高级强化学习系列 第一讲 联合模型的强化学习算法(三)

时间过得好快,转眼间一周又过去了。今天继续分享联合模型的强化学习算法。前面我们介绍了指导策略搜索方法(GPS)。GPS利用模型来指导策略搜索,其优点是用来做指导的模块是轨迹最优方法,该方法有比较好的理论保证,而且另外一个模块是监督学习,而监督学习的权值训练效率很高。
当然,GPS的缺点也很明显:GPS方法严重依赖最优控制模块,但是在最优控制器模块,系统的模型由数据拟合得到,拟合的模型必然有模型误差,而且该误差会传递到产生的数据中,因此根据该数据训练的策略网络也会有误差。
一句话总结:GPS的最大缺点是没有处理拟合的模型误差。
为了解决模型的误差问题,剑桥大学机器学习实验室提出了PILCO系列算法。PILCO全称为probabilistic inference and learning for control, 在本专栏前面的帖子也专门介绍过。这里我们只介绍其思路,PILCO的基本思想是:当利用拟合的模型进行预测时(如GPS),模型误差会累积,导致预测越来越不准确。PILCO将模型误差考虑进去,拟合系统的概率动力学模型,并利用概率动力学模型进行预测。所以PILCO的概率模型应该满足的条件为:
(1) 概率模型能表示学到的动力学模型的不确定性
(2) 模型不确定性能被集成到长期的规划和决策中


PILCO的基本结构如图1.5所示,PILCO的结构分为三层:底层,中间层和顶层。下面我们一一介绍:
底层:学习一个概率动力学模型,比如高斯过程回归模型,概率神经网络模型。
中间层:利用底层学到的概率模型和当前策略 \pi 预测后续的状态分布 p\left(x_0\right),p\left(x_1\right),\cdots ,p\left(x_T\right) ,并利用预测计算值函数为 V^{\pi}\left(x_0\right)=\sum_{t=0}^T{\int{c\left(x_t\right)p\left(x_t\right)dx_t}} 。
顶层:利用基于梯度的方法对中间层的值函数进行优化,得到改进的策略。
介绍完PILCO算法的基本结构,我们再看看PILCO的伪代码:
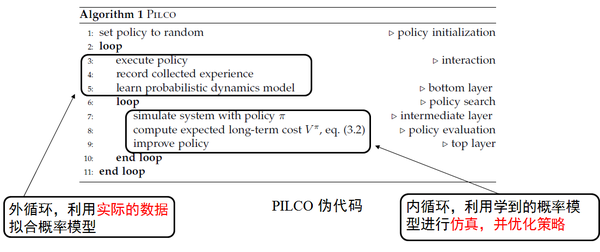

如图1.6为PILCO的伪代码,PILCO包括两个循环,其中外循环中执行实际的策略并收集实际的数据,并根据这些实际的数据拟合概率模型。内循环,则利用学到的概率模型进行仿真,并根据仿真数据对策略进行优化。
前面介绍的指导策略搜索方法(GPS)和PILCO方法,它们的共同的思路是先学习系统的模型,然后基于模型进行预测。这种思路往往伴随着模型误差的产生。模型学习本身就存在着瓶颈,所以一直沿着提高模型精度的思路继续前进,似乎很难有大的突破。如果想进一步提升性能,怎么办?
办法是此路不通,可另寻它路。
科学技术就是在不停地尝试中迂回前进的,所以,科研中最重要的就是尝试。勇敢地尝试用不同的思路解决问题,就算是新的思路效果不如原来的思路效果好,也是有意义的。
如何尝试不同的思路呢?
回到问题的本源。
在联合模型的强化学习算法中,问题的本源是什么呢?
在回答这个问题的时候,我们暂停下来想一想,为什么要联合模型进行强化学习。
我们在本讲的开头就说过,之所以联合模型进行强化学习,是因为模型能仿真产生很多数据,利用这些仿真产生的数据,我们能快速地对值函数进行评估或者直接优化策略。然而,前面的方法,模型是有误差的。PILCO的思路是将模型误差考虑进去。
但是,这个思路似乎有点舍本逐末。
因为,我们使用模型进行强化学习的目的不是为了得到精确的模型,而是为了快速地得到更准确的值函数。而GPS的方法和PILCO的方法中在进行模型训练时,并没有考虑最终的目标:更准确的值函数。所以,我们不能舍本逐末。也就是说在训练模型的时候不能以追求模型的精确为目标,而是应该以快速得到准确的值函数为目标。
基于这条线,DeepMind和谷歌大脑于2017年作出了一些很有意思的研究。下面我们简单介绍三个方法:
第一个方法是AlphaGo的创造者David Silver的Predictron方法。
如图1.7为Predictron的结构图。
Predictron最核心的思想:将系统模型(即状态转移概率)、立即回报、折扣因子、值函数全部利用神经网络来表示,然后利用无模型的强化学习方法(如TD方法)构造损失函数,进行端到端的训练。
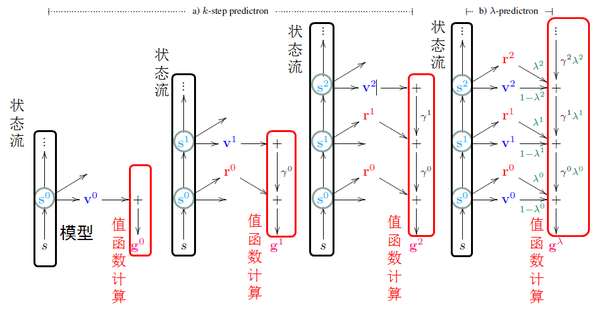

具体细节可参看文献[1]。这里我们只简单介绍Predictron的四个要素:
第一个要素:状态表示
\vec{s}\ =\ f\left(s\right)
这里用向量 \vec{s} 表示系统的抽象状态以区别其实际状态 s 。也就是说,在系统模型中,预测的不是实际的状态s, 而是抽象的状态。具体什么是抽象状态,什么是实际状态,我们在第二个方法VPN的方法中详细介绍。
第二个要素:模型预测,不只是状态流的预测,还包括立即回报和折扣因子的预测
\vec{s}',\vec{r},\gamma =m\left(\vec{s},\beta\right)
第三个要素: 下一步抽象状态 \vec{s} 处的值函数:
\vec{\upsilon}=v\left(\vec{s}\right)
第四个要素:由回报、折扣因子和值函数计算得到估计值,可用TD方法计算得到0步预测,一步预测,或k步预测等。
[1] Silver D, Hasselt H V, Hessel M, et al. The Predictron: End-To-End Learning and
Planning[J]. 2016.
今天暂时更新到这,更新多了怕大家消化不良了。
