
浅述:从 Minimax 到 AlphaZero,完全信息博弈之路(2)

此篇是 浅述:从 Minimax 到 AlphaZero,完全信息博弈之路(1)的续篇,为了连贯性我希望读者能够先阅读前篇。
可以说前篇介绍的是一些“透明”的问题,其算法和思路都是非常清晰的。但是可惜的是,清晰简单的方式并不能解决实际问题,因为理论相对于实际问题总是过于简化。这一篇我们将更多的面对一些很“脏”的问题,这些问题有些因为没有公开因而需要我们猜测,有些本身就是个谜,但是这些问题是至关重要的,它们或许解释了为什么是 DeepMind 而不是其他团队率先做出优质的 AlphaGo,显然透明的问题对于大家是公平的,所以差距就在于那些“不透明”的地方。
本章有较多的公式,这里先约定一下符号:
- 首先,粗体符号代表向量,正常体表示常量或者参数。
- s 代表状态(即当前盘面,并隐式包含规则对当前盘面的限制所需的必要信息,比如围棋先后手对贴目的影响等等)
- a 代表动作,或者策略(即一步走法)
- \bm{\pi} 代表当前策略(即 a )的概率分布, \pi(a|s) 是条件概率函数(策略函数),即 \bm{\pi}=\pi(\cdot|s) 。不引起混淆的情况下,它们又分别记作 \bm{p} 和 P(a|s) ,代表需要优化的对象(相对地 \bm{\pi} 就是优化的目标)。
- v 代表当前局面的价值(Minimax值), Z 为估值函数,即 v=Z(s) 。不引起混淆的情况下,我们又用 z 表示优化的目标。
- r 代表“奖励”, R(a|s) 表示某个局面下采取某个动作获得的奖励。
- 我们用 f 代指神经网络, \theta 代指其参数,且 f=P,Z ,即 \bm{p},v=f(s) 。
注:上面的符号基本遵循论文中常用的约定。 a 来自于 action 的首字母, \pi 的辅音发音类似 policy, v 是 value 的首字母, r 是 reward 的首字母。
然后约定一些常见的名词(大多在上面一篇提过):
- 策略网络,policy network
- 价值网络,value network
- 探索,exploration
- 利用,exploitation
- 增强学习,reinforcement learning
- 策略梯度,policy iteration
- 策略下降,policy gradient
- 损失,loss
- 蒙特卡洛树搜索,MCTS
回顾:优化估值函数
在上一篇中我们提到了,可以使用均方误差作为损失函数,来优化估值函数 Z_\theta :
\min_\theta{\mathbb{E}(z-v)^2}
其中 z 是优化目标, v=Z_\theta(s)
但是 z 如何来呢?我们记一场比赛中的比赛结果 r_T (胜,平,负)分别为 {+1,0,-1} ,并使得在整场比赛的局面中, z=r_T 。
在 AlphaGo 刚开始训练时,显然 r_T 难以代表真实的估值 (因为几乎在乱下棋)。但是随着其不断地增强, r_T 渐渐地接近正确的估值。
如何改进策略函数:两种不同的反馈
之前我们一直在谈估值函数的优化。现在我们开始涉及策略函数的优化。在上一篇中我们提到,策略函数用以提供MCTS中的先验概率分布 \bm p ,以指导其优先探索合理的分支。
如何优化策略函数呢?假设我们是一个学生,我们提供的“策略”是我们的一次作业,“场景”是固定的(也就是这里不妨让状态 s 固定),而我们得到了两种不同的反馈:
- 我们得到了一个关于最终答案的评分,视为一个奖励 r
- 我们得到了思路和参考答案,视为一个标准策略 \bm\pi
相应的在完全信息博弈中,这两种反馈分布是:
- 游戏最终的胜负得分 z
- 某一次比赛中选择的策略 \bm\pi
而两种不同的反馈,也决定了两种不同的目标:
- 使得期望奖励最大
- 使得和标准策略最为接近
对于第 1 种,目标为 \max_{\theta} E_{a|s}[R(a|s)]
我们可以通过求解梯度然后梯度下降解决(使用所谓log-trick推导):
\begin{align} \nabla_{\theta} E_{a|s}[R(a|s)] &= \nabla_{\theta} \sum_{a|s} P(a|s) R(a|s) & \text{definition of expectation} \\ & = \sum_{a|s} \nabla_{\theta} P(a|s) R(a|s) & \text{swap sum and gradient} \\ & = \sum_{a|s} P(a|s) \frac{\nabla_{\theta}P(a|s)}{P(a|s)} R(a|s) & \text{both multiply and divide by } P(a|s) \\ & = \sum_{a|s} P(a|s) \nabla_{\theta} \log P(a|s) R(a|s) & \text{use the fact that } \nabla_{\theta} \log(x) = \frac{1}{x} \nabla_{\theta} x \\ & = E_{a|s}[R(a|s) \nabla_{\theta} \log P(a|s) ] & \text{definition of expectation}\\ & = \mathbb E[z\nabla_{\theta} \log P(a|s)] & \text{let}\ R(a|s)=z=r_T \end{align}
对于第二种,我们使用交叉熵表示,目标为 \max_\theta \bm\pi^\mathsf{T}\log\bm{p}
同样地,我们可以求解梯度:\begin{align} \nabla_{\theta} \bm\pi^\mathsf{T}\log\bm{p} &= \bm\pi^\mathsf{T}\nabla_{\theta} \log\bm{p} \end{align}
敏感的读者可以感到两者的相似之处,我们不妨改写成这样以便比较:
\nabla_{\theta} E_{a|s}[R(a|s)] = \sum_{a|s} P(a|s)R(a|s) \nabla_{\theta} \log P(a|s) = \sum pr \nabla \log p
\nabla_{\theta} \bm\pi^\mathsf{T}\log\bm{p} =\sum_{a|s} \pi(a|s)\nabla_{\theta}\log P(a|s)=\sum \pi\nabla\log p
可以看到它们的形式是非常类似的,这种形式的意义是什么?
稍有基础的同学可以知道, \log p 这种形式一般用在求极大似然(maximum-likelihood),而这些形式就是一个加权的极大似然。特别的,如果权重也是一个概率分布,那么它等价于信息论中的交叉熵。
这些“权重”正是一个信号,告诉我们优化的方向。两种不同的反馈,带来了两种不同的“信号”:如果反馈是奖励 r ,那么信号是奖励 r 和当期选择的概率的乘积 pr ;如果反馈是标准策略,那么信号就是这个策略本身。
这两种不同的反馈带来的不同的更新方式,如果用在自我对抗上,就成为了两种不同的增强学习方法:前者是 Policy Gradient (策略梯度),后者是 Policy Iteration (策略迭代)。
AlphaGo-Fan 和 AlphaGo-Lee 使用了 Policy Gradient,而后面的版本使用了 Policy Iteration。这是为什么呢?
在回答这个问题之前,我们先复习一下强化学习相关的知识。
强化学习(reinforcement learning)
大多数人,特别是才接触这一块的,会觉得在完全信息博弈中,强化学习就是“自我对抗”。这当然无可厚非。这里我们也可以从数学上用另外一个角度看待这个过程。
以目标 \max_{\theta} E_{a|s}[R(a|s)] 为例,之前我们为了方便讨论固定了 s ;考虑到不同的 s ,其完整表示应加上 s 的期望,即为 \max_{\theta}E_s E_{a|s}[R(a|s)]
按照传统的有监督学习的方法,我们需要均匀的采样训练,其经验损失为:
-{1\over M}\sum_{s\sim S}{1\over N} \sum_{a|s\sim A|s}[R(a|s)] ,这里S和A分别为可行状态和动作的集合。
但是上面的式子要求样本已经存在时,才能显式地写出。于是我们只能“走一步看一步”:先通过自我对战产生数据,然后再用对战产生的数据进行更新训练,如此反复。也就是:


但是这并没有解决问题:如何从这个过程中得到提高?如果我们不能通过某种方法不断提高策略,那么只是毫无意义地模仿自己罢了。所以对于强化学习,其核心的问题是找到一条不断提高的轨迹:


Policy Gradient 和 Policy Iteration
对策略的提高存在于哪些方面呢?首先一点是 MCTS (上一篇我们重点提到的蒙特卡洛树搜索):
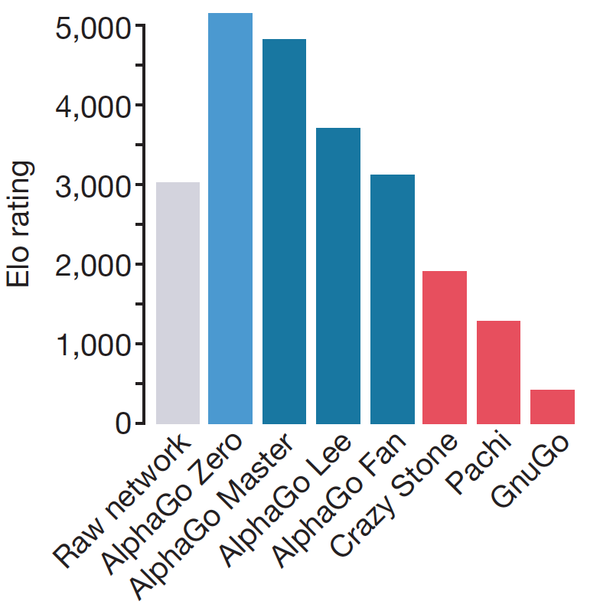

从图中可以看出,相对于没有 MCTS 的“裸网络”,拥有MCTS的AlphaGo战力有了巨大的提升,从职业1段左右直接提升到了高于 AlphaGo-Master 的水平。这就是 policy iteration 的工作原理:
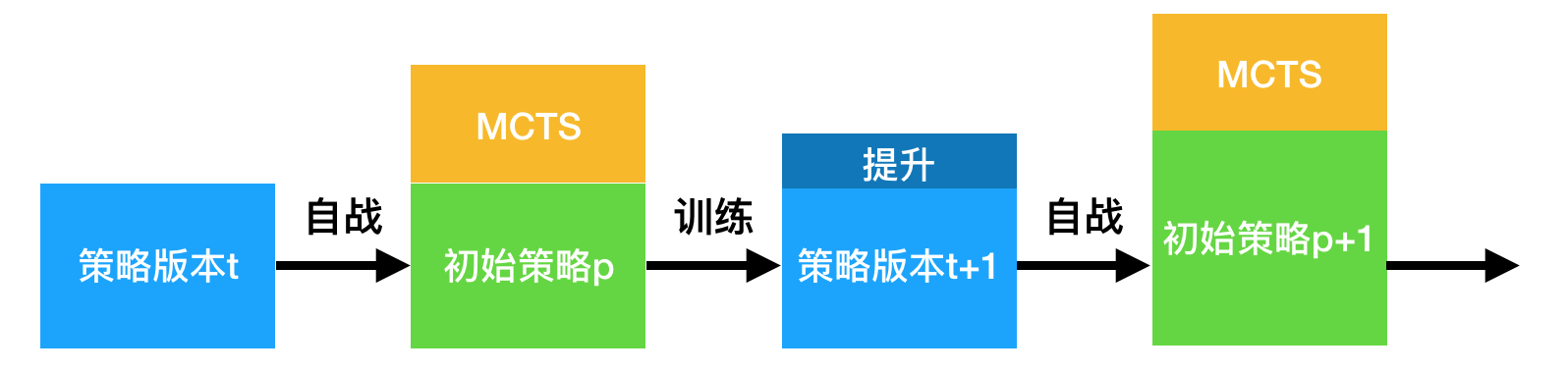

或者形象地用下图表示:


而我们在上节说过,policy gradient 使用奖励 r 作为反馈,这其实也是一种提高的方式;而因为动作 a 又是通过MCTS搜索得出的,所以实际上 policy gradient 有两种提高方式:
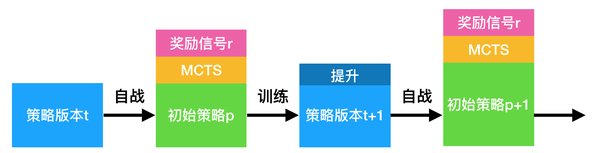

