
时间序列数据的存储和计算 - 开源时序数据库解析(四)

Prometheus
开源时序数据库解析的系列文章在之前已经完成了几篇,对比分析了Hbase系的OpenTSDB、Cassandra系的KairosDB、BlueFlood及Heroic,最后是tsdb ranking top 1的InfluxDB。InfluxDB是从底到上纯自研的一款TSDB,在看他相关资料时对其比较感兴趣的是底层的TSM,一个基于LSM思想针对时序数据场景优化的存储引擎。InfluxDB分享了他们从最初使用LevelDB,到替换为BoltDB,最后到决定自研TSM的整个过程,深刻描述了每个阶段的痛点及过度到下个阶段需要解决的核心问题,以及最终TSM的核心设计思路。这类分享是我比较喜欢的,不是直接一上来告诉你什么技术是最好,而是一步一步告诉你整个技术演进的历程。这其中对每个阶段遇到的问题的深刻剖析、最终做出技术选择的理由等,让人印象深刻,能学到很多东西。
但InfluxDB的TSM,细节描述还是不够多,更多的是策略和行为的描述。最近看到了一篇文章《Writing a Time Series Database from Scratch》,从零开始写一个时序数据库,虽然有点标题党,但内容确是实打实的干货,描述了一个TSDB存储引擎的设计思路。而且这个存储引擎不是一个概念或玩具,而是真实应用到生产了,是Prometheus在2017年11月对外发布的2.0版里的一个完全重写的新的存储引擎。这个新版存储引擎号称是带来了『huge performance improvements』,由于变化太大,做不到向后兼容,估计也是真的带来了很多惊喜,才能这样子去耍流氓。
而本篇文章,主要是对那篇文章的一个解读,大部分内容来自原文,略有删减。想了解更详细的内容的话,建议可以去看英文原文,有理解错误的地方欢迎指正。
数据模型
Prometheus与其他主流时序数据库一样,在数据模型定义上,也会包含metric name、一个或多个labels(同tags)以及metric value。metric name加一组labels作为唯一标识,来定义time series,也就是时间线。在查询时,支持根据labels条件查找time series,支持简单的条件也支持复杂的条件。存储引擎的设计,会根据时序数据的特点,重点考虑数据存储(写多读少)、数据回收(retention)以及数据查询,Prometheus这里暂时还没提数据分析。
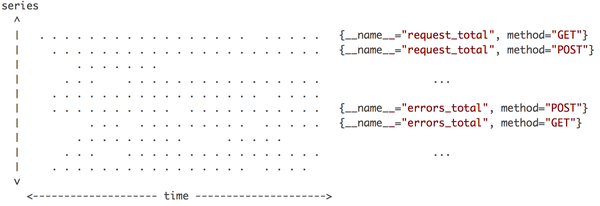

