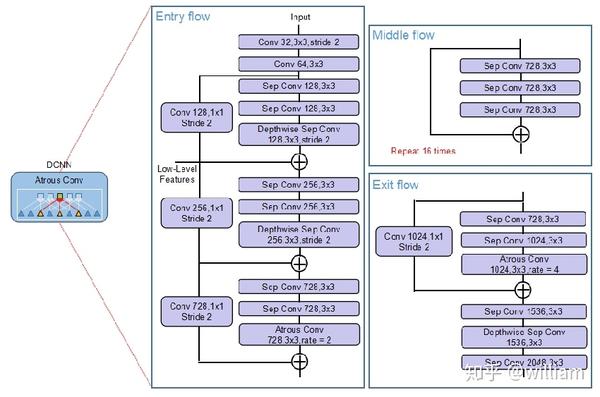
上图中a是SPP空间金字塔结构,b是在Segnet和U-Net上被广泛认可的Encoder-Decoder体系结构,而Deeplab v3+结合了a和b,并通过使用Modified Aligned Xception和Atrous Separable Convolution,开发出更快,更强大的网络。
下图是Deeplab v3+的网络结构。
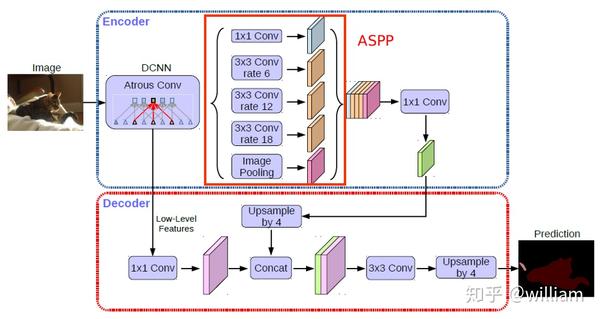
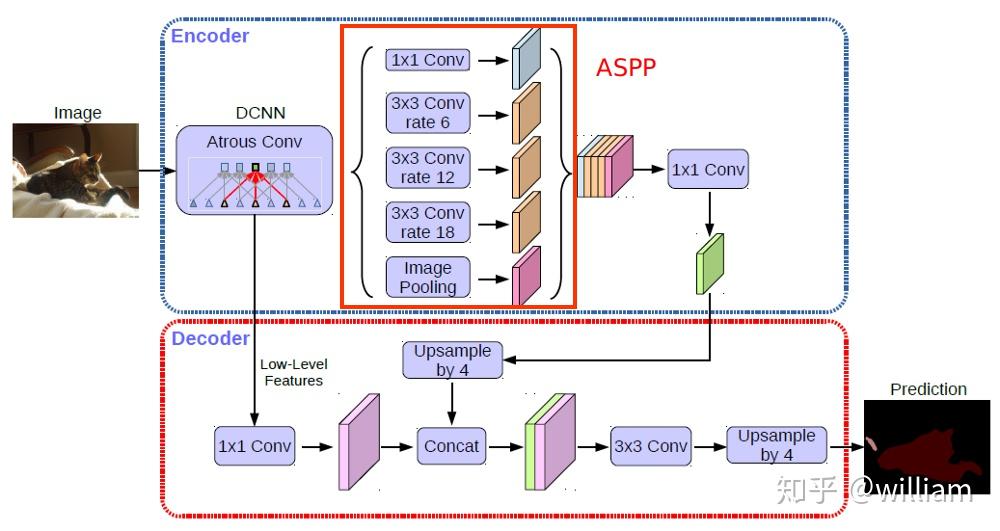
我们可以看到,Deeplab V3+由Encoder和Decoder两部分组成,相对于V3 最大的改进是将 DeepLab 的 DCNN及ASPP 部分看做 Encoder,将 ASPP的输出的高层语义特征与DCNN中低层高分辨率信息融合后上采样成原图大小的部分看做 Decoder 。值得注意的是,这里的上采样方式是双线性插值。双线性插值采样在较低的计算/内存开销下能给出相对于转置卷积上采样更好的结果。
接下来我们来看看Deeplab V3+的几个重要组成部分:
- Atrous convolutions
- Atrous Spatial Pyramidal Pooling(ASPP)
- Modified Aligned Xception
1. Atrous Convolution
在上文中,我们提到过,FCN通过对输入图像进行32倍下采样,再上采样得到语义分割的结果。但是这种操作的主要问题之一是由于DCNN(深度卷积网络)中重复的最大池化和下采样造成图像分辨率过度下降,图像细节信息丢失严重。此外,由于在学习上采样的过程中还涉及到其他参数,将采样数据上采样到32倍会是一项计算和内存开销很大的操作。
那么能否在相同的计算条件下,不用池化损失信息的方式增大卷积的感受野?
Deeplab的研究人员为此提出了一种新的下采样的思路:空洞卷积/扩展卷积(Atrous/Dilated convolutions)。空洞卷积能在相同数量的参数下,获得更大的感受野,从而避免在重复池化下采样的过程中图像分辨率过度降低,从而丢失细节信息。
让我们来看看空洞卷积是怎么在参数量不变的情况下,增大感受野的?
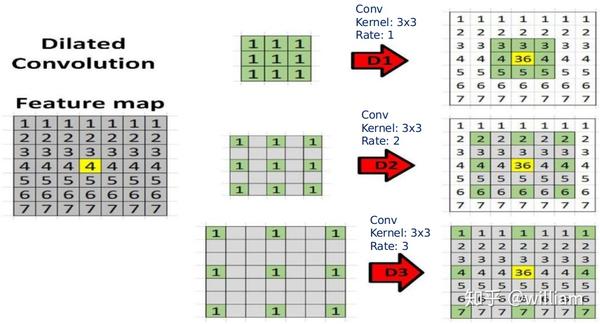