看似 policy gradient 有更多提升方式,因而应当好于 policy iteration。但是这是不正确的。这是因为 MCTS 的提升效果并不能和奖励信号的提升简单相加。


奖励信号的提升在于,肯定赢家的行为,否定输家的行为;而且在这个算法中,我们只有全盘肯定和全盘否定两个选项。但是问题是,现在是 AlphaGo 自战,输赢双方的能力是相同的,因此全盘否定输掉的一方的行为显然不是完全正确的(输不代表能力弱)。
正如吴清源和本因坊秀哉的“三三、星、天元”那盘棋一样,吴清源之输并不代表他下的每一步都是坏棋。
因此实际情况中,单单 MCTS 的提升要好于奖励回馈。另外奖励回馈存在的一个困难是,平局的处理。按照奖励函数的思想,平局获得的合理的奖励应当是0,这样平局就不会带来提升,这对容易造成平局的国际象棋等来说并不利,这也是 AlphaZero 中继续使用 policy iteration 的原因。
此外,奖励回馈带来的另外一个问题是,反馈的稀疏性:奖励回馈仅仅能够对“最终下出的一步”进行反馈(也就是一个“点”),这从公式可以看出:
\max_{\theta} E_{a|s}[R(a|s)]
而 policy iteration 可以对整个策略分布(是一个“向量”)进行反馈:
\max_\theta \bm\pi^\mathsf{T}\log\bm{p}
显然整个策略分布相比一个具体的策略,拥有更多的反馈信息。并且下面我们可以看到,DeepMind团队利用这一点来阻止进入局部最优。
既然如此,那么为什么 DeepMind 团队一开始会选择 Policy Gradient 呢?这很大程度上是因为延续他们之前训练机器玩 Atari 的时候的经验。


玩 Atari 游戏和下围棋非常不同的一点在于,其没有类似 MCTS 这种非常强效的增强手段,也不存在自我对抗这种场景,因此奖励信号是唯一可以利用提升的手段。而 DeepMind 研究围棋的很大动机来自于 Atari 上的成功,因为 Atari 第一次向大家展现了无需任何人类的经验,机器也能学会玩复杂游戏,这点在 DeepMind 的 AlphaGo-Zero 和 AlphaZero 上得到了彻底贯彻。所以 DeepMind 在刚入手围棋的时候,很明显借鉴了 Atari 上的经验,将其变成了一很“正规”的依赖奖励信号的增强学习问题。在后来的版本中 DeepMind 意识到了这些问题并加以改进,棋力才有了质的提高。
联合优化策略网络和价值网络
由于 AlphaGo-Lee 之后策略网络和价值网络以共享权值的方式存在,所以在更新的时候也可以联合更新,共同提升网络结果。
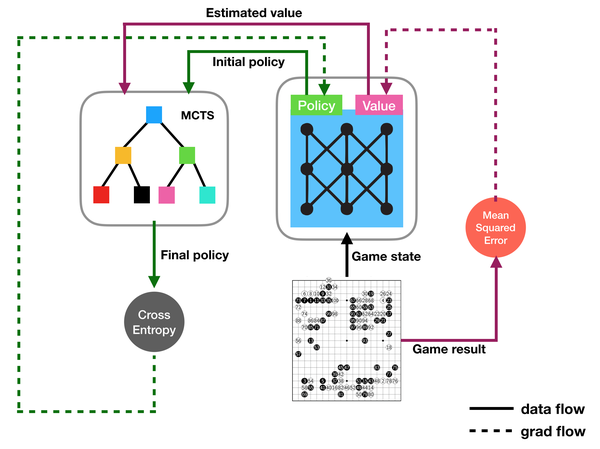

最简单的联合更新模式就是将 policy 和 value的loss直接相加:
loss=(z-v)^2-\bm\pi^\mathsf{T}\log{\bm p}
这就是 AlphaGo-Zero自战时使用的 loss 的基本形式。
但是非常有趣的一点是,AlphaGo-Zero 用人类数据训练时,用的loss是:
loss=0.01(z-v)^2-\bm\pi^\mathsf{T}\log{\bm p}
也就是使用人类数据时,“价值”需要贬值对待。这并不是 DeepMind 从 AlphaGo-Zero 才开始注意到的,从 AlphaGo-Fan 开始就使用了类似的方式:在 AlphaGo-Fan 中从人类数据学习的仅仅是 policy network,而 value network 是通过后面自战更新的,这其实已经说明 DeepMind 注意到人类的棋局结果并不是特别适合用来估值。这点仔细一想确实对的:很多人类的棋局都是因为中间偶然的失误导致了全盘覆灭(所谓“一着不慎满盘皆输”),其中的偶然性非常大,盘面的估值瞬息万变,所以棋局的结果离理想的估值差距较大。所以不如让 AlphaGo 培养自己的“感觉”,自己的“大局观”,而不是轻易被人类棋局的胜负所左右。
AlphaGo 的“五路尖”与李世石的“神之一手”
AlphaGo 第二盘 37 手的五路尖冲,与李世石第四盘 78 “神之一手”,都是棋局中的点睛之笔。从最新的 《AlphaGo》纪录片中,我们可以看到 DeepMind 团队两次分析实战数据的结果都是“人类棋手几乎不会下的一手”,“人类棋手下这步棋的概率不到万分之一”。
其实 DeepMind 所谓的 “人类棋手” 参考的是 AlphaGo 的 Policy network 产生的先验分布 \bm p ,这是因为 AlphaGo-Lee 的 Policy network 最初的训练数据来自人类。但是从原论文来看,Policy network 在人类数据集上的训练准确率也只达到59%,所以只是人类棋手下棋概率的近似。
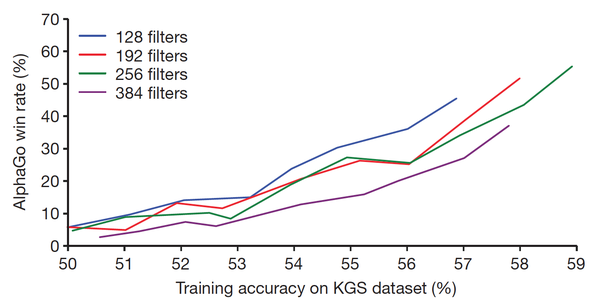

