
使用 Spark ML Pipeline 进行机器学习

Spark ML Pipeline 的引入,是受到 scikit-learn 的启发,虽然 MLlib 已经足够简单实用,但如果目标数据集结构复杂,需要多次处理,或是在学习过程中,要使用多个转化器 (Transformer) 和预测器 (Estimator),这种情况下使用 MLlib 将会让程序结构极其复杂。所以,一个可用于构建复杂机器学习工作流应用的新库已经出现了,它就是 Spark 1.2 版本之后引入的 ML Pipeline。ML Pipeline 是建立在 DataFrames 上的更高层次的 API 库,旨在帮助使用者来创建和调试实际的机器学习工作流。
Pipeline 组件
ML API 使用 Spark SQL 中的 DataFrame 作为机器学习数据集,可以容纳很多种类型的数据:文本、向量、图像和结构化数据等等。Spark DataFrame 以 RDD(Resilient Distributed Datasets) 为基础,但是带有 Schema(数据库中对象的集合)信息,类似于传统数据库中的二维表格。
中文可译作转换器,继承自 PipelineStage,它是一个算法,可以将一个 DataFrame 转换成另一个 DataFrame。如:
- 一个特征转换器对 DataFrame 的操作可能为,读取一个文本列,将其映射为一个新的特征向量列,然后输出一个带有特征向量的新的 DataFrame。
- 一个机器学习模型对 DataFrame 的操作可能为,读取一个带有特征向量的列,对每一个特征向量进行预测,然后输出一个带有预测数据的新的 DataFrame。
中文可译作预测器,它也是一个算法。预测器通过 fit() 方法,接收一个 DataFrame 并产出一个模型。例如,逻辑回归 (LogisticRegression) 算法就是一种预测器,通过调用 fit() 方法来训练得到一个逻辑回归模型。
⚠️ 注:Transformer.transform() 和 Estimator.fit() 都是无状态的。未来可能会被有状态的算法替代。每个转换器和预测器都有唯一 ID,这在调参过程中很有用。
Pipeline 连接多个转换器和预测器在一起,形成一个机器学习工作流。
在机器学习过程中,通过一系列的算法来处理和学习数据是很普遍的,例如,一个简单的文档处理工作流可能包括以下几步:
- 将每个文档分成单个词
- 将文档中的词转化成数字化的特征向量(关于这步可以参考我之前写过的文章:数据预处理之将类别数据数字化的方法 —— LabelEncoder VS OneHotEncoder)
- 基于特征向量和标签学习得到预测模型
MLlib 将上述一个工作流归为一个 Pipeline,包括一系列的 PipelineStage(多个 Transformer 和 Estimator),按特定的顺序执行。
所有的转换器和预测器使用同一个 API 来指定参数。 一个 Param 是被定义好的已命名参数。一个 ParamMap 是一组“参数-值” (parameter, value) 对。
向一个算法传参的方法主要有两种:
- 为实例设置参数。例如,lr 是 LogisticRegression 的一个实例,我们可以通过调用 lr.setMaxIter(10) 方法来设定 lr.fit() 最多进行10次迭代。这个 API 和 spark.mllib 包中的 API 相似。
- 通过 ParamMap 给 fit() 和 transform() 传参。ParamMap 中的参数将会覆盖之前通过 setter 方法设置过的参数。
如果我们有两个 LogisticRegression 实例 lr1 和 lr2,可以创建一个包含两个 maxIter 的 ParamMap:ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20)。如果一个 Pipeline 里有两个带有 maxIter 的算法,这种方法比较实用。
工作原理
Pipeline 由一系列 stage 组成,每个 stage 为一个转换器 (Transformer) 或预测器 (Estimator)。这些 stage 的执行是按一定顺序的,输入的 DataFrame 在通过每个 stage 时被改变。在转换器阶段,transform() 方法作用在 DataFrame 上。预测器阶段,调用 fit() 方法来产生一个转换器(成为 PipelneModel 的一部分),然后该转换器的 transform() 方法作用在 DataFrame 上。
我们通过一个简单的文档工作流来解释其工作原理,下图展示了训练过程中 Pipeline 的工作流程:


上图中,上面一行表示 Pipeline 的三个 stage。前两个 Tokenizer 和 HashingTF 是转换器,第三个 LogisticRegression 是一个预测器。下面一行表示通过 pipeline 的数据流,圆柱体代表 DataFrame。Pipeline.fit() 方法作用于原始 DataFrame,其中包含原始的文档和标签。Tokenizer.transform() 方法将原始文档分成单个词,将其作为新的列加入 DataFrame。HashingTF.transform() 方法将文本列转化成特征向量,将这些向量作为新的列加入 DataFrame。因为 LogisticRegression 是一个预测器,Pipeline 首先调用 LogisticRegression.fit() 来产生一个 LogisticRegressionModel。如果 Pipeline 还有其他的预测器,在将 DataFrame 传入下一个 stage 前,它将先调用 LogisticRegressionModel 的 transform() 方法。
整个 Pipeline 可以看作一个预测器。因此,在一个 Pipeline 的 fit() 方法执行完毕后,它会产生一个 PipelineModel,它是一个转换器。这个 PipelineModel 可在测试阶段调用,下图展示了具体的工作流程:
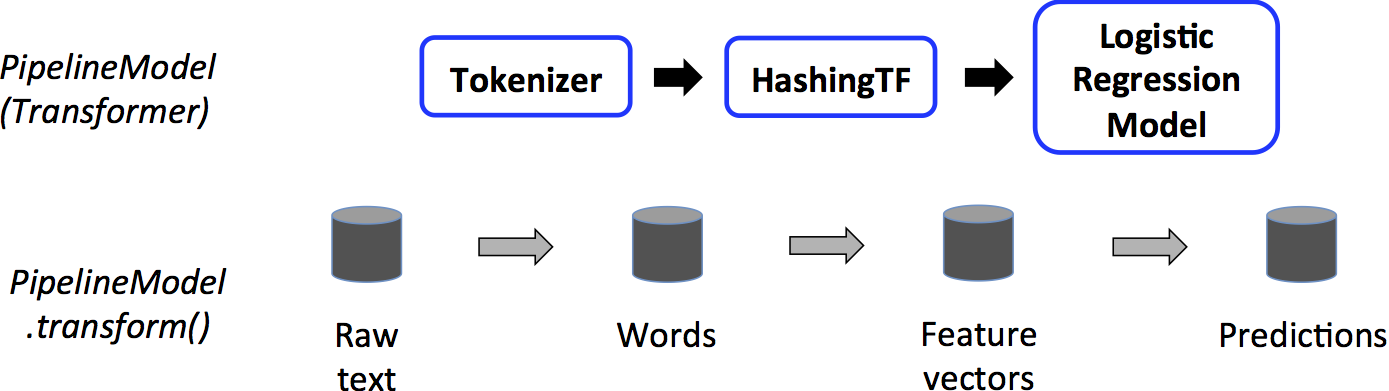

上图中,PipelineModel 和原始 Pipeline 有相同数量的 stage,但原始 Pipeline 中的预测器都变成了转换器。当 PipelineModel 的 transform() 方法被作用于测试数据集时,数据会按顺序穿过 pipeline 的各个阶段。每个 stage 的 transform() 方法都对数据集作了改变,然后再将其送至下一个 stage。
Pipeline 和 PipelineModel 有助于确保训练数据和测试数据的特征处理流程保持一致。
详细信息
DAG Pipeline: Pipeline 的 stage 是一个有序数组。这里引用的例子都是线性 Pipeline,其中的每个 stage 所用的数据都是由上一个 stage 产生的。但如果数据的流向为一个有向无环图 (DAG, Directed Acyclic Graph),那么 Pipeline 就可以是非线性的。这种图需要指定每个 stage 中输入和输出列的名字(通常通过参数来指定)。如果 Pipeline 的形式为 DAG,那么每个 stage 都必须为拓扑排序。
Runtime checking: 因为 Pipeline 可以运行在各种类型的 DataFrame 上,所以不能在编译时检查出错误类型。Pipeline 和 PipelineModel 会在 Pipeline 实际运行前进行检查。这种类型检查是基于 DataFrame schema 的,schema 包含了 DataFrame 中每一列数据的类型。
Unique Pipeline stages: Pipeline 的每一个 stage 都应该是唯一的实例。例如,同一个 myHashingTF 实例不应该进入 Pipeline 两次,因为 Pipeline stage 必须有唯一 ID。然而,不同的实例 myHashingTF1 和 myHashingTF2 可以进入同一个 Pipeline,因为两个实例是通过不同 ID 创建的。
存储和读取 Pipelines
通常情况下我们需要将一个模型或 pipeline 存储在磁盘上供以后使用。在 Spark 1.6 中,模型的导入和导出功能加入了 Pipeline 的 API,支持大多数转换器以及一些机器学习模型。具体还需参考算法的 API 文档来确认其是否支持存储和读取。
第一时间了解更多大数据相关内容,欢迎关注微信公众号【数据池塘】:

