玻尔兹曼分布,受限玻尔兹曼机


想写一点儿关于玻尔兹曼分布(一个统计力学的概念)是如何与受限玻尔兹曼机(一个机器学习模型)联系在一起的。其中涉及两者的一些推导。
玻尔兹曼分布
玻尔兹曼分布(Boltzmann distribution)描述在一定温度下,微观粒子运动速率的分布。其形式为
\pi(v) \propto \exp(-\frac{E}{k_B T})
其中 E = \frac{1}{2} m v^2 为粒子的动能, k_B 为玻尔兹曼常数。下面我们来推导这个分布。
考虑N个质量为m的粒子,第i个粒子的速度为 \bm{v}_i 。假设我们不考虑粒子间的势能,根据能量守恒,粒子群的总动能 E_N = \frac{1}{2} m \sum_{n=1}^{N}{||\bm{v}_n||^2} = \frac{1}{2} m \sum_{n=1}^{N}{\sum_{d=1}^{D}{v_{n, d}^2}} 守恒(D为维度数)。因此变量 v_{n, d} 分布在一个ND维的超球面上,其半径为 r = \sqrt{\frac{2 E_N}{m}} 。又根据等概率定律,这些变量在超球面上的分布是各向同性的(isotropic)。
如何在这个超球面上的均匀分布进行采样呢?我们先考虑在一个三维球面上的均匀分布进行采样的的问题。我们从高斯分布\pi(x) = \frac{1}{\sqrt{2 \pi} \sigma} \exp{(-\frac{x^2}{2 \sigma^2})} 中对三个变量x, y, z进行独立取样,它们的联合分布也是各向同性的:
\pi(x, y, z) dx dy dz = \pi(x) \pi(y) \pi(z) dx dy dz \\ \propto \exp(-\frac{x^2 + y^2 + z^2}{2}) dx dy dz = \exp(-\frac{r^2}{2}) r^2 dr d\Omega
所以,我们只需对采样结果 (x, y, z) 进行模归一化,得到的样本即是在三位球面上均匀分布的。显然,这个方法可以推广到N维。
到现在为止,我们知道了如何对每个粒子在每个维度上的速度分量进行采样,使得系统的总动能为定值。但这还并不能告诉我们这些变量是服从高斯分布的,因为独立采样后我们还要进行归一化。幸运的是,我们可以证明,当变量数N足够大时,未经归一化的样本的半径会收敛到一个固定值 r = \sqrt{N} \sigma 。所以,对于单一粒子的任一维度(WLOG我们设为x), v_x \sim \mathcal{N}(0, \sigma = \sqrt{\frac{2 E_N}{m D N}}) 。其中 \frac{E_N}{D N} = \frac{1}{2} k_B T 为粒子在单一维度上的平均动能,因此也可以写作 \sigma = \sqrt{\frac{k_B T}{m}} 。这就是粒子在单一维度上的速度分布,也即麦克斯韦分布:
\pi(v_x) = \sqrt{\frac{m}{2 \pi k_B T}} \exp(-\frac{1}{2} \frac{m v_x^2}{k_B T})
通过这个分布可以得出粒子的速率分布。在二维空间中,\pi(v) = \frac{m}{k_B T} v \exp(-\frac{1}{2} \frac{m v^2}{k_B T})
而在三维空间中, \pi(v) = \sqrt{\frac{2}{\pi}} (\frac{m}{k_B T})^{\frac{3}{2}} v^2 \exp(-\frac{1}{2} \frac{m v^2}{k_B T}) ,或者简单理解为 \pi(v) \propto \exp(-\frac{1}{2} \frac{E}{k_B T}) ,其中E为粒子的动能。这便是玻尔兹曼分布。
受限玻尔兹曼机
下面我们来介绍受限玻尔兹曼机。一般的玻尔兹曼机(Boltzmann Machine)是一个马尔可夫随机场(MRF),它将变量节点分为隐藏节点和可见节点两种。但是在一般的玻尔兹曼机中,精确推断(exact inference)的复杂度很高,就连吉布斯采样推断也会变得很慢。而受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)在此基础上增加了一个条件:同类节点之间没有连接,所以它退化为一个二分图。在这个图中,每个隐藏节点和和每个可见节点之间有连接。稍后我们还会给每个连接赋一个权重。我们把这个图的两层分别记作隐藏层(H)和可见层(V)。
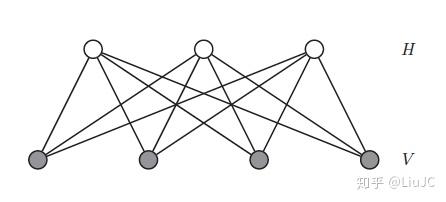

RBM定义隐藏层和可见层的联合分布为
p(\bm{v}, \bm{h} | \bm{\theta}) = \frac{1}{Z} \exp(-E(\bm{v}, \bm{h}; \bm{\theta}))
其中E为能量函数,Z为归一化因子。RBM之所以沿用了玻尔兹曼的名字,正是因为它定义了系统状态的能量,并将玻尔兹曼分布用作采样函数。
乍一看RBM很像一个两层的全连接前馈神经网络(FFN)。但是我们将看到,在RBM中,连接权重是可以在两个方向上使用的,而在FFN中连接权重只在forward时有意义。另一个重要的区别是,因为RBM的连接是无向的,所以在给定可见层变量的条件下,隐藏层变量是相互独立的(conditionally independent),因此后验分布可以分解成
p(\bm{h} | \bm{v}, \bm{\theta}) = \prod_k{p(h_k | \bm{v}, \bm{\theta})}
这方便了我们在给定可见层时对隐藏层进行采样。如果我们将隐藏层作为输入,可见层作为输出,那么就能从标签反推输入数据。相比较而言,FFN中的连接是有向的。在给定输入层变量时,输出层变量是相互独立的,也正是有赖于此我们才能在神经网络中进行并行计算。但是,在给定输出层变量时,输入层变量不是相互独立的(回忆Markov blanket的定义),所以也就不能反过来对输入层进行高效采样。
考虑一个隐藏变量和可见变量均为binary的RBM,其能量函数
E(\bm{v}, \bm{h}; \bm{\theta}) = -\bm{v}^T \bm{W} \bm{h} = \sum_{r}{\sum_{k}{v_r W_{rk} h_k}}
注意,我们已经把bias项纳入到W中了。我们在推导其后验分布时还能顺手推出我们为什么用sigmoid函数作为二分类的激活函数:
p(h_k | \bm{v}, \bm{\theta}) = \frac{1}{Z} \exp(\bm{v}^T \bm{W}_{:, k} h_k) \\ \frac{p(h_k = 0 | \bm{v}, \bm{\theta})}{p(h_k = 1 | \bm{v}, \bm{\theta})} = \frac{1}{\exp(\bm{v}^T \bm{W}_{:, k})} \\ p(h_k = 0 | \bm{v}, \bm{\theta}) = \frac{1}{1 + \exp(\bm{v}^T \bm{W}_{:, k})} = \text{sigm}(\bm{v}^T \bm{W}_{:, k})
根据对称性,我们有后验分布
p(\bm{h} | \bm{v}, \bm{\theta}) = \prod_{k}{p(h_k | \bm{v}, \bm{\theta})} = \prod_{k}{\text{Ber}(h_k | \text{sigm}(\bm{w}_{:, k}^T \bm{v}))} \\ p(\bm{v} | \bm{h}, \bm{\theta}) = \prod_{r}{p(v_r | \bm{h}, \bm{\theta})} = \prod_{r}{\text{Ber}(v_r | \text{sigm}(\bm{w}_{r, :}^T \bm{h}))}
(有一个想法,既然sigmoid是softmax在二分类时的退化,那如果我们把RBM中的隐藏变量设为Categorical的,那是不是也能推导出softmax呢?感觉上是可以的,有时间准备推一下。)
应用方面,RBM可以用于document retrieval和collaborative filtering,也可以叠起来成为深度玻尔兹曼机(DBM)。在最近几年并没有进入深度学习的主要流派。
参考资料
Machine Learning: A Probabilistic Perspective, Chapter 27, by Kevin P. Murphy
Statistical Mechanics: Algorithms and Computations, Lecture 4, by Werner Krauth