所以至今我们也不清楚 Policy network 认为李世石78手的概率小于万分之一是因为确实这一步完全出乎人们的意料(万分之一的概率如果对人类为真,几乎意味着除了李世石以外没有一个人类高段职业棋手能想到这一步),还是 AlphaGo 自身的疏失。
后来 DeepMind 团队更详细的分析指出直接问题是 AlphaGo-Lee 对死活问题的把握有问题。有趣的是,根据纪录片,DeepMind在出发前通过和樊麾的大量内部对战,已经发现了这个问题,只是当时已经来不及解决了,他们心里还是很虚的(比赛出发前几天才搞好了v18版本)。终于第四局李世石发现了这个bug。
这给DeepMind团队另外的一个启示是:一些特殊情况下,如果抓住这万分之一,就能下出传奇(五路尖);如果失去了这万分之一,就可能一败涂地(李世石“神之一手”)。
那么该如何防止忽视这万分之一?究其本质,这种问题是探索和利用(exploration&exploitation)的天平太偏向利用(忽视小概率的走法)导致的,所以解决方案是加强探索。
如何增强探索(1):加入噪声
DeepMind 团队使用了一个非常简单粗暴的方式来加强探索:每次搜索时在MCTS搜索树的根节点加噪声(也就是给下一步的策略 \bm p 加噪声),以基本保证 AlphaGo 至少把下一步棋的每一种可能都试一试。
加入的噪声是特别的,是满足 Dirichlet 分布 \rm{Dir}(\bm\alpha) 的一个向量,其中参数 \bm\alpha 也是一个向量,其每个元素代表了生成的分布的对应元素的性质。
Dirichlet 分布的性质可以由 Pólya 瓮模型刻画:一个瓮中有一些不同颜色的球,每个球的数量对应了参数不同元素的数值,然后重复下面的操作:从瓮中随机取一个球,如果其颜色为 \alpha_i ,则连同拿出的球再往里面放一个球。操作次数趋向无穷时,瓮里面的不同颜色球数量的归一化分布就是一个采样自 Dirichlet 分布 \rm{Dir}(\bm\alpha)的向量。我们将参数从自然数域向非负实数域延拓(比如将组合数中的阶乘换成 \Gamma 函数),就得到了一般的 Dirichlet 分布函数。
在 AlphaGo 中,对于每一种可能的走法,其 \alpha_i 均为 0.03:实际上在分布生成的随机向量中, \mathbb E[X_i]=\frac{a_i}{\sum_j{\alpha_j}} ,由于下棋时我们不知道哪个走法更好,所以就让随机向量中每个元素的值得期望相同。在 \alpha_i 相同时,随机变量每个元素的方差是 \text{Var} [X_i]= \frac {n - 1} { n^2 (n\alpha + 1)} (其中n是随机向量元素个数,对于围棋是 362),由此可见方差近乎和 \alpha 成反比。
所以 AlphaGo 每次开始搜索时(仅仅在MCTS的根节点使用一次),需要从 Dirichlet 分布中采样: \bm\eta\sim \text{Dir}([\alpha]*362) ,然后通过混入因子 \varepsilon 掺入到 Policy network 产生的先验分布中: \bm p'=(1-\varepsilon)\bm p+\varepsilon\bm\eta 。超参数 \alpha=0.03,\varepsilon=0.25 。
如何增强探索(2):加入退火机制
上一篇文章我们说过,MCTS的关键点就在于使用采样,使得某个动作的“期望利用价值”与采取这个动作(即走动作对应的路径)的次数正相关。
但是问题在于如何将次数N和最终选择的动作关联起来?在 AlphaGo-Lee 和 Fan 中,DeepMind 直接选择次数N最多的动作,作为最终策略 \pi (也就是最终策略分布其实是one-hot的);而 AlphaGo-Zero 后使用了 Policy iteration, policy 部分的损失是 -\bm\pi^\mathsf{T}\log\bm{p} ,如果 \bm\pi 是one-hot的那就太无聊了,完全没有利用上向量的其他分量,所以我们需要一种“不太贪心”的手段。
DeepMind的方式是被称为“退火”的方式:
\pi(a|s_0)={{N(s_0,a)^{1/\tau}}\over {\sum_b{ N(s_0,b)^{1/\tau}}}}
这个公式是热力学玻尔兹曼(Boltzmann)分布的一种变形:
P(a|s_0)= {{e^{{ \eta(s_0,a) }\over{kT } } } \over {\sum_b {e^{{\eta(s_0,b) }\over{ kT } } } }}
只要把 N(s_0,a)\rightarrow e^{\eta(s_0,a)},\tau\rightarrow kT 它们的形式就是一样的,由于在玻尔兹曼分布中 T 是体系温度,所以 \tau 这里也称为温度。
温度较高的时候,分布更加“均匀”;温度降低的时候,分布更加“尖锐”。
AlphaGo 自我对抗的前30步时,会使得 \tau=1 ,这样一来AlphaGo Zero在开局阶段变化会相对较多;而之后 \tau\rightarrow0 ,但是是如何趋向于无穷小的(突然变成0(相当于直接选出N最大的操作),突然变成很小的一个数,还是指数下降,还是倒数下降),论文并没有指明。这个策略或许也会影响实战结果。
而在正式比赛/评估中 AlphaGo Zero 也会使用退火温度,但是使用什么样的方式并不清楚。但是无疑这印证了之前和Master对战中大家发现AlphaGo开局阶段变数较多的印象,应该在 Master版本中就引入了退火机制。
引入退火机制的另一个好处是,使得开局更加多样化;而在收官时更加谨慎,尽量避免无谓的损失(因为如果AG估计胜率很高,此时各种走法都会表现出较高的概率,因为这些走法几乎都会赢,这时候就要强制让AG做一些努力,走胜率最高的走法,哪怕胜率只是高了一点点;这样收官的时候会更好看一点)。
AlphaZero 为何不陷入局部最优
自 AlphaGo-Zero 疯狂地完全自我学习后,AlphaZero 做了更加过分的一点:整个训练过程只使用一个神经网络。
在 AlphaZero 以前,每更新一个“小版本”后,都要将这个版本和迄今最好的版本对比,如果新的版本胜率超过 55%,才会用来取代以前最好的版本。这样做的显然的好处是防止 AlphaGo 自我博弈得“走火入魔”,陷入局部最优。
所谓陷入局部最优是指,AlphaGo 逐渐放弃更好的策略,比如征子和打劫,转而一头扎入了某些次好的策略,比如互相吃子。这是非常有可能的一件事,因为刚开始的时候AlphaGo征子和打劫的能力一定是很弱的,用这两种策略很难赢;但是相比吃子却是简单有效的。这样 AlphaGo 可能会认为征子和打劫是“坏策略”,而吃子是“好策略”,从而在吃子的道路上一路走到黑。如果我们要求AlphaGo有 “重大进步” 才能更新,这样就可以避免这种反复优化吃子的情形。
但是这种需要“重大进步”才能更新的策略会显著地增长训练时间。于是我猜测 DeepMind 团队在 AlphaZero 中尝试了一下一直使用一个网络的策略,然后惊讶地发现很成功。这将围棋的训练周期在相同硬件配置下,由天级降到了小时级(而对战李世石的版本训练了几个月)。
那么为什么 AlphaZero 为何不陷入局部最优呢?
敏感的读者可能察觉到,“局部最优”其实可以解释为 Alpha 系列缺乏 exploration (对新技能的探索太弱),也可以解释为“过拟合”。
所以我认为 AlphaZero 上所有提升 exploration 和抗过拟合的机制都能够阻止 AlphaZero 陷入局部最优,而这些机制 AlphaGo-Zero 中其实都有了,万事俱备只欠东风。
提升 exploration 的方式有:
- 选择最终策略的时候采用了退火机制,这样的策略向量保留了所有的分量,从而让所有的策略都能够得到学习,而不止是概率最高的策略。这是上文提到的。这样做其实某种意义上也达到了“模拟退火算法”的效应,可以脱离局部最优,而原先只选择最优策略的方式某种意义上是“爬山法”。
- 每次开始搜索前加入噪声,强制 AlphaZero 探索其他一些选项。这是上文提到的。
- 使用 Policy Iteration,让最终的棋局结果(reward)不能直接影响策略更新,避免 AlphaZero 因为使用了新招数而“直接挨打”。这在上文也提到过。
避免过拟合的方式有:
- 在 loss 中加入 L2 正则化项, loss=(z-v)^2-\bm\pi^\mathsf{T}\log{\bm p}+c\|\theta\|^2 ,其中参数 c=1\times10^{-4} 。这是神经网络非常基本的抗过拟合方式。
- 每次开始搜索前加入噪声。这个噪声会影响到最终策略,间接地影响到神经网络的训练(所以加噪声是很高明的做法)。神经网络训练中类似的做法是使用 dropout,能够显著地降低过拟合风险。
值得注意的是,上面提到的很多方法都依赖于 Policy Iteration,而在 Policy gradient 上比较难做,所以使用 Policy Iteration 是很高明的手段(当然了 DeepMind 一开始的时候也不一定想到这么多)。
插曲:AlphaGo-Master 到底是什么?
由于 DeepMind 在论文中只揭露了 AlphaGo-Fan, AlphaGo-Zero 和 AlphaZero 的具体细节,同时又声称 AlphaGo-Lee 和 AlphaGo-Fan 算法相同,只是硬件使用了 Google TPU。所以唯一不为人所知的Alpha系列成员就是 AlphaGo-Master了,虽然那几十场网络棋战让它在围棋圈子里相当出名。大师的面纱仍未揭露。
但是我们仍然可以通过各种证据猜测其真面孔。首先其配置和 AlphaGo-Zero 完全相同,所以可以肯定其算法是类似 AlphaGo-Zero 的。此外非常重要的一点是,在 AlphaGo-Zero 的论文中,有 20-block(3天完虐Lee版本的那个) 和 40-block(最强的 AlphaGo-Zero 版本)两个版本。
如果你写过论文,会知道其中很重要的一点是“连贯性”,也就是你会复用之前的一些扎实的已有工作,而不是每次都完全使用新的。那么这个 20-block 就有点有意思了,在论文中它几乎和 40-block 分开介绍的,虽然结构大致相同,但是评价等等完全不在一个体系中,看上去就像是两个独立的工作,而 20-block 版本似乎明显早于 40-block 版本。
所以非常有可能的一点是, 20-block 的结构就是 Master的结构,也就是 DeepMind 之前的工作。所以 AlphaGo-Zero 的工作很有可能是在 AlphaGo-Master 的基础上的。此外 20-block 版本 100:0 完胜李世石版本,水平也和 DeepMind 自己说的 “可以让 Lee 版本3颗子” 非常类似。
综上,Master 可能使用了 20-block 的结构,同时按照 DeepMind 在乌镇大赛上透露的,其初始训练数据来自于 AlphaGo-Lee,然后自我对弈提升。
AlphaZero 和 Stockfish 的比赛“公平”么?如何理解算力差距带来的可能变化?
AlphaZero 处理解决围棋外,还能解决其他问题,比如象棋。在 AlphaZero 的论文中,DeepMind 对比了 AlphaZero 和最强的开源围棋软件 Stockfish ,在100 场比赛中全胜。
但是论文中一幅图值得注意:
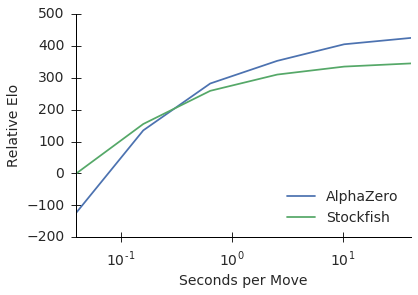
显然,如果限制两者的算力(通过减少搜索时间),AlphaZero 会逐渐落后于 Stockfish。
所以 AlphaZero 强是否更多是因为算力问题?
我们需要从不同角度理解算力。
- 从Flops。即每秒浮点运算的次数,这是算力的直接衡量。这点 AlphaZero 使用 TPU,其运算数量远远大于 Stockfish,这点上 AlphaZero 非常依赖算力。
- 从功耗。AlphaZero 特点是更依赖高度并行的硬件,比如 TPU/GPU,而不是传统的CPU;Stockfish相反。在未来这两者功耗之间不会差太大,TPU这种并行硬件天然地可以在相同功耗的情况下进行更多的运算次数,这点非常类似人脑。
- 从可扩展性。AlphaZero 达到顶峰的算力,和 Stockfish 达到相同高度的算力相差多少?这点 AlphaZero 优势较大,可能目前 Stockfish 即使使用推荐的算力的100倍以上的算力也不一定能够追上 AlphaZero。
此外和将棋冠军软件 Elmo 对战中,不论多少算力,AlphaZero 都显得更强:
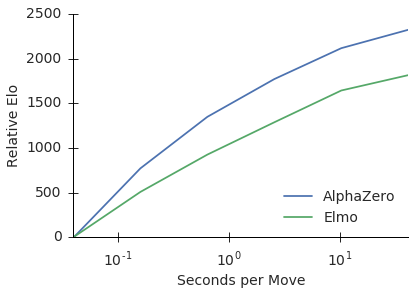
所以还要考虑一点
- 从发展时间。国际象棋已经被研究多年,技术非常成熟,所以 Stockfish 这种软件本来就接近完美,非常难对付(即使和AlphaZero下也出现大量平局),人类早就在国际象棋上不是软件的对手;极端情形下让AlphaZero去搞一个完全解决的问题的AI,那么AlphaZero必然不会胜利,这本来就对 AlphaZero 不利。而 Elmo 刚打败人类将棋冠军,相对嫩一点。
所以说从不同角度是可以有不同结论的,实际中需要看需求选择。
算法和先验知识:NIPS 17大会之争
NIPS大会上,DeepMind 公布了其围棋程序的最新迭代 AlphaZero。但是 Marcus 和 Tenenbaum 激烈地反对 AlphaZero 背后的 “零知识哲学”。又如何评价两方呢?
相关文章:NIPS大会最精彩一日:AlphaZero遭受质疑;史上第一场正式辩论与LeCun激情抗辩;元学习&强化学习亮点复盘
Tenenbaum 认为智能不仅仅是将一个公式计算地特别好,而是思考到底解决什么样的问题。他提出了一个非常有意思的想法:建造一个像小孩子一样学习的机器。
Tenenbaum 向观众展示了一个视频:一个小孩看到大人双手捧着书,在一个关着门的书橱前踱步,小孩很自觉地走上前把门打开。这样的理解能力和操作能力,是机器做不到的。要建造这样的机器,需要三个步骤:建立一个具备常识的核心;用这个核心学习语言;用语言学习任何东西。
Marcus 大声疾呼:在生活中,没有东西是被整齐的预先包装好的(像 Kaggle 里的数据集那样),没有人能保证你昨天的挑战和今天的挑战一样,你希望学习的是可以重复使用的技能和知识,并且可以用在未来的挑战里,而实现这种可重用性才应该是大家关注的重点。
AlphaZero 的提出,可以说是完全信息博弈问题的初步解决。其重要意义在于,我们终于可以用一个简单统一的方法来解决完全信息博弈的绝大多数问题,而不是每个棋类都要耗费大量的人力设计算法;其不足在于,“完全信息博弈问题”仅仅是买上月球的第一步(按照DeepMind团队描述这个项目是“人工智能的阿波罗计划”),而整个地月系即使仅仅相对整个太阳系而言也非常渺小,更何况广袤的宇宙。
不知是有趣还是讽刺,Alpha系列某种意义上确实和阿波罗登月计划有着非常类似的特性:
- 非常明确的问题和目标。
- 非常重大的突破。
- 非常具有象征意义。
- 新闻效应非常显著,举世瞩目。
- 耗费的资金非常多(相对领域内而言)。
- 解决的问题不能直接转化为效益,贡献(相对领域内其他资金水平相同的项目)有限。
不过值得庆幸的是,我们总算解决了一个池塘的问题。如果把人类能力比作地貌,而人工智能水平比作上升的水平面,那么这次水总算淹进了完全信息博弈问题的池塘,而不完全信息博弈也初步进水(Libratus德州扑克)。