空洞卷积的工作原理是通过增加空洞来填补卷积核各值之间的空隙来增加卷积核的大小。卷积核各值之间填充的空洞数量称为扩张率(dilation rate)。当扩张率等于1时,它就是正常卷积。当速率等于2时,会在每个值之间插入一个空洞,使得卷积核看起来像一个5x5的卷积。换句话说,利用添加空洞扩大感受野,让原本3x3的卷积核,在相同参数量和计算量下拥有5x5(dilated rate =2)或者更大的感受野,从而无需下采样。
值得注意的是,在VGG中使用多个小卷积核代替大卷积核的方法,只能使感受野线性增长,而多个空洞卷积串联,可以实现感受野指数级增长。比如正常卷积中一个5×5的卷积核是可以由2次连续的3×3的卷积代替。但是对于同样是3x3大小,dilated=2的空洞卷积来说,连续2层的3×3空洞卷积转换却相当于1层13×13卷积。
2. Atrous Spatial Pyramidal Pooling(ASPP)
空间金字塔形池化是SPPNet中引入的一个概念,用于从特征图中捕获多尺度信息。在SPP出现之前,如果想要获取多尺度信息,需要提供不同分辨率的输入图像,并将计算出的特征图一起使用,这往往需要很多计算和时间成本。而使用空间金字塔形合并,可以使用单个输入图像捕获多尺度信息。下图是SPPNet的结构图。


SPPNet产生3个尺度分别为1x1、2x2和4x4的输出。通过将这些值转换为一维矢量进行连接,从而在多个尺度上捕获信息。
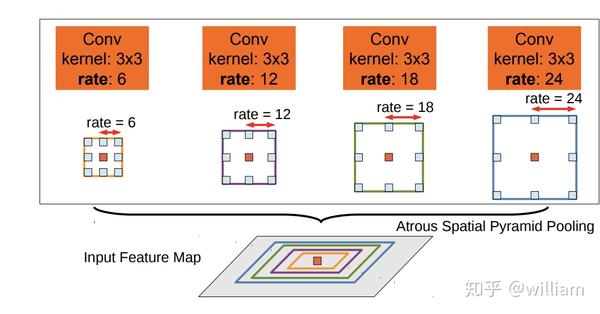
Deeplab 系列为了使得目标在图像中表现为不同大小时仍能够有很好的语义分割效果,将多尺度的信息融合的概念应用于空洞卷积,通过将不同的扩张率空洞卷积的输出串联在一起,以多个尺度比例捕捉图像的上下文,即ASPP。

值得注意的是,Deeplab v3+ 借鉴了MobileNet,在ASPP及DCNN中的Xception模块都使用深度可分离卷积(depthwise separable convolution),在保持性能前提下,有效降低了计算量和参数量。


