【Classification】MobileNets阅读笔记

motivation
自从2012年ILSVRC的AlexNet,神经网络铺天盖地,各种脑洞大开的结构层出不穷,尽管在图像分类,物体检测,人体姿态估计,行为识别,人脸识别等都各个方形都有突破性进展,但是像经典的ResNet落地到嵌入式系统比如智能手机,还有不小的路要走,模型加速优化和压缩也是从学术界落地到工业界的重点。
google 17年发表的这篇mobilenets,其核心思想是将标准的卷积分解为一个depthwise卷积和一个1*1的pointwise卷积。depthwise卷积单独对每个输入通道用一个滤波器计算,pointwise卷积使用1*1的卷积组合depthwise的结果。这个分解可以有效降低计算量和模型大小。depthwise separable convolutions在Google的其它论文其实已经有类似的思想,inception v1-v4 到Xception,Google提出很多卷积方法,在本论文比较有创新性的就是chanel影响因子α和分辨率影响因子ρ。
Architecture
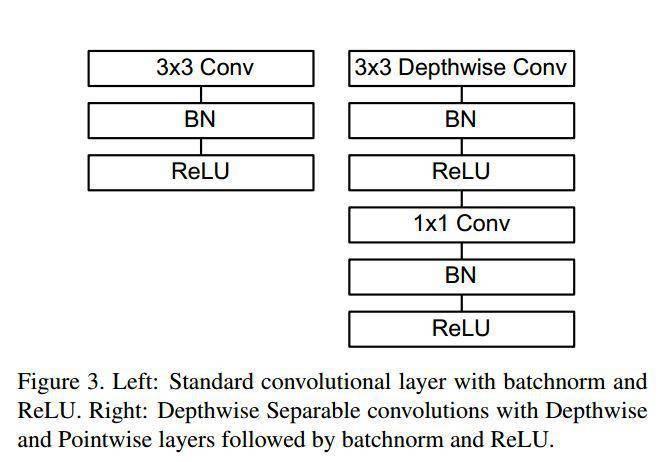

depthwise separable convolutions的网络结构很简单,作者用Depthwise Separable convolutions with Depthwise and Pointwise layers followed by batchnorm and ReLU替代Standard convolutional layer with batchnorm and ReLU,上面这幅图怎么看着都别扭,换一个一眼看明白的图示。
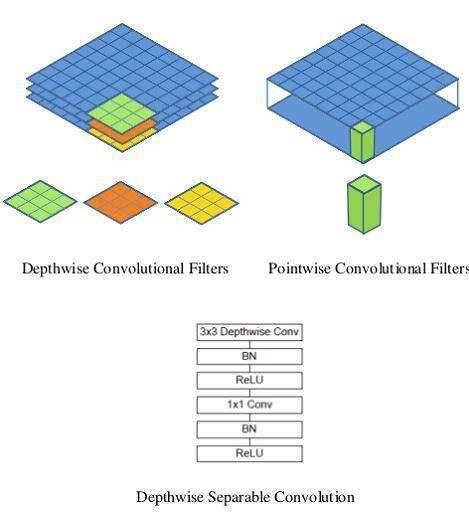

作者的提出两个用于进一步压缩模型的超参数:压缩通道的α影响因子和压缩特征分辨率的ρ影响因子,在原论文中很容易理解。
Experiment
作者用mobilenets对比了经典的GoogleNet,VGG 16,Squeezenet,AlexNet。在模型参数十倍的较少情况下,ImageNet的精度下降在3%以内,还是有明显的优势。


作者在Fine Grained Recognition,Large Scale Geolocalizaton,Face Attributes,Object Detection,Face Embeddings等领域分别对比试验介绍模型的优越性,详细数据见原论文。
Conclusion
作者的论文一直在提Mobilenet减少模型的参数和延迟,但是整篇论文没有介绍时间优势数据。对比参数量大的网络,Mobilenet不容易过拟合,使用过更少的正则化(更少的L2正则化或者不用)和数据增广。github上已经开源基于Tensorflow和MXNet。
