
Notes on Unsupervised Neural Machine Translation

免责声明:本文需要一定 seq2seq/机器翻译的背景知识才能读懂。
今天看到一篇论文(ICLR 在审),非常厉害地做到了无监督学习两种语言之间的翻译,不需要依赖任何平行语料(其实这里有一点夸大的成分:本文需要用两份单语语料里的阿拉伯数字做种子,不算完全的无监督,严格讲应该是弱监督。另外,加入少量平行语料可以明显提升性能)。arXiv 地址见:
UNSUPERVISED NEURAL MACHINE TRANSLATION
(补:FAIR 也出了一篇几乎一模一样的文章 UNSUPERVISED MACHINE TRANSLATION USING MONOLINGUAL CORPORA ONLY,解读见文章后半部分。两个团队想法撞车了……)
大致流程如下:
1、先用单语语料训练两个词向量空间,然后用无监督方法对齐这两个空间。具体做法参照 Learning bilingual word embeddings with (almost) no bilingual data(也是本文作者之前的工作)。说是无监督,其实也是有监督的:具体做法是用阿拉伯数字做种子词对,把两个空间里的这些种子词的向量学一个线性变换对齐。最后再迭代几轮就能把两个空间对齐得很好了,从空间导出的双语 lexicon 有大约 40% 的准确率。反正不管什么语言的单语语料里都很可能有数字,这种对齐词典的获取几乎是无成本的。数字的定义是符合正则表达式 [0-9]+ 的 token,因此可能包含比纯数值更多的信息,比如说某个年份发生了某个重大事件、某个数字是 XXX 热线的电话等。
2、模型结构如下图, 两种语言共用一个 encoder,各有各的 decoder:
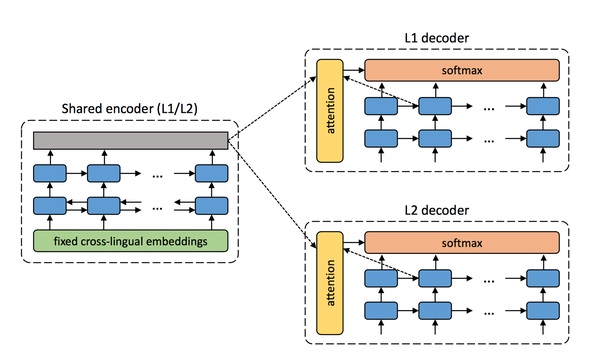
用这个模型交替执行如下步骤:
a> denoising:有点像 denoising auto-encoder。就是把某种语言的句子加一些噪声(随机交换一些词的顺序等),然后用 shared encoder 编码加噪声后的句子,最后用该语言的句子解码恢复它。通过最大化重构出的概率来训练 shared encoder 和该语言的 decoder。加噪声的目的是想让 encoder 学会分析语言的结构、提取语义特征,decoder 学一个好的语言模型,而不是仅仅学会复制粘贴;
b> back-translation:语言 L1 的句子 s1 先用编码器编码,然后用 L2 decoder 贪心解码出 s2,这样就造出了伪平行句对 (s2, s1),这时只做推断不更新模型参数;然后再用 shared encoder 编码 s2,用 L1 decoder 解码出 s1,这里通过最大化 P(s1|s2) 来训练模型(也就是 shared encoder 和 L1 decoder 的参数)。
(注:back-translation 是 Sennrich 15 年提出来的数据增广的技巧,详见论文 [1511.06709] Improving Neural Machine Translation Models with Monolingual Data 。具体做法是把单语语料用训好的机器学习模型翻译一遍做成伪平行语料,然后把这样的句对也当做训练数据来训模型,其实就是半监督学习的做法。叫 back-translation 是因为假如你增广语料的时候是把 s1 翻译成了 s2,那么训练的时候要用 s2 翻译出 s1 这个方向来训模型。其动机是,目标语言必须始终是真句子才能让翻译模型翻译的结果更流畅、更准确,而源语言即便有少量用词不当、语序不对、语法错误,只要不影响理解就无所谓。其实人做翻译的时候也是一样的:翻译质量取决于一个人译出语言的水平,而不是源语言的水平(源语言的水平只要足够看懂句子即可))
另外在训翻译模型的时候,词向量是固定不变的,就用预训练得到的词向量。
就通过这种神奇的方法,他竟然做到了还不错的翻译效果(BLEU>0.1),并不是简单的逐词翻译!
