深挖NUMA

首先列出开源小站之前相关的几篇帖子:
这次,就来深入了解下NUMA。
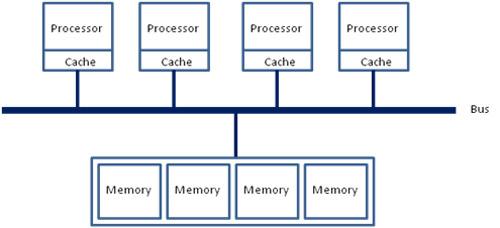
就如之前说的,在若干年前,对于x86架构的计算机,那时的内存控制器还没有整合进CPU,所有内存的访问都需要通过北桥芯片来完成。此时的内存访问如下图所示,被称为UMA(uniform memory access, 一致性内存访问 )。这样的访问对于软件层面来说非常容易实现:总线模型保证了所有的内存访问是一致的,不必考虑由不同内存地址之前的差异。

之后的x86平台经历了一场从“拼频率”到“拼核心数”的转变,越来越多的核心被尽可能地塞进了同一块芯片上,各个核心对于内存带宽的争抢访问成为了瓶颈;此时软件、OS方面对于SMP多核心CPU的支持也愈发成熟;再加上各种商业上的考量,x86平台也顺水推舟的搞了NUMA(Non-uniform memory access, 非一致性内存访问)。
在这种架构之下,每个Socket都会有一个独立的内存控制器IMC(integrated memory controllers, 集成内存控制器),分属于不同的socket之内的IMC之间通过QPI link通讯。
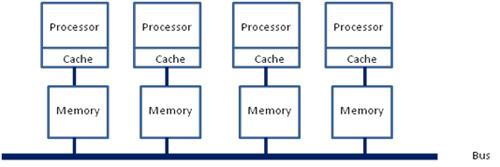
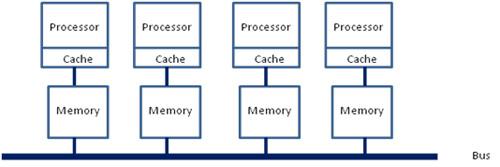
然后就是进一步的架构演进,由于每个socket上都会有多个core进行内存访问,这就会在每个core的内部出现一个类似最早SMP架构相似的内存访问总线,这个总线被称为IMC bus。
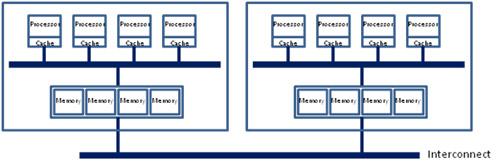

于是,很明显的,在这种架构之下,两个socket各自管理1/2的内存插槽,如果要访问不属于本socket的内存则必须通过QPI link。也就是说内存的访问出现了本地/远程(local/remote)的概念,内存的延时是会有显著的区别的。这也就是之前那篇文章中提到的为什么NUMA的设置能够明显的影响到JVM的性能。
回到当前世面上的CPU,工程上的实现其实更加复杂了。以Xeon 2699 v4系列CPU的标准来看,两个Socket之之间通过各自的一条9.6GT/s的QPI link互访。而每个Socket事实上有2个内存控制器。双通道的缘故,每个控制器又有两个内存通道(channel),每个通道最多支持3根内存条(DIMM)。理论上最大单socket支持76.8GB/s的内存带宽,而两个QPI link,每个QPI link有9.6GT/s的速率(~57.6GB/s)事实上QPI link已经出现瓶颈了。


