
用 TensorFlow 追踪千年隼号

简评:TensorFlow 是个机器学习的开源库。这篇文章中作者将用 TensorFlow 来训练识别自定义模型,并给出了详细的过程(星战迷 = =|| )。
在写这篇博客时,许多大型技术公司(如 IBM,Google,Microsoft,Amazon)都有简单易用的视觉识别 API。一些小点的公司同样提供了类似的服务,比如 Clarifai。但它们都没有提供对象识别。
下面的图片都使用了相同的 Watson 视觉识别默认分类器标签。第一个已经通过对象识别模型处理过了。
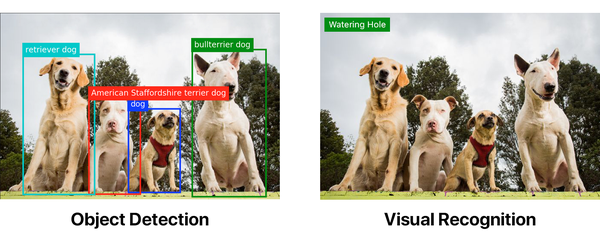

对象识别可以远远超过视觉识别本身。但如果你想要对象识别,你就要亲自动手。
取决于你的用例,你或许不需要自定义对象识别模型。TensorFlow 的对象识别 API 提供了几种不同速度和精度的模型,它们基于 COCO 数据集。
为了让你方便,我放上了一个 COCO 模型可以识别的完整对象列表:
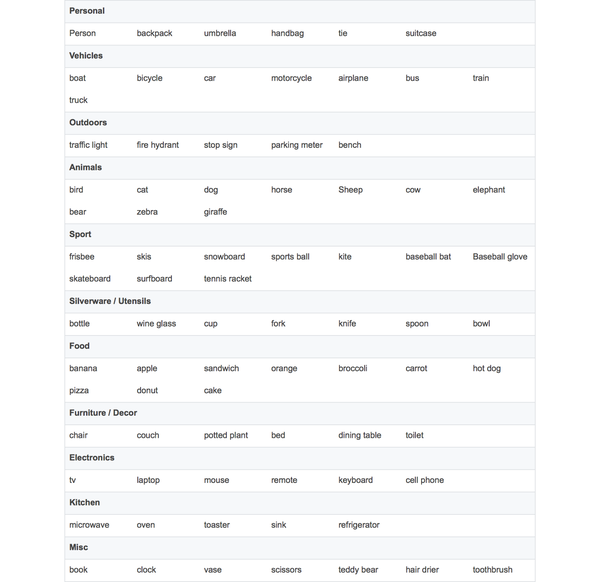