DeepMind 在 NIPS大会上主要受攻击的观点是,他们体现了算法的“通用性”,证据是它们的算法不需要任何人类的数据,只需要规则,就能解决一大类问题。
这个问题可以从两个角度分析:
- 从完全信息博弈问题上而言,DeepMind的算法是相当通用成功的。
- 从整个人工智能领域来看,DeepMind的算法很狭隘。
我们需要再回顾一下下面这张图:
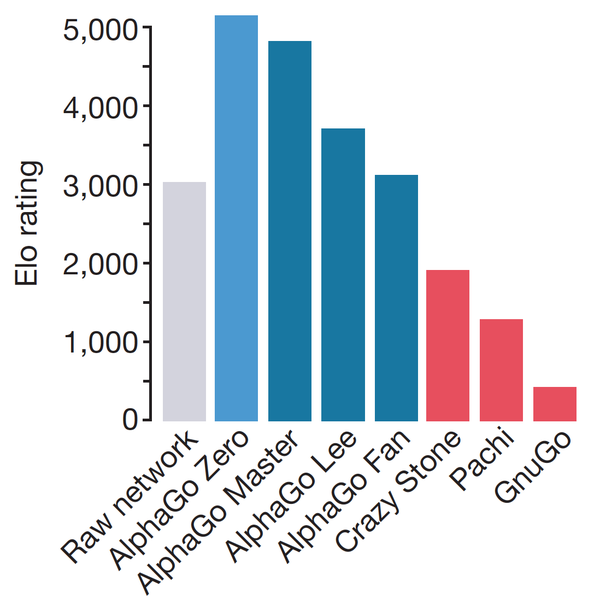

可以看到,没有MCTS的神经网络和完整的AlphaGo Zero之间差了2000多的Elo,这已经不是让三个子的问题了。仅仅是MCTS的加入就带来这么大的变化是非常值得注意的,这直接指明了最重要的原因是MCTS+CNN这套方法非常适合完全信息博弈。
DeepMind 的论点的一个直接反例就是他们之前搞的 Atari 游戏。完全信息博弈和Atari游戏都是 well-defined 的问题,都是 DeepMind 迄今最得意之作,然后就这两个问题而言,它们的算法能通用或者迁移吗?比如用DQN或者A3C来训练围棋,或者用MCTS来玩Atari。我们知道用DQN或者A3C来训练围棋,其效果至少不会好于 Raw network,而且很可能陷入局部最优;而Atari问题中都没有地方放MCTS,因为这不是个博弈问题,没有博弈树。
目前已有的另外反例就是星际争霸,我们至少知道Atari那套是搞不定的;而 OpenAI 前些日子搞的 Dota2 AI 一对一被人指出实际的训练不符合 OpenAI 自己声称的完全没有人监督,并且人们很快发现了AI的一些可以重复利用的弱点,完全不像 AlphaGo-Master 那样傲战群雄而不露破绽。
AI 离能够理解下面的一张图真的很远,很远:


但是仔细一想,不理解上面的图并不一定直接是AI本身的问题。如果这个图出现在上个世纪,人们也会一脸懵逼:这些人是谁啊?一旦你知道这是奥巴马等等信息后,你才有了完全不一样的理解,这点和 DeepMind 所强调的 “零知识” 是相反的。
星际游戏里面同样存在类似的问题:人能够玩的好,很多时候是有些常识,比如知道敌人迫近可能是筹备攻击或者骚扰;比如建筑和障碍物可以阻拦陆地的移动物体,但是天上飞的不一定——当然人也清楚什么样子的像是在天上飞的。AI完全不懂这些,对于目前算法(A3C等)实现的AI而言,一个捕捉事物的游戏就像下图(9根短线是agent的9个“感光元件”):
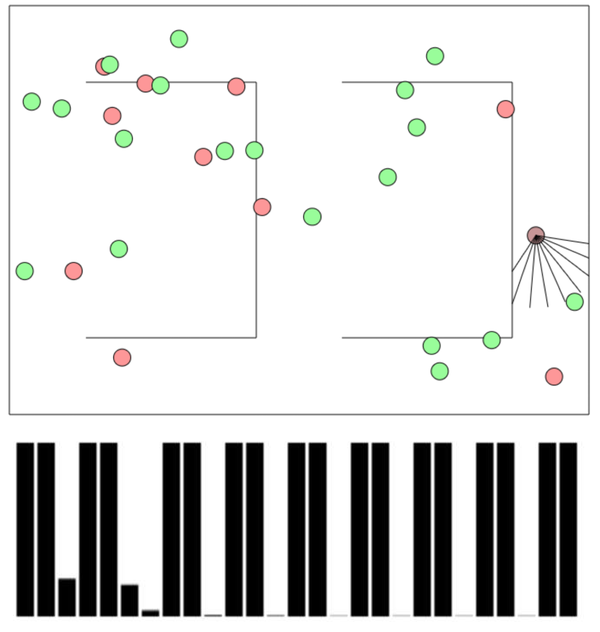

从这个问题也可以看出,人和AI的差距似乎并不只是“常识”那么简单,很多时候我们觉得给计算机一个知识图谱之类的东西就能赋予其常识,但是在实践中真正的困难在于人和计算机之间的gap太深。一个例子是,某个人想让AI帮其手动洗内衣,但是AI的做法是上网竞价买了一套新的完全一样的内衣,然后把脏的扔了。对于AI而言,后者是显然简单的,即使如今的AI也完全可以做到(网络搜索图片,一瞬间比对大量商家报价,在线支付;甚至你愿意可以写一个检查评论区的插件);而要让AI学人一样去用机械臂洗衣服,对AI来说是个很麻烦的事情,虽然对人来说显而易见。但是这个AI智能吗?如果说网上购物已经成为了极度便利普及的事情,那么这个AI似乎很智能;反之这个AI确实很傻。这又告诉我们一个事实是,智能似乎并不只是一种內禀属性,而是一种环境属性,不同的环境下,同样的智能体可以表现出完全不同的智能程度。
有趣的是,这种人和机器差异性使得我们在改造环境属性,以方便AI变得智能。现在异军突起的互联网和大数据行业,使得地图导航等应用成为可能——这些APP要是放在1960年代绝对会让人觉得极其智能,只不过我们如今已经非常习惯了而已。这些数据对于人来说是天书,但是机器却能够很方便的处理,完成各种复杂的任务。现在各种基础数据和网络信息的积累,正在冲击各行各业,虽然程序还是程序,其本身并没有怎么变智能,但是随着“机器友好”的环境的建立,程序本身的能力大大变强了,如果我们衡量智能的指标是“完成复杂任务的能力”,那么确实我们只能说现在这些程序变得更加智能了。另外硬件能力的提升也是非常重要的一点。
人也在让机器向人靠齐。至少最近几年的深度学习革命使得感知数据的处理有了长足的进步,机器可以以非常原始的方式得到一些非结构化的感知数据内部蕴含的信息,这使得无人驾驶等领域逐渐成为可能。实际上我们指的AI的进步绝大多数都是指的这一部分,但是我认为环境的改变同样是非常重要的一点,因为智能最终的目的可能还是体现在“完成复杂任务的能力”这个客观指标上,而不是“更接近我们认为的我们的思考方式”,因为我们对自身的智能的认知也并不健全,并且这种情形还会持续很久。
关于硬件:DeepMind使用的TPU是什么?TPUv1和v2有什么区别?
参考页面 NVIDA Tesla Helps Accelerate Deep Learning Inference
参考论文 https://arxiv.org/pdf/1704.04760.pdf
TPU Google搞的一类专用的深度学习加速器(全称Tensor Processing Unit,张量处理单元),可以较快完成深度学习中的计算任务(主要是各类矩阵乘法)。目前TPU出了2代。与此同时,NVIDIA和AMD等厂家也不甘落后,提出了众多对标产品,即他们的GPU。
大家最熟悉的是 CPU (central processing unit, 中央处理器),其计算通用性最广,但是对某些特殊的任务(特别是并行度极高的)性能不佳。随着游戏和多媒体的发展,NVIDIA等厂家推出了所谓 GPU(Graphics Processing Unit,图形处理单元),用于加速游戏渲染和视频解码等。
然后一些搞科学计算的人发现,GPU中的各种图形操作实质上是变相的矩阵运算,于是他们开始用GPU搞科学计算,并获得了巨大的加速。NVIDIA等率先意识到了这一点,提出了GPGPU(通用图形处理单元)的概念,使得GPU不止能够做图形学任务,还可以进行自定义的各类向量运算。现在大多数GPU在设计理念上都是GPGPU。
NVIDIA等运气真的很好,正好迎上了深度学习浪潮,深度学习中大部分运算都是张量/矩阵运算,刚巧可以被GPU加速。于是GPU成为了标准的深度学习加速器。
随着深度学习浪潮进一步提高,一些厂家开始想做所谓的深度学习ASIC(领域专用芯片),这类芯片不能做一般意义的科学计算,也不能渲染游戏,整个设计全部都为了跑深度学习应用,其中著名的一个就是Google的TPU。NVIDIA等也不甘心让步,在GPU内部嵌入了一些称为Tensor Core的ASIC元件,以进一步加强GPU在深度学习上的能力。
下面我们我们来评价一下这些硬件的性能。
评价硬件的性能,指标也是多样的。下面的图是对各种指标的性能评价,颜色代表厂家(蓝色Intel,绿色NVIDIA,黄色Google,红色AMD):


