
循环神经网络学习笔记

前言:本文主要结合CMU CS 11-747(Neural Networks for NLP)课程中Recurrent Networks for Sentence or Language Modeling章节的内容进行讲解。本文主要包括了对如下几块内容的讲解,第一部分是循环神经网络相关的基本概念和变种架构的介绍,第二部分结合循环神经网络在自然语言处理相关研究做介绍,第三部分进行总结和分享几个相关的问答。
说明:递归神经网络(RNN),是两种人工神经网络的总称,一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)。时间递归神经网络,也称循环神经网络,本文后述RNN均指代循环神经网络。
本文作者:何高乐,2014级本科生,目前研究方向为网络表示学习、深度学习,来自中国人民大学大数据管理与分析方法研究北京市重点实验室。
备注:本文首发于知乎[RUC智能情报站],如需转载请告知作者并注明本专栏文章地址
一、循环神经网络(RNN)相关基本概念和两种重要架构
1、基本概念和Simple RNN
在自然语言处理的各项任务中,序列建模无处不在:从字符级别刻画单词,从单词级别刻画句子、文档等。在序列中,依赖现象较为明显,如主谓依赖、名词与动词单复数的依赖。在较短范围内,这种依赖能够被传统的语言模型(如n-gram,神经语言模型)刻画,但是长距离依赖则是传统语言模型难以刻画的。长距离依赖是序列建模的重要刻画内容之一,从下面的例子看长距离依赖:


为刻画长距离依赖,模型需要将输入的任意长度序列编码为包含序列信息的固定长度特征向量。RNN则正是此类模型的高度抽象:
给定任意长度有序特征序列 x_{1:n} = x_1,x_2,...,x_n(x_i \in R^{d_{in}}) ,RNN将返回固定长度特征向量 y_{n} \in R^{out} (其中 x_{i} 可为one-hot表示或者稠密低维特征)。RNN采取了递归式的定义:具体到序列信息的刻画过程,在刻画前 i 个元素组成的部分序列时,RNN引入了隐藏状态 s_i 作为前一隐藏状态 s_{i-1} 和当前元素 x_{i} 的输出,即 s_{i} = R(s_{i-1},x_i) ;最终输出到固定长度的特征向量则是通过映射 O(·) 将最终的状态 s_{n} 映射到 y_{n} 。(中间状态 s_i 均可通过映射 O(·) 输出 y_i )
\begin{split} RNN(x_{1:n};s_{0}) &= y_{1:n}\\ y_i &= O(s_{i})\\ s_{i}&=R(s_{i-1},x_i) \end{split} \\
此类模型图示如下:
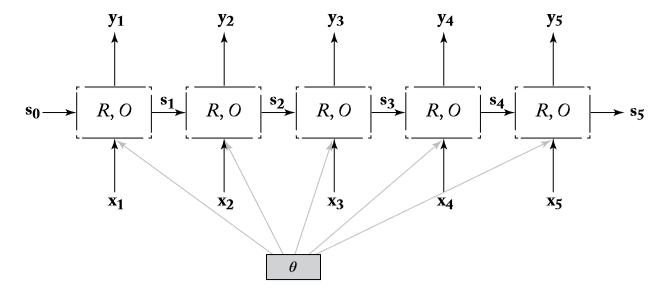

基于上述定义,连续词袋(CBOW)模型能够如下表述:
\begin{split} s_i &= R_{CBOW}(x_i, s_{i-1}) = s_{i - 1} + x_i\\ y_i &= O_{CBOW}(s_i) = s_i \end{split} \\ s_i,y_i \in R^{d_s}, x_i \in R^{d_s}
连续词袋模型能够将任意长度序列编码为固定长度特征,但是忽略了序列的顺序信息。而循环神经网络则能既能保留序列的顺序信息,又能将任意长度的序列编码为固定长度的特征向量;因此RNN被广泛应用于自然语言处理涉及序列建模的各类任务中。
1990年Elman提出了Simple-RNN模型,简记为S-RNN,可如下表述:
\begin{split} s_i &= R_{SRNN}(s_{i - 1},x_{i}) = g([s_{i-1};x_i]W + b)\\ y_i &= O_{SRNN}(s_i) = s_i \end{split} \\ s_i,y_i \in R^{d_s},x_i \in R^{d_x}, W \in R^{(d_x +d_s)×d_s}, b \in R^{d_s}
与CBOW模型相比,S-RNN仅复杂了一些,表现在把当前输入的状态和元素表示线性变换后通过非线性激活函数得到新的状态。正是这个差异,使得S-RNN对于序列的排序信息敏感。
2、S-RNN的不足和解决方法
由于梯度消失问题,S-RNN很难捕获长期依赖的特征,也很难得到有效训练。为了解决这个问题,基于门机制(gating mechanism)的RNN变种架构被提出。其中最出名的是LSTM(Long Short Term Memory)和GRU(Gated Recurrent Unit)。
2.1 LSTM
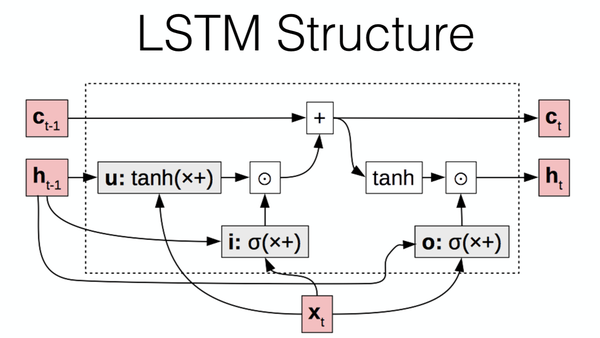