如果你想要识别一些标志或者不在上面这个表的东西,你需要构建自己的对象识别器。我想要可以识别千年隼号和一些钛战机。这显然是个极其重要的用例,因为你永远不知道……
给你的图片作注解
训练自己的模型要大量工夫。现在,你可能会想,“哇,哇,哇!我不想要费大量工夫!”如果是这样,你可以看看我的关于使用现有模型的其他文章。这是个更平滑的方向。
你需要收集大量的图片,并且写上注解。注解包括声明对象的坐标以及关联的标签。比如一张有两架钛战机的图片,注解看起来像这样;
<annotation>
<folder>images</folder>
<filename>image1.jpg</filename>
<size>
<width>1000</width>
<height>563</height>
</size>
<segmented>0</segmented>
<object>
<name>Tie Fighter</name>
<bndbox>
<xmin>112</xmin>
<ymin>281</ymin>
<xmax>122</xmax>
<ymax>291</ymax>
</bndbox>
</object>
<object>
<name>Tie Fighter</name>
<bndbox>
<xmin>87</xmin>
<ymin>260</ymin>
<xmax>95</xmax>
<ymax>268</ymax>
</bndbox>
</object>
</annotation>像我的星战模型,我收集了 308 张图片,每张图片有两到三个对象。我建议每个对象找 200-300 个例子。
“哇”,你可能想,“我要收集成百上千张图片,而且每张都要写上一堆 XML?”
当然不!有各种各样的注解工具,比如 labelImg 和 RectLabel。我使用 RectLabel,但它只支持 macOS。还要费很多工夫,相信我。我用了三到四个小时不间断的工作才把整个数据集注解完。
如果你有钱,你可以让别人来做,比如实习生。你可以用像 Mechanical Turk 这样的资源。如果你是个穷大学生像我这样的,或者,以单调的工作为乐子的人,你还得自己来。
当创造注解时,如果你不想写自己的转换脚本,确保它们导出为 PASCAL VOC 格式。这是我和许多其他人用的格式,你可以“偷”我上面的脚本(其实是从别人那偷的)。
在开始运行为 TensorFlow 准备数据的脚本之前,我们需要做一些设置。
克隆仓库
从克隆我的仓库开始。
目录结构看起来是这样的:
models
|-- annotations
| |-- label_map.pbtxt
| |-- trainval.txt
| `-- xmls
| |-- 1.xml
| |-- 2.xml
| |-- 3.xml
| `-- ...
|-- images
| |-- 1.jpg
| |-- 2.jpg
| |-- 3.jpg
| `-- ...
|-- object_detection
| `-- ...
`-- ...我加上了自己的训练数据,这样你就可以开箱即用。但如果你想要用自己的数据创造一个模型,你需要把你的训练图片放到 images 目录下,把 XML 注解放到 annotations/xmls 下,更新 trainval.txt 以及 label_map.pbtxt。
trainval.txt 是一个文件名列表,让我们可以找到以及关联 JPG 和 XML 文件。下面的 trainval.txt 列表可以让我们找到 abc.jpg, abc.xml, 123.jpg, 123.xml, xyz.jpg 和 xyz.xml:
abc
123
xyz提示:确保去掉扩展名后,你的 JPG 和 XML 文件名匹配。
label_map.pbtxt 是我们尝试识别的对象列表。看起来像这样:
item {
id: 1
name: 'Millennium Falcon'
}
item {
id: 2
name: 'Tie Fighter'
}运行脚本
首先,安装 Python 和 pip,安装脚本需求:
pip install -r requirements.txt把 models 和 models/slim 添加到你的 PYTHONPATH:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim重要提示:如果不想每次打开终端都运行上面的命令,你需要把它添加到 ~/.bashrc 文件。
运行脚本:
python object_detection/create_tf_record.py一旦脚本运行完成,你会得到 train.record 和 val.record 文件。这是我们用来训练模型要用的文件。
下载基础模型
从头开始训练对象识别器甚至使用多个 GPU 也要花好几天。为了加快训练速度,我们会采取一个通过不同的数据集训练过的对象识别器,并重用它的一些参数来初始化我们的新模型。
你可以从 model zoo 下载一个模型。每个模型都有不同的精确值和速度。我使用的是 faster_rcnn_resnet101_coco。
提取并把所有的 model.ckpt 文件移动到我们库的根目录。
你应该会看到一个 faster_rcnn_resnet101.config 文件。它和 faster_rcnn_resnet101_coco 模型一起工作。如果你使用其他模型,你可以从这里找到对应的配置文件。
准备训练
运行下面的脚本,然后就能开始训练了!
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.config提示:将 pipeline_config_path 替换成你的配置文件的本地路径
global step 1:
global step 2:
global step 3:
global step 4:
...耶!开始训练了!
10 分钟后:
global step 41:
global step 42:
global step 43:
global step 44:
...电脑开始抽烟:
global step 71:
global step 72:
global step 73:
global step 74:
...这玩意儿要跑多久?
我在视频中使用的模型运行大概要运行 22,000 步。
等等,什么?!
我用的是 MacBook Pro,如果你运行的设备和我的差不多,我假设每一步你大约需要花 15 秒,那么得到一个像样的模型需要不间断的运行三到四天。
好吧,这太傻了。我没有这么多时间做这个?
PowerAI 来救场了!
PowerAI
PowerAI 让我们在 IBM Power System 中用 P100 GPUs 快速地训练我们的模型!
训练 10,000 步只需要大约一个小时。但是,这仅仅用了一个 GPU。PowerAI 中真正的力量来源于分布式地使用几百个 GPU 进行深度学习的能力,效率可以达到 95%。
有了 PowerAI 的帮助,IBM 创造了一项图片识别纪录:在 7 小时内识别准确率达到 33.8%。超过了之前 Microsoft 的纪录 —— 10 天 29.9 %的准确率。
超快快快!
因为我没有训练几百万张图片,我当然不需要这种资源。一个 GPU 够了。
创建 Nimbix 账户
Nimbix 给开发者提供了一个 10 小时免费体验 PowerAI 平台的体验账户。你可以在这里注册。
提示:这个过程不是自动的,审核通过要 24 小时。
一旦审核通过,你就会收到一个创建账户的确认邮件。它会要你提供促销代码,留空白就行了。
你现在可以在这里登录了。
部署 PowerAI 笔记本应用
从搜索 PowerAI Notebooks 开始:
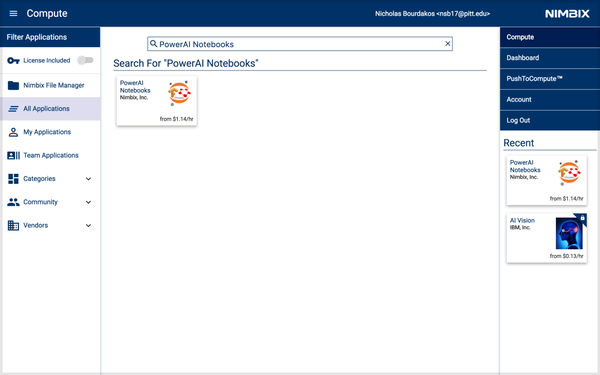