Deeplab V3+对V3的ASPP结构进行了修改,最终的ASPP结构如下图所示。
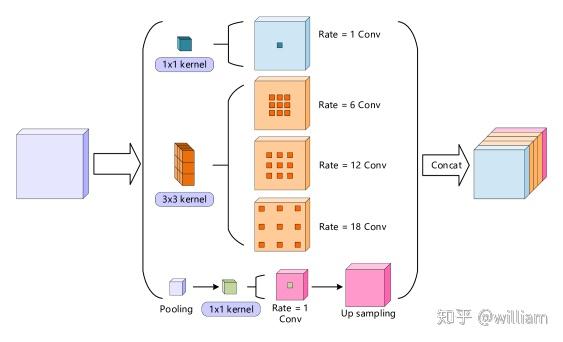

除了3x3不同扩张率的空洞卷积及1x1的卷积输出外,为了提供全局信息,还会将1x1的GAP上采样后添加到空间金字塔上。
3. Modified Aligned Xception
Deeplab v3+的主干使用Modified Aligned Xception。Xception是经典的图像分类网络,然后在可变形卷积网络(Deformable Convolutional Networks)中引入了Aligned Xception以进行目标检测。而Modified Aligned Xception 在此基础上进行了进一步的优化。
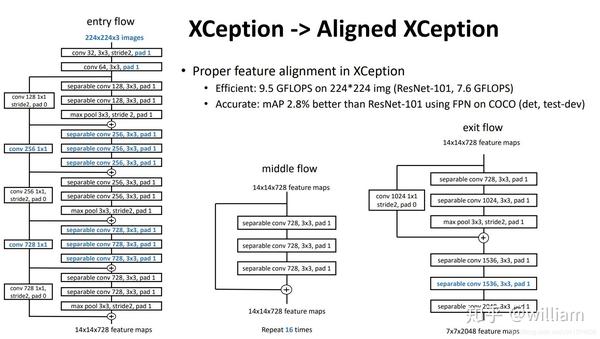

上图是Aligned Xception, 下图是Modified Aligned Xception。
我们发现改进的地方主要在于,采用深度可分离卷积替换所有的最大池化操作,从而方便后续利用空洞可分离卷积(atrous separable conv )来提取任意分辨率的特征图。其次在每个 3×3 深度卷积后,添加和MobileNet类似的额外的批处理归一化和ReLU激活。

实例分割
在上文中,我们已经讨论了很多语义分割的网络模型。借助这些模型我们能够从像素级别理解图像,并准确分割对象的形状。
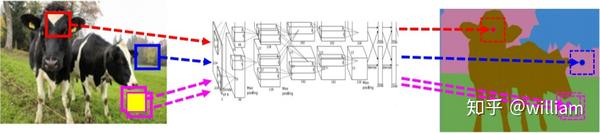
比如在下图中,我们能够通过语义分割有效地区分牛和背景。


但是问题来了,你能区分上面的图片中有几头牛吗?
仅凭语义分割显然不能回答这个问题,下面让我们看看实例分割是怎么做到区分同一类别中不同物体的。
Mask R-CNN
Mask R-CNN是实例分割的代表之作。
如下图所示,Mask R-CNN 对于分割同一类别中不同物体,给出的答案是同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的Mask抽取出来。


paper:Mask R-CNN
Mask R-CNN的基础其实是Faster R-CNN。Faster R-CNN使用 CNN 特征提取器来提取图像特征,利用 Region Proposal 网络生成感兴趣区域(ROI),并通过ROI Pooling将它们转换为固定的维度,最后将其反馈到完全连接的层中进行分类和边界框预测。
而Mask R-CNN与Faster R-CNN 的区别在于,Mask R-CNN在Faster R-CNN 的基础上(分类+回归分支)增加了一个小型FCN分支,利用卷积与反卷积构建端到端的网络进行语义分割,并且将ROI-Pooling层替换成了ROI-Align。下图是Mask R-CNN 基于Faster R-CNN/ResNet的网络架构。
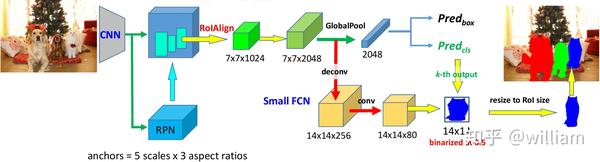