一些具体的例子比如(数字不准是 NMT 的老问题了):
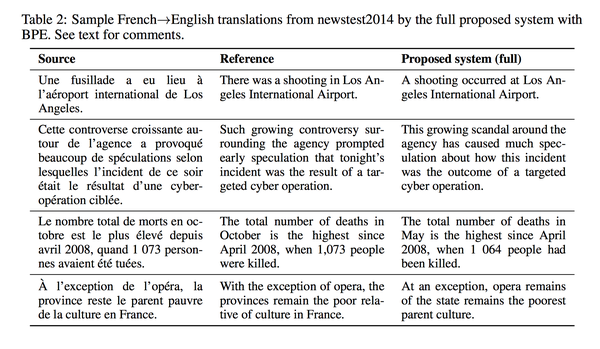

Remark:
1、整个模型相当于 unsupervised cross-language embedding + denoising auto-encoder + dual learning 合起来,但是效果这么好真是令人惊讶;
2、其实这个不能算完全无监督,因为用了阿拉伯数字这个跨语言的 lexicon,相当于利用了天然、廉价的对齐信息;假设有一种语言不使用阿拉伯数字,那这篇文章的方法也行不通……当然,理论上说,其他无监督对齐词向量空间的方法也可以,比如说清华 ACL'17 那篇 Adversarial training for unsupervised bilingual lexicon induction,但是效果可能就要大很多折扣;
3、dual learning 那篇文章本来也想做完全无监督的 NMT,但是做不动,最后还是用了少量平行语料……这篇文章成功的原因一是利用了对齐的词向量空间(相当于凭空得到的先验),二是使用 shared embedding 减少参数,降低了学习难度;
4、文章做的实验都是基于英法或者英德的,都是比较接近的语言,在这些语言对之间共享 encoder 可能是合理的,因为可能存在一个统一的语义空间;对于差异较大的语言,比如说中阿翻译,这么做可能是不行的。从 GNMT 的经验来看,多对一翻译是没问题的,因为翻译模型本质上是 conditional language model, which is a language model of the target language and conditions on the source language,多对一可以训练出一个更好的目标语言的语言模型;但是一对多经常会损害翻译质量,因为每个语言对对 encoder 提特征的方式的要求会有一些冲突。这篇文章却对两种语言使用同一个 shared encoder,在相差较大的语言上可能会难以学习;
5、文章里 BPE 的效果不稳定,真是很神奇……在我做过的所有实验以及听到其他所有人的反馈里,BPE 都是妥妥地提升翻译质量好几个 BLEU 的;我觉得可能的原因是,不同语言形意关系不同……不同语言在单词级别往往可以对齐(假设交给人类双语者来对齐的话),但是 subword 仅仅是基于 char n-gram 的频率,其中有很多是没有语义的(比如说并非词根或者词缀),到底应该嵌入到 cross-lingual word embedding space 中的哪里呢?这一点其实不够明确;
6、还有,我认为这篇文章的方法应该还是需要非常非常弱的监督信号的,就是需要假设两种语言的语料都是同一个领域的,至少是话题相近,不然可能很难构建统一的语义空间;
7、再设想一下,假如我们有大量关于某外星语言的资料,和人类语言的组织方式完全不同,不能展开成线性结构(类似七肢桶的语言那样),那就没法学了,因为两种语言的语义空间可能结构不一样,会导致词对齐不准,或者是 encoder 训练冲突。再假如说我们有大量某种古代失传的语言的资料,因为里面没有阿拉伯数字,所以在第一步生成 cross-lingual word embedding 的时候会遇到困难(这一点下面 FAIR 的工作可以解决);另外由于古代文本描述的内容与今天的文本可能有较大差异(比如说古人没有电视没有火车没有议会,他们的生活跟我们今天的生活差太多了,有些概念可能是现代语言里不存在的,很难对齐到一个空间里),这一点也会导致学习困难。不过好在,人类破译一门古代语言一般都是从某一个子系统入手的,有一些关于语言的元信息,比如说破译玛雅语言就是先破译了它的历法和数字系统,又知道了文本的内容是古代帝王的生平,有了这些信息做初步的对齐就好办很多了。
