【object detection】目标检测之SSD

前文提过,RCNN,SPP-NET,Fast-RCNN,Faster-RCNN之类的算法是基于RPN+分类的算法,均为two stage,无法达到实时性,本文介绍的SSD以及之后的YOLO系列,都是one stage。
SSD在保证速度和精度情况下,使用 single deep neural network,直接预测bounding box的坐标和类别的object detection算法。
算法的结果:对于300*300的输入,SSD可以在VOC2007 test上有74.3%的mAP,速度是59 FPS(Nvidia Titan X),对于512*512的输入, SSD可以有76.9%的mAP。相比之下Faster RCNN是73.2%的mAP和7FPS,YOLO是63.4%的mAP和45FPS。
下图是作者在eccv2016做的报告图片:


本文主要贡献:
- 论文发表时是最快的目标检测方法。比YOLO更快更精准(YOLO9000已经提速了)。精度逼急Faster RCNN。
- SSD 方法的核心就是 predict object(物体),以及其归属类别的 score(得分);同时,在 feature map 上使用小的卷积核,去 predict 一系列 bounding boxes 的 box offsets。(SSD也产生了一些anchor boxes,但是一气呵成)
- 本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。(但是,SSD对于小目标预测还是有天然的缺陷)
- 本文提出的模型(model)在不同的数据集上,如 PASCAL VOC、MS COCO、ILSVRC, 都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前(论文发表时)物体检测领域 state-of-art 的检测方法进行了比较。
网络架构
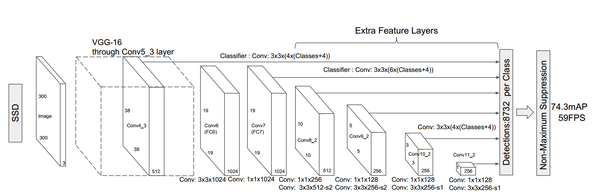



SSD 是基于一个前向传播 CNN 网络,产生一系列固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个非极大值抑制(Non-maximum suppression ,NMS)得到最终的 predictions。
SSD 模型的最开始部分,本文称作 base network,是用于图像分类的标准架构:VGG16。在 base network 之后,本文添加了额外辅助的网络结构:
(1), 使用 multi-scale feature maps 来detect,
(2), Convolutional predictors , 没有采用FC layer,这样可以适用于各种size的image,对于一个NxMxP的feature map, prediction detection 是 3x3xP的small kernel
(3),利用filter作为classifier 和 regressor,来对feature map的每一个pixels所在的位置是否object并且判断bbox相对于ground true的offsets。此时,filter将classifier和regressor结合起来,所以产生了filter产生的vector的维度是 (c + 4) x K, 其中c是categories number, 4 是bbox相对于ground true的4个offsets,k值是不同aspect和scale的bbox的数量。
这里的 default box 很类似于 Faster R-CNN 中的 Anchor boxes,关于这里的 Anchor boxes,详细的参见源代码。
training
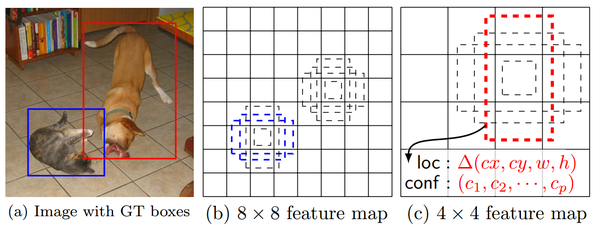
在训练时,本文的 SSD 与那些用 region proposals + pooling 方法的区别是,SSD 训练图像中的 groundtruth 需要赋予到那些固定输出的 boxes 上。在前面也已经提到了,SSD 输出的是事先定义好的,一系列固定大小的 bounding boxes。
如下图中,狗的 groundtruth 是红色的 bounding boxes,但进行 label 标注的时候,要将红色的 groundtruth box 赋予 图(c)中一系列固定输出的 boxes 中的一个,即 图(c)中的红色虚线框。

(未成,待修改)
参考文献:
1、intro: ECCV 2016 Oral
2、arxiv: http://arxiv.org/abs/1512.0232
3、slides: http://www.cs.unc.edu/%7Ewliu/papers/ssd_eccv2016_slide.pdf
4、github: https://github.com/weiliu89/caffe/tree/ssd
5、video: http://weibo.com/p/2304447a2326da963254c963c97fb05dd3a973
6、github(MXNet): https://github.com/zhreshold/mxnet-ssd
7、github: https://github.com/zhreshold/mxnet-ssd.cpp
8、github(Keras): https://github.com/rykov8/ssd_keras