Mask R-CNN首先将输入原始图片送入到特征提取网络得到特征图,然后对特征图的每一个像素位置设定固定个数的ROI/Anchor(默认15个),将这些ROI区域馈送到RPN网络进行二分类(前景和背景)以及坐标回归,找出所有存在对象的ROI区域。紧接着通过ROIAlign从每个ROI中提取特征图(例如7*7)。最后对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
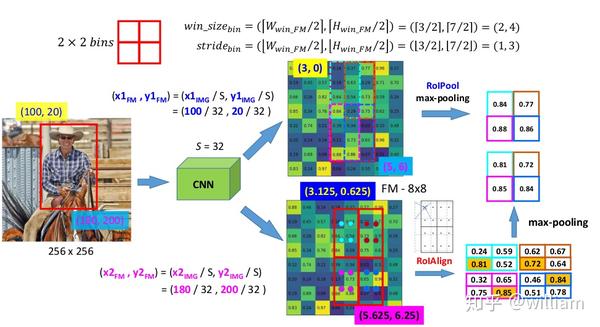
对ROIAlign的理解得从ROI-Pooling出发。为了得到固定大小(7X7)的特征图,一般我们需要做两次量化操作:1)图像坐标 — feature map坐标,2)feature map坐标 — ROI feature坐标。池化操作的输出值只能是整数,RoI Pooling进行两次取整损失了较多的精度,而这对于分割任务来说较为致命。Maks R-CNN提出的RoI Align取消了取整操作,保留所有的浮点数,然后通过双线性插值的方法获得多个采样点的值,再将多个采样点进行最大值的池化,即可得到该点最终的值。
下图是ROI-Pooling和ROIAlign的计算对比。

对于推理过程,我们还需要将14x14的Mask二值化后Resize到原图中的实际大小,但是实际上这一结果其实并不精细。
为此作者设计了另外一种Mask R-CNN网络结构:Faster R-CNN/FPN,并将最后的输出的Mask分辨率提升到28x28。FPN特征金字塔网络通过融合低层网络的高分辨率信息和高层网络的高语义特征,大幅提升多尺度物体及小物体的检测效果,使得Mask R-CNN的输出结果更加精细。
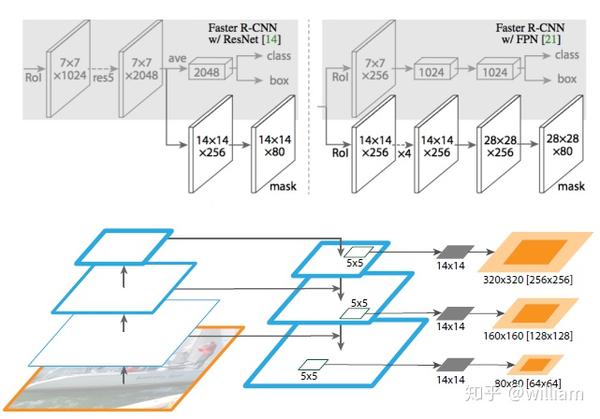

