
为什么粒子半透特效会那么的费?


CPU计算部分
1.DrawCall(耗费中。因为粒子支持动态Batch,且通常不会以Z轴作为排序标准,合并概率很高。只有在确实使用了大量不同材质或者强制排序的情况才会出现性能热点,然而这种情况还是挺常见的)
2.粒子网格计算(以前高,现在低。因为目前的粒子计算已经分摊到了子线程上由任意空闲核心来执行,而现在是八核机的时代。最多也就是核心利用率高导致一点点发热,但绝不会成为卡顿的原因。而苹果那边,靠着出众的单核性能也不至于跑不动)
3.将算好的粒子网格用渲染指令送入“显存”区域(耗费低,虽然要占用渲染线程,且每帧都要处理一次,但毕竟数量还是少,起码比蒙皮网格的压力要低得多。这个部分和DrawCall共享同一个瓶颈。)
GPU计算部分
1.顶点计算(耗费低。粒子通常不使用Mesh粒子,而是发射4个顶点的广告牌Quad,即使几百同屏的粒子,顶点数也不过才过千,尚不及一个角色模型的量,和像素阶段的耗费的FLOPS没有可比性。当然,顶点阶段除了曲面细分,有可比性的也不多。)
2.像素计算(高。虽然粒子的frag阶段计算量低,采样也只取一次,但是架不住多。非透明物体在ZTest影响下并不会反复在同一个像素下重复计算,但是半透物品的重复计算是无法避免的,而一般粒子特效的做法就是,叠,叠,叠,太亮导致过曝,加一层黑色半透物体降低亮度,继续叠。不加限制,单粒子叠上10-20都是常事。即使限制了,部分区域超过5都是难免的。而为了追求光效边缘的平滑,绘制面积通常也比视觉面积更大。)
内存带宽部分(内/显存和GPU/SOC之间的交互)
1.搬运顶点数据(耗费极低,实在太少了)
2.搬运特效纹理数据用于采样(耗费中等,因为特效纹理共用率很高且通常在同一批次绘制,而且大部分粒子使用的都是小贴图。仅有在使用SheetAnimation和出现法阵等图案时候才会有大贴图的出场机会,而SheetAnimation也不会同时搬运全部的数据。且开启MipMap后,在粒子展开的初始阶段也不会使用全图数据。压缩纹理也可以大幅减少带宽压力。)
3.将算好的数据和屏幕内的原像素进行混合呈现(高)
嗯,咱这篇文件其实主要是来讲这最后一个东西的。
我以前就是把这一项作为盲点给忽略了,所以导致了错误的理解。因为从直观上看,这东西就和氧气一样,怎么都不该缺吧?我算都算完了,然后存回显存里用来显示,这个地方怎么可能会成瓶颈呢?
那咱们就来算一笔账吧。
以手机游戏的最低分辨率1280x720计算,一个屏幕缓冲区加上深度缓冲检测(为了遮挡不能关),每个像素需要6byte,然后以60帧/s的帧率要求,乘起来的结果是:
绘制一屏幕数据(1 overdraw),需要的带宽至少是331776000bytes,也就是0.316Gbytes。
不过,由于透明物体需要和原屏幕像素进行混合,所以还需要回读一次屏幕缓冲区的数据,会增加接近一倍,0.527Gbytes。
如果我们游戏的特效峰值overdraw达到了10(测一下的话,会发现全屏特效特别容易到达高值,乱做单特效都能直接到5),也就是10个屏幕的话,那就是5.27Gbytes。
而在一些老机器上,诸如三星S3,总内存带宽其实也就8G而已……
要注意的是,上面算出来的仅仅是理论极限值,正常硬件工作总会有时间损耗,不可能充分利用整个带宽。cache miss这些事且不说,光是CPU和GPU工作时的相互等待,起码也要浪费十几个百分点。而且,你的手机再怎么样也得干空画屏幕以外的事情啊,总还是得读点别的贴图啊?内存带宽CPU也要用啊。
现在新出的手机好了许多,但也就20-25G的带宽而已,但现在手机屏幕也大了啊,上个1080P,带宽要求就要乘2.25,这个问题也未见得得到了多大的缓解。
硬要说的话,这就是内显一体化的锅。本来显存是绑在GPU旁边专门给它用的,普遍都是几十乃至上百G的带宽。到了手机变成了SOC,直接砍到了10%,以前不在意的东西,就不能再视而不见了。
但是,播放粒子特效卡,就一定是带宽的问题吗?
这也未必,因为手机的GFLOPS(每秒计算浮点数)也不是特别强力,OverDraw到了10以后,考虑到不透明物体那边的计算量也不少,留给特效的空闲不多,也有可能是运算能力,采样效率,也就是一般说的fillrate到了瓶颈。而且毕竟带宽使用量并没有到达那个怎么都不够的极限值,且大部分移动GPU都使用了TBR(Tile Based Rendering)技术,也并不是任何一次绘制操作都会直接操作内存。且GPU其实也有二级缓存,不会每帧都直接和内存打交道……虽然那个缓存只有4M,而且是和CPU共用的(苹果A7)。
我们需要一个辨别方式。
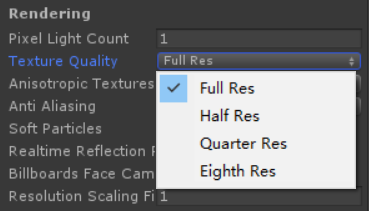
Unity的质量选项里可以设置纹理的缩小倍数,它会限制GPU使用的纹理大小(但不会减少内存占用),这样能成倍减少贴图的带宽使用量,但对读屏幕那一部分没有任何影响。如果调低它帧数上升了,就可以说明确实遇到了带宽瓶颈,但没变化,也有可能是因为优化幅度太低了看不出来。
所以大概只能修改特效的Shader,在它的frag部分强行乱写一些浪费时间的操作,假如帧数并没有变得更低,说明FLOPS并没有遇到瓶颈,那就只能是带宽遇到了瓶颈了。
然后,怎么办?
真不好办。假如是普通的纹理把带宽撑爆了,降低纹理大小即可,少做一些采样。但是屏幕刷爆了,又不想降低分辨率,那就只能减少刷屏幕的次数了。
也就是减少OverDraw。
在Scene视图里可以直接看到一个大概的映像
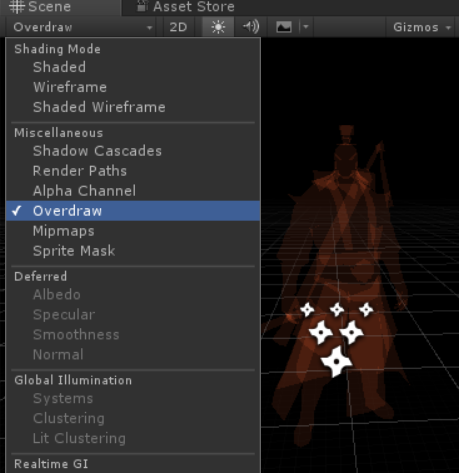