- 关于浮点运算。浮点运算速度是最直接的运算性能评价指标,以 Flops (Float operations per second) 为基本单位,图中的浮点运算单位都是 TFlops (也会就是 10^{12} Flops)。目前我国的神威-太湖之光超级计算机是浮点运算能力最强的超级计算机,峰值性能接近 100 PFlops(即 10^{17} Flops)。而家用计算机的CPU芯片性能一般以 GFlops 为单位。
- 关于浮点精度问题。浮点数的精度越高,硬件代价也越大,功耗也急剧上升,所以不按照精度来评价性能就是耍流氓。高精度的浮点运算总可以代替低精度的浮点运算,所以如果硬件没有低精度硬件的支持,可以用高精度运算代替,并且性能有可能会提升(在图中显示>号)。一般而言,科学计算(微分方程,大气模拟,分子动力学等)需要双精度单元,因此 TPU 等并不能进行科学计算;单精度主要用于图形学和精度不高的数值模拟,以及深度学习的训练;半精度和8bit往往用于深度学习的inference(即使用训练好的模型跑结果),它们数值精度很差训练会不稳定。可以说直接支持半精度和8bit的硬件大多都是给深度学习做了优化的。
- 关于是否支持训练的问题。支持深度学习训练的硬件往往比不支持的复杂一些。第一代TPU不支持训练,第二代支持,结果第二代的某些性能反而不如第一代,原因很大程度是因为需要支持训练增加的额外复杂性(比如流水线中要考虑更高精度的运算)。
- 关于是否含有深度学习ASIC的问题。深度学习ASIC是给深度学习量身定制的硬件模块,能够极大提升相关的性能。从图表中可以看到含有ASIC模块的硬件的8bit/半精度运算性能都很爆表,且功效比比其他硬件高很多。
- 内存带宽和HBM2问题。内存带宽影响着实际的运算性能(前面的浮点运算性能只是浮点运算的理论最高值,差不多就是把所有运算元件性能直接相加)。Google TPUv1相关的报告出来的时候业界普遍质疑其真实性能,最重要的一点是其内存带宽非常捉急,这是因为它使用了DDR3内存,也就是我们笔记本电脑和手机里面用的这种,性能相对很低下。而现在GPU大部分使用GDDR5内存,带宽普遍在DDR3的10倍以上;而现在异军突起的HBM2,正如其名字所称(High bandwidth memory version 2),性能普遍在 DDR3的20-30倍以上。所以当时核弹厂老黄直接喷TPUv1的实际性能只有P40的1/2。并且使用DDR3也使得其功耗偏低(个人笔记本不使用DDR4的一大原因也是功耗过高)。业界还有一种说法是,TPUv2运算性能大幅降低的一大原因是发现v1的运算性能根本发挥不出来,目前这点还未得到证实。
- 内存容量问题。内存容量越大,就可以跑越大的模型,越大的batch,否则就需要在多个卡上面跑,而内部运算开销会随着计算卡的数目上升而增大(一个极端的例子是超级计算机,如果处理不当其真实性能往往远低于所有硬件计算性能之和,所以超级计算机不能仅靠堆硬件)。所以内存容量也会间接影响性能,包括对于商家来说是价格比。
- 制程问题。制程体现了工艺水平,一般制程越高,性价比越好。TPUv1另一个显著的黑点在于其28nm的制程,要知道15年龙芯制程已经28nm了(当时Intel主流制程22nm,现在已经在冲刺10nm),也就意味着TPUv1的工艺水平还不如国产龙芯,这也是人们怀疑其实际性能的原因。
- 生态链。生态链决定了开发者的二次开发难度。最容易的显然是 Intel 的 CPU。NVIDIA的GPU也因为完整的CUDA库和OpenCL,生态链相对完善。AMD家主要是OpenCL环境,近来也开始支持CUDA。Google TPU目前还没有公开的驱动和文档,尚无市场意义的生态链。
- 价格问题。NVIDIA家的V100,P100等价格贵的离奇(没记错才发布的时候3000刀一个),如果不是因为超算比赛用到了这些产品,我可能都没有机会在上面跑程序。而Google TPU似乎目前还没有太多向外面卖的的意思,Google 可能更想那它做云服务。
这里需要注明的是,最新的 AlphaZero 训练的自战阶段使用了5000个TPUv1(因为只需要inference),参数更新部分使用了64个TPUv2,训练完成后在比赛中只需要4个TPUv1。