点中它,然后选择 TensorFlow。
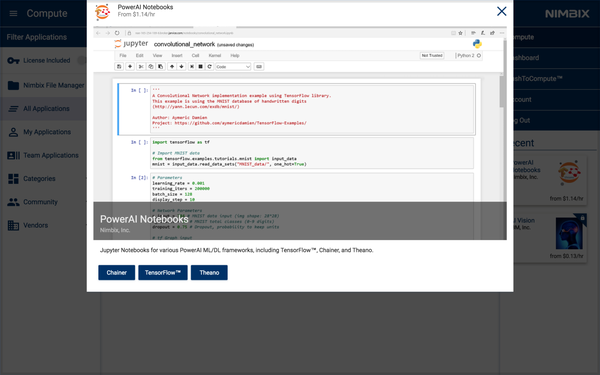

选择机器类型为:32 线程 POWER8,128G RAM, 1 * P100 GPU w/NVLink(np8g1)。


开始后,下面的工作台就会出现。当服务器状态变成运行时,服务器就准备好了。
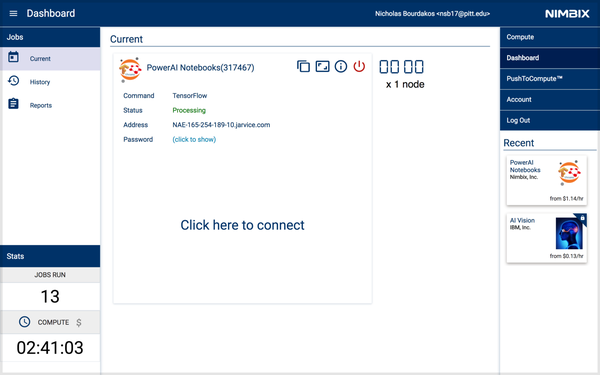

点击 click to show 得到密码。然后点击 click here to connect 启动笔记本。
登录使用 nimbix 的账户和密码。


开始训练
通过点击 New 下拉菜单,选择 Terminal 打开一个新的终端。
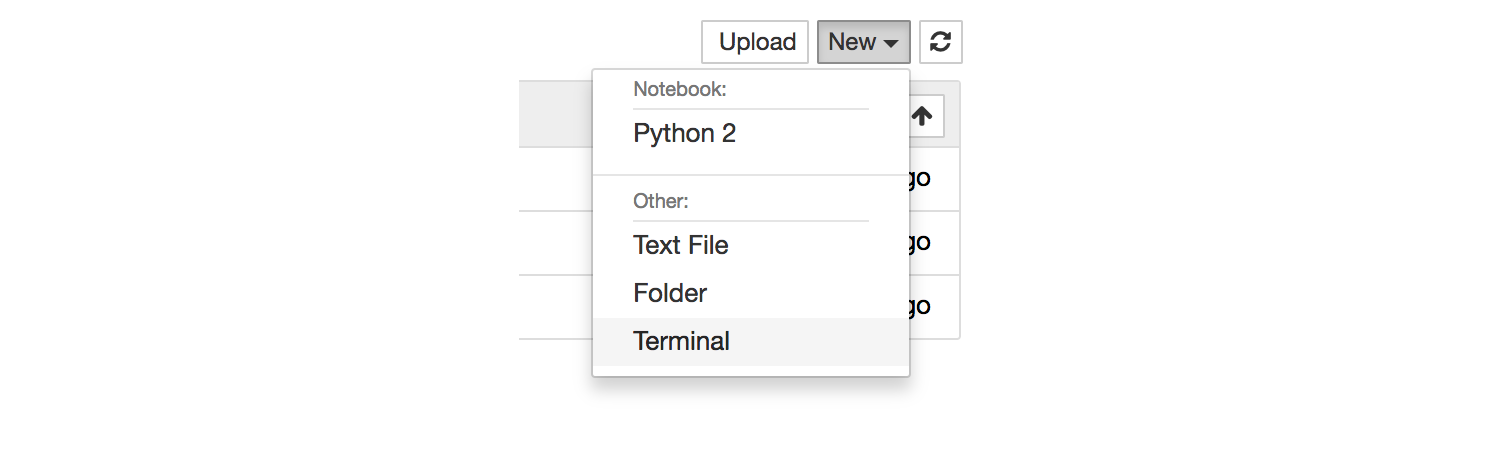