如上图所示,LSTM将RNN的隐藏状态 s_i 分为两个部分,记忆细胞(memory cells) c_t 和工作记忆(working memory) h_t 。记忆细胞负责序列特征的保留,由遗忘门 f (对应上图的u)控制此前序列的记忆 c_{t-1} 将被保留;工作记忆 h_t 则作为输出,由输出门 o 控制当前记忆 c_t 被写出的部分。输入门i则负责控制由此前状态信息 h_{t-1} 和当前输入 x_t 将被写入记忆细胞的部分。值得一提的是,在LSTM中上述三种门均不是静态的,其由此前状态信息 h_{t-1} 和当前输入 x_{t} 共同决定,通过对其线性组合后非线性激活得到。LSTM架构可如下定义:
\begin{split} s_j &= R_{LSTM}(s_{j-1},x_j)=[c_j;h_j]\\ c_j &= f \odot c_{j-1} + i \odot z\\ h_j &= o \odot tanh(c_j)\\ i&= \sigma(x_jW^{xi} + h_{j -1}W^{hi})\\ f &= \sigma(x_jW^{xf} + h_{j -1}W^{hf})\\ o &= \sigma(x_jW^{xo} + h_{j -1}W^{ho})\\ z &= \sigma(x_jW^{xz} + h_{j-1}W^{hz})\\ y_j &= O_{LSTM}(s_j) = h_j\\ s_j \in R^{2d_h},&x_i \in R^{d_x}, c_j,h_j,i,f,o,z \in R^{d_h} \end{split} \\
2.2、GRU
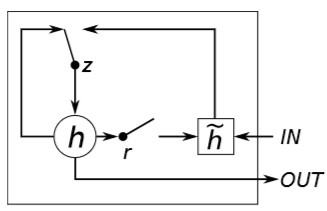
如上图所示,GRU包含了两个门——重置门r和更新门z。更新门z决定此前状态信息 s_{t-1} (对应图中 h )和当前状态的成员激活函数 \widetilde{s}_{j} (对应图中 \widetilde{h} )将被写入当前状态信息 s_t 。重置门r决定此前状态信息对当前输入的影响(在形成成员激活函数时)。与LSTM中一致,GRU的两个门也由此前状态信息和当前输入共同决定,通过对其线性组合后非线性激活得到。GRU架构可如下定义:
\begin{split} s_j &= R_{GRU}(s_{j-1},x_j)=(1-z) \odot s_{j-1} + z \odot \widetilde{s}_{j}\\ z &= \sigma(x_jW^{xz} + s_{j -1}W^{sz})\\ r &= \sigma(x_jW^{xr} + s_{j -1}W^{sr})\\ \widetilde{s}_{j} &= \sigma(x_jW^{xs} + (r \odot s_{j-1})W^{sg})\\ y_j &= O_{GRU}(s_j) = s_j\\ s_j,&\widetilde{s}_{j} \in R^{d_s},x_i \in R^{d_x}, z,r \in R^{d_s}\end{split}\\
3、两种架构的异同对比
3.1、相同点
最为显著的是,为了克服梯度消失(vanishing gradient),它们的隐藏状态都有来自此前状态的直接加和(通过门控制)。这样做的好处是:(1)便于神经元保留较长序列中某些特征(2)加和成分便于反向传播计算。其次,LSTM中和GRU均将此前状态信息( c_{j-1} 和 s_{j - 1} )和成员函数结合( z 和 \widetilde{s}_{j} )写入当前状态( c_j 和 s_j );并根据此前状态信息和当前输入动态生成门,控制信息传递。
3.2、不同点
LSTM用输出门控制当前记忆细胞输出的部分信息,而GRU直接将当前状态输出。LSTM中输入门控制成员函数对于当前记忆细胞的生成,而与之对应的GRU的重置门则是对生成成员函数产生影响。当重置门关闭(置0)时,可认为此前状态信息对当前成员激活函数无影响,此时类似于在当前位置重新回归初始状态,仅考虑当前输入带来的影响。
二、循环神经网络在自然语言处理相关应用
1、基本分类
循环神经网络在自然语言处理中按用途可分为两类,第一类是对整个序列的建模,第二类是对序列中上下文的建模。
对整个序列的建模得到的特征向量可用于构建句子分类器,也可用于条件生成(通过RNN编码得到固定长度特征向量,再解码生成新的序列)。
对上下文建模,将序列某一特定位置前的部分序列作为上下文,根据所得隐藏对当前位置做预测、标记等,常见于语言模型和序列标记。双向RNN(Bi-RNN)在建模上下文方面取得了较好的成果。
2、应用实例
本节主要结合《On the Properties of Neural Machine Translation: Encoder–Decoder Approaches》一文介绍RNN在序列建模的实际应用。该文针对机器翻译(machine translation)任务,应用当时新兴的神经翻译模型(neural machine translation),采取Encoder–Decoder模式完成从法语到英语的翻译。
首先,明确机器翻译的刻画目标:通过模型刻画任意目标句 f 在给定源句 e 下的条件概率 P(f|e) 。该文的主要思路是通过编码器对边长句子抽取固定长度的特征表示,然后用解码器据此生成正确的翻译。RNN作为解码器根据编码器生成向量生成变长序列作为翻译结果,该文的编码器则分别采用了GRU-based RNN 和 grConv(Gated Recursive Convolutional Neural Network)模型。GRU-based RNN可参照前章2.2小节定义,此处我们将介绍结合RNN门机制的特殊卷积模型grConv。
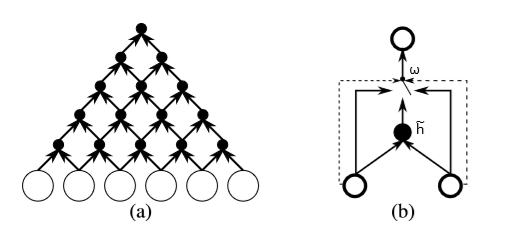