FAIR 的论文和这篇论文如出一辙:都是先训两个单语的词向量,然后对齐词向量空间,之后对齐 encoder 语义空间,两种语言各一个 decoder;用 denoising auto-encoder 训练单语语言模型,用 back-translation 造伪平行语料优化似然函数……
不过我个人感觉 FAIR 的文章更漂亮一些,因为它是真的完全无监督的,连阿拉伯数字这种天然跨语言的 token 都没用,并且工作的延续性更好,各个模块浑然一体。
主要区别点在于:
1、使用 Word Translation Without Parallel Data 里的方法对齐两个词向量空间并导出初步的双语词表(吐槽:这也是这群作者的工作,也投了 ICLR'18 在审= =):
具体做法是,用对抗的方法训练一个生成器 G(原空间到目标空间的变换矩阵,要求正交),以及一个判别器 D(用来分辨一个给定的词向量是目标语言的还是源语言变换过来的),学好以后两个空间就对齐了(这一步其实有点像之前提到的清华的那篇文章)。在这之后可以继续 refine,就是找两种语言可以配对的高频词,以他们为种子,再次解析地求解两个空间之间的线性变换。这篇文章还有一个贡献就是提出了找配对词的指标,因为直接找最近邻可能有很多问题,比如说有些词孤零零的、有些词却是很多词的最近邻(这个问题叫 hubness),文章里的实验说明它提出的指标和 word translation accuracy 的相关性非常好,见下图(横轴是训练的 epoch 数,蓝线是 word translation accuracy,黑线是它提出的指标):


从而可以用这个指标指示对抗训练什么时候停下来。论文最终展示的对齐效果拔群,跟有监督的方法效果差不多甚至更好(word translation 在有的语言对上能达到 70% 甚至 80% 的准确率)。而且对于字母表不同的、距离较遥远的语言,例如英汉,效果也非常好。
2、模型结构图如下所示:
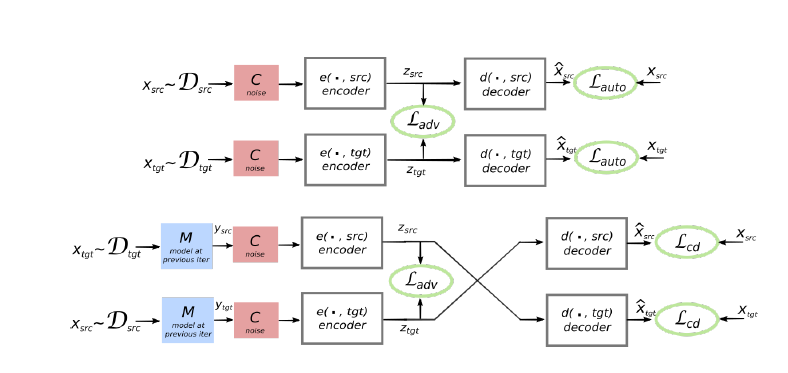

上半部分是 denoising auto-encoder,用于把一个 corrupted sentence 恢复出顺畅的源句子,corrupt 的方法是局部交换和扔掉个别词。
下半部分是翻译模型,先用前一代的模型(蓝色模块)把语言 L1 的句子 s1 翻译成语言 L2 的句子 s2,然后优化 back-translation 的似然 P(s2|s1)。
这里和 Cho 他们的模型是一样的。主要区别在于:
- 这一篇的词向量用步骤一中的词向量初始化,但是之后还会继续训练。而 Cho 的文章中则固定住了词向量。
- Cho 的文章直接让两种语言共用一个 encoder 和共享的词向量矩阵;而这篇文章是两种语言各有一个 encoder 和 decoder,两个 encoder 共享隐层参数,两个 decoder 共享隐层和 attention 参数,输入和输出层则不共享,但是用一个判别器分辨 encoder 编码的结果来自哪种语言,通过对抗的方法让两个 encoder 编码的语义空间重合到一块儿去,从而词向量不会在训练过程中跑偏。这种做法和前面对齐词向量的方法一脉相承,工作的延续性更好一些;而 Cho 那个拼凑感有些强。
- 在训练的时候,Cho 的文章是一步 denoise 一步 back-translation 交替训练,每次只训一个方向,按我的理解应该是 denoise auto-encoder 先收敛,然后引导翻译模型收敛;而这篇是两个翻译方向的图中所有 loss 加起来训一个 batch,然后判别器 D 训一个 batch,这样交错下去,所有模块一起慢慢收敛。