上图是所有数据点分布的一个简单视图,横轴是时间,纵轴是时间线,区域内每个点就是数据点。Prometheus每次接收数据,收到的是图中区域内纵向的一条线。这个表述很形象,因为在同一时刻,每条时间线只会产生一个数据点,但同时会有多条时间线产生数据,把这些数据点连在一起,就是一条竖线。这个特征很重要,影响数据写入和压缩的优化策略。
V2存储引擎
这篇文章主要阐述的是新的V3存储引擎的一些设计思想,老的存储引擎就是V2。V2存储引擎会把每条时间线上的数据点分别存储到不同的文件,这种设计策略下,文中提出了几个问题来探讨:
- 针对写入要做的优化:针对SSD和HDD的写入优化,均可遵循顺序写和批量写的原则。但是如上面所说,Prometheus一次性接收到的数据是一条竖线,包含很多的数据点,但是这些数据点属于不同的时间线。而当前的设计是一条时间线对应一个独立的文件,所以每次写入都会需要向很多不同的文件写入极少量的数据。针对这个问题,V2存储引擎的优化策略是Chunk写,针对单个时间线的写入必须是批量写,那就需要数据在时间线维度累积一定时间后才能凑到一定量的数据点。Chunk写策略带来的好处除了批量写外,还能优化热数据查询效率以及数据压缩率。V2存储引擎使用了和Facebook Gorilla一样的压缩算法,能够将16个字节的数据点压缩到平均1.37个字节,节省12倍内存和空间。Chunk写就要求数据一定要在服务器内存里积累一定的时间,即热数据基本都在内存中,查询效率很高。
- 针对查询要做的优化:时序数据的查询场景多遍,可以查某个时间线的某个时间点、某个时间点多条时间线或者是某个时间范围多条时间线的数据等等。在上面的数据模型图上示意出来,就是在二维象限内一个矩形的数据块。不断是针对SSD还是HDD,对磁盘数据读取比较友好的优化,均是优化到一次查询只需要少量的随机定位加上大块的顺序读取。这个和数据在磁盘的分布有很大的关系,归根到底,还是和数据写有关系,但不一定是实时写优化,也可以通过后续的数据整理来优化。
V2存储引擎里,有一些已经做的比较好的优化策略,主要是Chunk写以及热数据内存缓存,这两个优化延续到了V3。但是除了这两点,V2还是存在很多的缺陷:
- 文件数会随着时间线的数量同比增长,慢慢会耗尽inode。
- 即便使用了Chunk写优化,若一次写入涉及的时间线过多,IOPS要求还是会很高。
- 每个文件不可能会时刻保持open状态,一次查询可能需要重新打开大量文件,增大查询延迟。
- 数据回收需要从大量文件扫描和重写数据,耗时较长。
- 数据需要在内存中积累一定时间以Chunk写,V2会采用定时写Checkpoint的机制来尽量保证内存中数据不丢失。但通常记录Checkpoint的时间大于能承受的数据丢失的时间窗口,并且在节点恢复时从checkpoint restore数据的时间也会很长。
另外关于时间线的索引,V2存储引擎使用LevelDB来存储label到时间线的映射。当时间线到一定规模后,查询的效率会变得很低。在一般场景下,时间线的基数都是比较小的,因为应用环境很少变更,运行稳定的话时间线基数也会处于一个稳定的状态。但是若label设置不合理,例如采用一个动态值,比如是程序版本号作为label,每次应用升级label的值都会改变。那随着时间的推进,会存在越来越多无效的时间线(Prometheus称其为Series Churn)。时间线的规模会变得越来越大,影响索引查询效率。
V3存储引擎
V3引擎完全重新设计,来解决V2引擎中存在的这些问题。V3引擎可以看做是一个简单版、针对时序数据场景优化过后的LSM,可以带着LSM的设计思想来理解,先看一下V3引擎中数据的文件目录结构。


data目录下存放所有的数据,data目录的下一级目录是以'b-'为前缀,顺序自增的ID为后缀的目录,代表Block。每个Block下有chunks、index和meta.json,chunks目录下存放chunk的数据。这个chunk和V2的chunk是一个概念,唯一的不同是一个chunk内会包含很多的时间线,而不再只是一条。index是这个block下对chunk的索引,可以支持根据某个label快速定位到时间线以及数据所在的chunk。meta.json是一个简单的关于block数据和状态的一个描述文件。要理解V3引擎的设计思想,只需要搞明白几个问题:1. chunk文件的存储格式?2. index的存储格式,如何实现快速查找?3. 为何最后一个block没有chunk目录但有一个wal目录?
设计思想
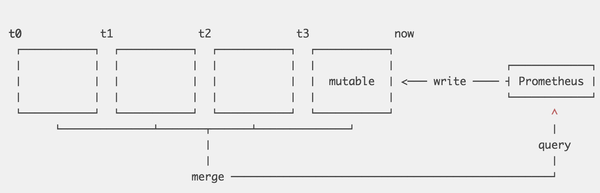