总的来说,Mask R-CNN是个非常简单,灵活并适用于多种场景的实例分割框架。但是Mask R-CNN比较依赖目标识别部分的结果,一旦目标识别不准确,实例分割的结果也会不精确。
语义分割对于分割的精度和效率都有很高的要求,由于实例分割在语义分割的基础上,还需要区分出同一类的不同的个体,因此实例分割同样有着精度和效率的要求。除此之外还面临着和语义分割相似的问题和难点,如深层网络小物体分割细节丢失的问题,如何处理几何变化,处理遮挡,甚至由于源图像被光照射,被压缩带来的图像退化问题。
为了解决速度和效率的问题,后续研究人员还推出了Instance FCN这种单阶段实例分割网络(Single Shot Instance Segmentation)。尽管单阶段分割网络在精度上不如双阶段分割网络,但是其在速度及模型大小方面仍远优于双阶段网络,因此单阶段网络引领了近些年实例分割及目标识别的研究潮流。
令人激动的是,近几年除了出现基于One-stage,Anchor-based的YOLACT和SOLO外,还出现了受到Anchor-free思路启发的PolarMask和AdaptIS等实例分割网络。这些Anchor-free的实例分割网络,也很出色。我会在接下来的几篇文章中更新Anchor-free网络,感兴趣的同学,可以关注我的专栏。
图像分割数据集
在最后一节中我会分享一些常见的图像分割的数据集,来满足不同领域朋友的研究需求。
Coco Dataset: 拥有164k 的原始 COCO 数据集图像,并附有像素级注释,是一个常用的基准数据集。它包括172个类: 80个thing class,91个stuff class和1个unlabeled class。
Link : http://cocodataset.org/
PASCAL Context: 是2010年 PASCAL VOC 的一组扩展注释。它为整个场景提供了注释,包含400多个真实世界数据。
Link : https://cs.stanford.edu/~roozbeh/pascal-context/
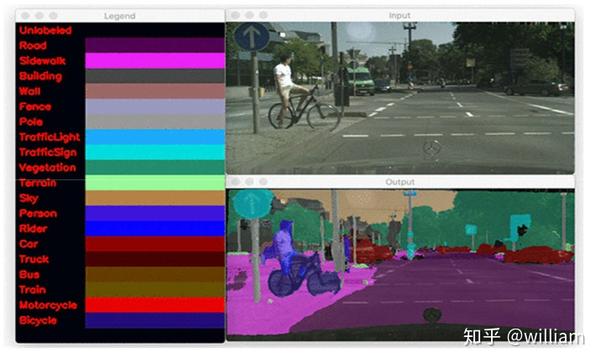
The Cityscapes Dataset:包含30个类别和50个城市的城市场景图像。用来评价城市场景中自动驾驶汽车的视觉算法性能。KITTI 和 CamVid 是类似的数据集,但是数据量相对较小,可以用来训练自动驾驶汽车。
Link : https://www.cityscapes-dataset.com/
Bdd100k: 包含10000多张具有丰富城市道路实例的像素级注释图像,拍摄自不同的时间,天气和驾驶场景,可以用来训练自动驾驶汽车。
Link: https://bdd-data.berkeley.edu/
Lits Dataset:为了从肝脏 CT 中识别出肿瘤病变而创建的医学影像数据集。该数据集包括130张训练用CT图和70张测试CT图。
Link : https://competitions.codalab.org/competitions/17094
CCP Dataset:包含1000多张带有像素级注释的服装搭配图片,总共有59个类别。
LInk: https://github.com/bearpaw/clothing-co-parsing
ADEK20K:包含2万张图片,100个thing class 和50个stuff class的像素级注释场景数据集。
Link: https://groups.csail.mit.edu/vision/datasets/ADE20K/
Pratheepan Dataset:包含32张脸部照片和46张家庭照片的皮肤分割数据集。
Link: http://cs-chan.com/downloads_skin_dataset.html
除上述常见的之外,还有以下种类繁多的图像分割数据集。
- Stanford Background Dataset
- Sift Flow Dataset
- Barcelona Dataset
- MSRC Dataset
- LITS Liver Tumor Segmentation Dataset
- Data from Games dataset
- Human parsing dataset
- Mapillary Vistas Dataset
- Microsoft AirSim
- MIT Scene Parsing Benchmark
- INRIA Annotations for Graz-02
- Daimler dataset
- ISBI Challenge: Segmentation of neuronal structures in EM stacks
- INRIA Annotations for Graz-02 (IG02)
- Inria Aerial Image
- ApolloScape
- UrbanMapper3D
- RoadDetector
- Inria Aerial Image Labeling
智能图像分割的未来
在计算机视觉领域,图像识别这几年的发展非常迅速,图像识别技术的价值也迅速体现在我们的身边,视频监控,自动驾驶,智能医疗等等。我们面临的挑战,除了提高模型的泛化能力,少样本学习,超大数据规模利用,还有一项便是更加全面的场景理解。
我们在本文中提到的语义分割,实例分割都是实现全面场景理解的一小步,未来图像分割领域的发展趋势,除了更精准的定位和分类,更高的效率,更少的训练标签,还有更统一和全面的分割方式,如全景分割(panoptic segmentation)。要实现全面场景理解的目标,我们还有很长的路要走,我也会继续更新智能图像分割领域的知识和文章,和大家一起学习:)
我会在接下来的文章中,分享基于Efficientdet和Detectron2的自动驾驶目标检测及图像分割项目实践。
欢迎大家订阅~
也可以点击关注我的专栏, 自动驾驶全栈工程师, 我会定期分享自动驾驶相关的技术知识~
如果有什么疑问, 可以随时联系我的个人邮箱, 文章下评论可能回复不及时。
如果你觉得我的文章对你有帮助, 请帮忙点个赞~\(≧▽≦)/~
转载请私信作者!
引用:
- Fully Convolutional Networks for Semantic Segmentation
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- Mask R-CNN
- jeremyjordan
- Nanonets