3、用生成初始翻译:
最后一点区别就是,Cho 那篇是从头开始训模型的;而 FAIR 这篇是用 word-by-word translation 生成第一轮时的初始翻译(其实这时候效果已经不错了,因为这篇文章用的词向量对齐质量很高,单是这种翻译 BLEU 就能达到 5 个点)。所以按照我的理解,FAIR 这篇第一轮迭代就能在比较靠谱的伪平行句子上进行了,而 Cho 那篇可能需要从一张白纸学起,训练初期的翻译结果估计不太能看……不过好在它固定了词向量,应该可以引导 shared encoder 快速构建语义空间。
所以,这两篇文章对于 cross-lingual embedding 的用法是不一样的。Cho 那篇仅仅是用来对齐两个空间;而这篇既用来对齐空间,还用来导出 translated lexicon,加速模型收敛。
4、收敛条件
Cho 那篇没详细说,估计就是看损失函数吧。而 FAIR 这篇说,可以让 s1 翻译到 s2 再翻译回 s1',计算 s1 和 s1' 的 BLEU 来做交叉验证,决定训练什么时候停止,并且说明这个指标跟真正平行语料上测出来的 BLEU 相关性很高(这里又能看到词向量对齐那篇提出的无监督交叉验证指标的影子)。如下图所示:
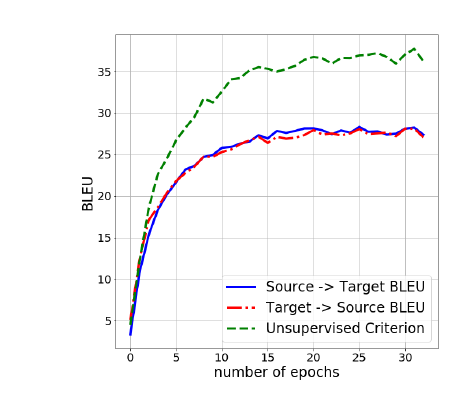

不过看这个图的话,感觉其实没有多大必要引入这个指标……真正的 BLEU 看起来也是平稳收敛的,没出现拨动很大的情况,训得差不多了就可以停了,交叉验证意义不大。不像词对齐那个,不同 epoch 对齐准确率能从 80% 抖到 20%。
最终结果就不贴了,感觉两个文章的效果差不多,算是互相验证吧。
还有一些细节感觉这篇文章做得很用心,比如说它是用 WMT 的平行语料训练的,但是并不是把平行句对扔给了模型,而是把句对分成两半,从前一半里取 L1 的句子作为 L1 的语料,从后一半里取 L2 的句子作为 L2 的语料,这样一来训练模型用到的单语语料库没有互相翻译的关系,可以避免作弊嫌疑;同时又因为实际这些单语语料都是有平行的翻译结果的(只是模型训练时没用),就可以用真正的翻译结果和模型的翻译结果作对比、评估,也即图五。
Remark:
1、Cho 那篇工作感觉是天上掉下来的,引言里写了一堆机器翻译的相关工作,表示他们是第一篇做到无监督机器翻译的,就是抓住 shared auto-encoder 这一特点做到了一件以前不敢想的事;而 FAIR 的工作延续性要好得多,举了很多 CV 领域的无监督翻译工作,例如 CoGAN/cycGAN/FaderNet 等,并且文章内容确实也跟这些工作一脉相承,读起来非常顺畅。
2、除延续性好以外,FAIR 的工作还有一个优点:完整性。不管是无监督词对齐还是无监督机器翻译,他们都提出了相应的收敛判定条件,有模型有测评,而 Cho 那篇感觉只是沿着一个 idea 搞了一个模型,比较零散。
总结
我们竟然又朝着无监督机器学习迈进了一大步……很多事情难,主要是难在我们不知道它到底有多难。等到解决之后回顾的时候,才会发现可能解决方案其实非常简单。比如说 AlphaGo 攻克围棋的方式,真的比我想象得要简单很多。机器进化的速度再一次超过了我的想象。撒花~
2019.02.03 更新:Phrase-Based & Neural Unsupervised Machine Translation 和 Cross-lingual Language Model Pretraining 又把无监督机器翻译的效果提升了一大步,使用预训练的 Transformer 初始化,German-English 居然提高到了 34.3 BLEU,已经接近有监督了…… BERT 里提出的 Masked Language Modelling 真厉害。