你应该熟悉这个界面了:


提示:终端在 Safari 上可能有问题。
训练的步骤和我们在本地运行的时候相同。如果你使用我的训练数据,你可以克隆我的仓库:
git clone https://github.com/bourdakos1/Custom-Object-Detection.git然后去到这个目录:
cd Custom-Object-Detection运行下面的片段,下载 faster_rcnn_resnet101_coco 模型:
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
mv faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.* .然后,我们需要再次更新 PYTHONPATH,因为使用了新的终端:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim最后在运行下面的命令开始训练:
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.config下载你的模型
什么时候我的模型才能弄好?这取决于你的训练数据。越多数据,你需要越多步数。我的模型在接近 4500 步时趋于稳定。在 20,000 步时达到顶峰。我甚至让它训练到了 200,000 步,但是没有任何增加。
我建议在每 5000 步左右下载你的模型,评估一下它,要确保你在正确的道路上。
点击左上角的 Jupyter 标志,然后,去到 Custom-Object-Detection/train。
下载所有的带有最大数字的 model.ckpt 文件。
model.ckpt-STEP_NUMBER.data-00000-of-00001model.ckpt-STEP_NUMBER.indexmodel.ckpt-STEP_NUMBER.meta
提示: 你一次只能下载一个。
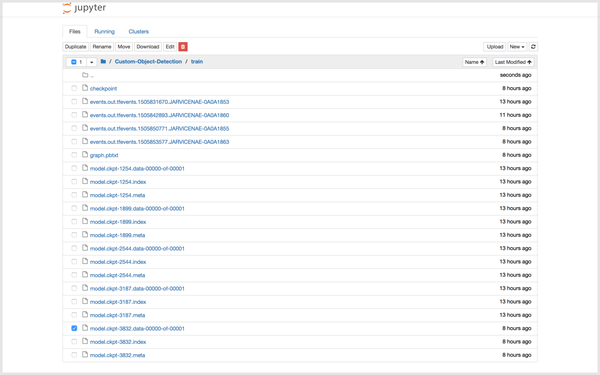

提示:确保在完成后点击红色电源按钮,否则计时将不会停止。
导出推理图
想要在我们的代码中使用模型,我们需要把检查点文件(model.ckpt-STEP_NUMBER.*)转换成冻结推理图。
把刚刚下载的检查点文件移动到之前我们使用的库的根目录。
然后运行命令:
python object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path faster_rcnn_resnet101.config \
--trained_checkpoint_prefix model.ckpt-STEP_NUMBER \
--output_directory output_inference_graph记得 export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
你应该会看到一个新的 output_inference_graph 目录,里面有一个 frozen_inference_graph.pb 文件,这是我们要用的。
测试模型
现在,运行下面的命令:
python object_detection/object_detection_runner.py它会找到 output_inference_graph/frozen_inference_graph.pb 文件,用你的对象识别模型去识别 test_images 目录下的所有图片,然后把结果输出到 output/test_images 目录。
结果
以下是我们在“星球大战:原力觉醒”这个片段中的所有帧上运行模型时得到的结果。
 https://www.zhihu.com/video/916612108513325056
https://www.zhihu.com/video/916612108513325056原文链接:Tracking the Millennium Falcon with TensorFlow
推荐阅读:
极光日报,极光开发者旗下媒体。
每天导读三篇英文技术文章。