如上图(b)所示,grConv模型采用了类似RNN神经元的门机制对序列中邻近节点做卷积,并将卷积得到的节点作为新的序列继续做相同操作直至得到唯一节点(此过程中的所有节点均为固定长度的向量)。此模型颇具新意,结合了卷积神经网络和循环神经网络的特点,能够将变长序列编码为固定长度的特征向量(见上图(a))。
三、总结/Q&A
本文首先描述了循环神经网络的抽象、引出。为弥补S-RNN的不足——梯度消失问题,学者提出了两种RNN变种框架LSTM和GRU,本文对其定义和结构做了分析和对比。最后根据RNN的用途分类,并举例分析了RNN在机器翻译的实际应用。
此外,和大家分享学习过程中的的几个问题。
1、对于序列中某位置上下文进行建模时,Bi-RNN较单向RNN有何优势?
(1)包含了更加丰富的信息(不仅来自前述序列,也来自后续序列)
(2)能够刻画更加复杂的依赖性(如在字符级别序列建模预测单词时,Bi-RNN考虑了前缀和后缀信息)
2、S-RNN在序列建模时为何会出现梯度消失(vanishing gradient)?
理论上讲,RNN中的t时刻的损失函数与前述序列均相关,通过链式法则求导可以发现导数呈指数函数形式(大多数时候呈下降趋势)。图示如下:


3、对于序列建模的特定任务,为什么要预训练或者迁移训练RNN?
一些较为困难的序列建模任务数据量小、难于训练,此时通过对相关的相对简单任务(数据量大,易于训练)预训练得到的参数能够有效地加速和平稳困难任务的参数训练过程。如预训练语言模型,然后用于学习句子分类器(sentence classifier)或者情感分析(sentiment analysis)。
四、参考文献:
Semi-supervised Sequence Learning(pre-training/transfer RNN)
LSTM(Long Short Term Memory)
GRU(Gated Recurrent Unit)
On the difficulty of training Recurrent Neural Networks(梯度消失)
On the Properties of Neural Machine Translation: Encoder–Decoder Approaches
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