Prometheus将数据按时间维度切分为多个block,每个block被认为是独立的一个数据库,覆盖不同的时间范围的数据,完全没有交叉。每个Block下chunk内的数据dump到文件后即不可再修改,只有最近的一个block允许接收新数据。最新的block内数据写入会先写到一个内存的结构,为了保证数据不丢失,会先写一份WAL(write ahead log)。
V3完全借鉴了LSM的设计思想,针对时序数据特征做了一些优化,带来很多好处:
- 当查询一个时间范围的数据时,可快速排除无关的block。每个block有独立的index,能够有效解决V2内遇到的『无效时间线 Series Churn』的问题。
- 内存数据dump到chunk file,可高效采用大块数据顺序写,对SSD和HDD都很友好。
- 和V2一样,最近的数据在内存内,最近的数据也是最热的数据,在内存可支持最高效的查询。
- 老数据的回收变得非常简单和高效,只需要删除少量目录。
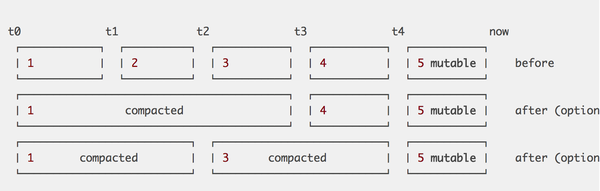

V3内block以两个小时的跨度来切割,这个时间跨度不能太大,也不能太小。太大的话若内存中要保留两个小时数据,则内存占用会比较大。太小的话会导致太多的block,查询时需要对更多的文件做查询。所以两个小时是一个综合考虑后决定的值,但是当查询大跨度时间范围时,仍不可避免需要跨多个文件,例如查询一周时间跨度需要84个文件。V3也是采用了LSM一样的compaction策略来做查询优化,把小的block合并为大的block,compaction期间也可做其他一些事,例如删除过期数据或重构chunk数据以支持更高效的查询。这篇文章中对V3的compaction描述的比较少,这个倒可以去看看InfluxDB怎么做的,InfluxDB有多种不同的compaction策略,在不同的时刻使用,具体可以看看这篇文章。
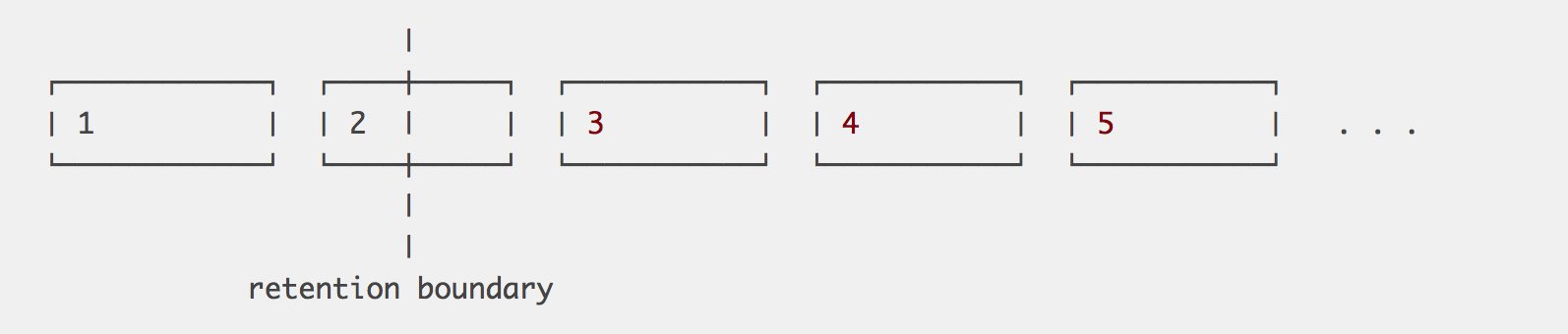

这个图是V3内对过期数据回收的一个示意图,相比V2会简单很多。对整个block已经过期的数据,直接删除文件夹即可。但对只有部分数据过期的block,无法进行回收,只能等全部过期或者compaction。这里有个问题要讨论,随着对历史数据不断的做compaction,block会变得越来越大,覆盖的时间范围会越大,则越难被回收。这里必须控制block的上限,通常是根据一个retention window的周期来配置。
以上基本讲完了数据存储的一些设计要点,还是比较简单明了的。和其他时序数据库一样,除了数据存储库,还有一份索引库。V3的索引结构比较简单,直接引用文章中给的例子:
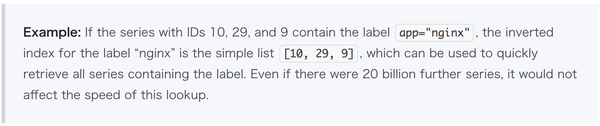