嗯,事情变得好玩起来了。
核心数还是源源不断的增加,Skylake桌面版本的i7 EE已经有了18个core,下一代的Skylake Xeon妥妥的28个Core。为了塞进更多的core,原本核心之间类似环网的设计变成了复杂的路由。由于这种架构上的变化,导致内存的访问变得更加复杂。两个IMC也有了local/remote的区别,在保证兼容性的前提和性能导向的纠结中,系统允许用户进行更为灵活的内存访问架构划分。于是就有了“NUMA之上的NUMA”这种妖异的设定(SNC)。
回到Linux,内核mm/mmzone.c , include/linux/mmzone.h文件定义了NUMA的数据结构和操作方式。
Linux Kernel中NUMA的调度位于kernel/sched/core.c函数int sysctl_numa_balancing
- 在一个启用了NUMA支持的Linux中,Kernel不会将任务内存从一个NUMA node搬迁到另一个NUMA node。
- 一个进程一旦被启用,它所在的NUMA node就不会被迁移,为了尽可能的优化性能,在正常的调度之中,CPU的core也会尽可能的使用可以local访问的本地core,在进程的整个生命周期之中,NUMA node保持不变。
- 一旦当某个NUMA node的负载超出了另一个node一个阈值(默认25%),则认为需要在此node上减少负载,不同的NUMA结构和不同的负载状况,系统见给予一个延时任务的迁移——类似于漏杯算法。在这种情况下将会产生内存的remote访问。
- NUMA node之间有不同的拓扑结构,各个 node 之间的访问会有一个距离(node distances)的概念,如numactl -H命令的结果有这样的描述:node distances:
node 0 1 2 3
0: 10 11 21 21
1: 11 10 21 21
2: 21 21 10 11
3: 21 21 11 10
可以看出:0 node 到0 node之间距离为10,这肯定的最近的距离,不提。0-1之间的距离远小于2或3的距离。这种距离方便系统在较复杂的情况下选择最合适的NUMA设定。
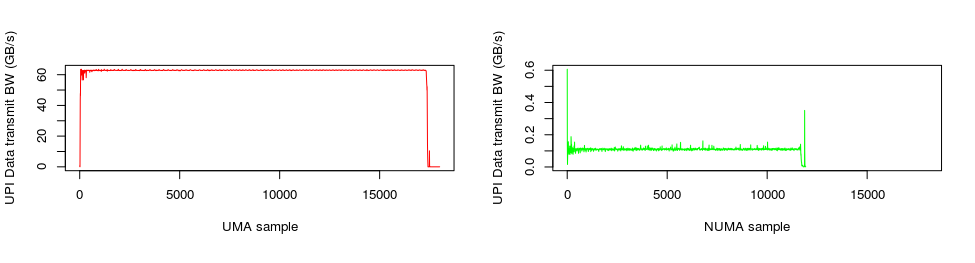

上图记录了某个Benchmark工具,在开启/关闭NUMA功能时QPI带宽消耗的情况。很明显的是,在开启了NUMA支持以后,QPI的带宽消耗有了两个数量级以上的下降,性能也有了显著的提升!
通常情况下,用户可以通过numactl来进行NUMA访问策略的手工配置,cgroup中cpuset.mems也可以达到指定NUMA node的作用。以numactl命令为例,它有如下策略:
- –interleave=nodes //允许进程在多个node之间交替访问
- –membind=nodes //将内存固定在某个node上,CPU则选择对应的core。
- –cpunodebind=nodes //与membind相反,将CPU固定在某(几)个core上,内存则限制在对应的NUMA node之上。
- –physcpubind=cpus //与cpunodebind类似,不同的是物理core。
- –localalloc //本地配置
- –preferred=node //按照推荐配置
对于某些大内存访问的应用,比如Mongodb,将NUMA的访问策略制定为interleave=all则意味着整个进程的内存是均匀分布在所有的node之上,进程可以以最快的方式访问本地内存。
讲到这里似乎已经差不多了,但事实上还没完。如果你一直按照这个“北桥去哪儿了?”的思路理下来的话,就有了另一个问题,那就是之前的北桥还有一个功能就是PCI/PCIe控制器,当然原来的南桥,现在的PCH一样也整合了PCIe控制器。事实上,在PCIe channel上也是有NUMA亲和性的。
比如:查看网卡enp0s20f0u5的NUMA,用到了netdev:<设备名称>这种方式。
[root@local ~]# numactl --prefer netdev:enp0s20f0u5 --show
policy: preferred
preferred node: 0
physcpubind: 0
cpubind: 0
nodebind: 0
membind: 0 1 2 3或者一个PCI address 为00:17的SATA控制器,用到了pci:<PCI address>
[root@local~]# numactl --prefer pci:00:17 --show
policy: preferred
preferred node: 0
physcpubind: 0
cpubind: 0
nodebind: 0
membind: 0 1 2 3还有block/ip/file的方式查看NUMA affinity,这里也就不再累述了。
综上,感觉上现在的服务器,特别是多socket的服务器架构更像是通过NUMA共享了内存;进而通过共享内存从而共享外设的多台主机。
最后还是那句:那种一个业务就能跑满整台server的时代是再也回不来了!
--原发布于2017/10/31 深挖NUMA - 开源小站