也可以用这个编辑器扩展获得一个数值化的结果


通过修改它的代码也可以实现自动检测库里的特效并给出报告,直接在美术的源头上封死。基本上,特效只要控制好OverDraw,然后限定一下DC和顶点数值就好。
粒子数其实可以不用管,因为在粒子数炸之前,OverDraw基本都会炸。
顶点数遇到某些不把Mesh粒子当事儿的也会炸(我是真见过,而且还叠了起码10个,就为了做一个火球效果)
因为外表上看不出来,所以有必要用工具限死,数值用UnityEditor.UnityStats就能取到,随便定个1000预防一下。
DrawCall,死限制到10差不多够了。当然越低越好。
在不降低画质的前提下(也就是不把劣化当优化的前提下),降低OverDraw有这么几个办法。
1.绝对禁止粒子贴图里出现完全透明的边框,可以程序检测。但毕竟粒子贴图少,也可以人肉扫一遍。
2.用顶点换fillrate,也就是使用Mesh粒子。发射月牙型粒子的时候,画几个顶点把需要显示的地方框起来。圆特效也可以换成八边形(代价略大,以处理大圆片为主)
3.不要用喷射粒子来模仿一些完全可以用其他方式实现的功能,比如说光圆片的大小扰动。
4.不要用粒子去拼一个实体的形状。流水,光柱,应该先用模型表现(辅以UV动画),再用粒子补效果,就不用那么密集了。实际上,部分火效果也可以这么做。
5.当你使用模型UV动画时,不要用多个模型重叠来实现多层UV动画,而是在一个片上实现多层UV动画,没功能找技术要。
6.低数量下粒子表现薄弱时,用SheetAnimation的序列动画来补效果。虽然这会增加部分纹理带宽,但是比叠出来浪费的OverDraw强,而且也省fillrate。
7.实在不行的时候,尝试整个特效做成序列动画(或者其组合)。以内存换OverDraw。
8.低透明度,只是为了强化效果的特效(大多是光晕),可以做到LOD上,远处不要显示,低配机不要开。
9.大量特效同屏的时候,删掉最早放置的特效(或者隐藏),也可以写算法优先删掉最密集区域的特效。一片混乱的时候,低优先度的特效(比如受击特效,施法特效)干脆就不要播。
10.实在没办法的时候,可以偷偷降低分辨率。但这需要用后处理拉伸,切换时才不会太明显(也可以将场景先绘制到RenderTexture,然后在另一个摄像机用一个片来显示出来,避开后处理流程。都已经这样了也不在乎这些操作额外的消耗了)
减少OverDraw,会同时降低带宽和fillrate,所以是哪边的瓶颈都没关系。但到底多少OverDraw是容忍的极限呢?
这个东西虽然很不好讲……峰值的时候至少不要超过10吧?朝着峰值5去努力。
UWA那边的标准是平均3= =