从文章描述看,V3没有和V2一样采用LevelDB,在已经持久化的Block,Index已经固定下来,不可修改。而对于最新的还在写数据的block,V3则会把所有的索引全部hold在内存,维护一个内存结构,等到这个block被关闭,再持久化到文件。这样做会比较简单一点,内存里维护时间线到ID的映射以及label到ID列表的映射,查询效率会很高。而且Prometheus对Label的基数会有一个假设:『a real-world dataset of ~4.4 million series with about 12 labels each has less than 5,000 unique labels』,这个全部保存在内存也是一个很小的量级,完全没有问题。InfluxDB采用的是类似的策略,而其他一些TSDB则直接使用ElasticSearch作为索引引擎。
Scale
Prometheus有两个比较著名的扩展版(感谢评论区内@蔡坤的指点),一个是cortex,另一个是thanos。
thanos在github的简介是『Highly available Prometheus setup with long term storage capabilities』,它基于Prometheus的最大改进是底层存储可扩展支持对象存储,例如AWS的S3,使得单机容量可扩展。这个得益于Prometheus 2.0中V3引擎的特性,持久化的Chunk文件是immutable的,所以能够很容易迁移到对象存储上。从它的设计文档里可以看出,它引入了一个Sidecar节点,与Prometheus server结对部署,主要作用将本地数据backup到远端的对象存储。当然数据被切割到本地和对象存储内后,为了支持统一的查询接口,又引入了Store层。Store层支持标准查询接口,屏蔽了底层是对象存储的细节,同时做了一些查询优化例如对Index的缓存。thanos中包含多个类型的节点,包括Prometheus Server、Sidecar、Store node、Rule node、compactor和query layer,其中只有query layer能水平扩展,因为其是无状态的。也就是说,单个实例的Prometheus其写入能力还是会有瓶颈,cotex相比它则在scalability上改进了更多。
cotex在github的简介是『A multitenant, horizontally scalable Prometheus as a Service』,几个关键词:多租户、水平扩展及服务化,架构设计可以看这篇文章。简单描述下它的架构设计中的几个要点:
- 实现多租户的方式主要是数据模型上引入一个新的维度『user id』,相当于多一个label。
- 分布式的数据写入层,一致性hash算法来管理节点。
- 为保证高可用,一份数据会写三份到不同的ingest replica。
- Chunk数据保存在AWS S3,Chunk的索引保存在AWS DynamoDB中,这两个都是服务化的分布式存储。DynamoDB中保存Chunk的倒排索引,表的Schema中HashKey为『userid, hour bucket, metric name』,而RangeKey为『label name, label value, chunk id』。
cotex在介绍其当前架构时,还顺带介绍了某些组件实现时考虑的替换方案。例如DynamoDB的索引可以拿ElasticSearch替换,但是他们不希望自己维护一个服务以及使用Java。数据Chunk存储到S3,这个也考虑过是否直接将数据点写入Cassandra或者DynamoDB,不使用Cassandra是不希望自己维护这个服务,而不使用DynamoDB是因为太贵。
总结
针对时序数据这种写多读少的场景,类LSM的存储引擎还是有不少优势的。有些TSDB直接基于开源的LSM引擎分布式数据库例如Hbase或Cassandra,也有自己基于LevelDB/RocksDB研发,或者再像InfluxDB和Prometheus一样纯自研,因为时序数据这一特定场景还是可以做更多的优化,例如索引、compaction策略等。Prometheus V3引擎的设计思想和InfluxDB真的很像,优化思路高度一致,后续在有新的需求的出现后,会有更多变化。
