TVM学习(二):算符融合

算符融合将多个计算单元揉进一个计算核中进行,减少了中间数据的搬移,节省了计算时间。TVM中将计算算符分成四种:
1 injective。一一映射函数,比如加法,点乘等。
2 reduction。输入到输出具有降维性质的,比如sum。
3 complex-out。这是计算比较复杂的,比如卷积运算等。
4 opaque。无法被融合的算符,比如sort。
根据以上对算符的不同类型,TVM提供了三种融合规则:
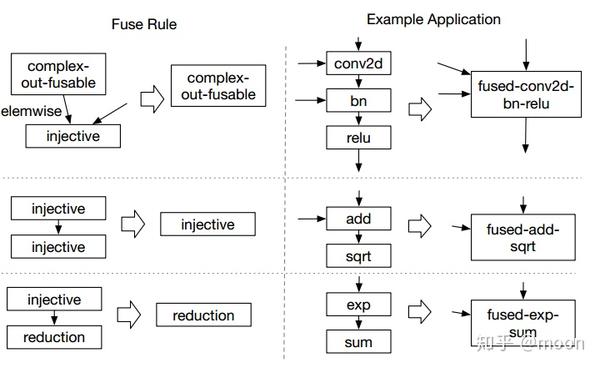

从一定角度看,这种融合实际上是数据计算pipeline化,即两次计算中间数据不再经历store-load的过程,而是直接给到下一个计算单元完成计算。
在走入fuse ops代码之前,还需要了解一些算法基础知识。算符融合中应用了支配树算法。在一个有向无环图中,对于一个节点n来说,从初始节点s出发到达n的所有路径都经历一个节点m,那么m就是n的支配点。而距离n最近的支配点被称作立即支配点。以r为树根,将所有立即支配点按照支配关系连接起来就形成了支配树。立即后支配点是从一个点n出发所有到终止节点的路径中通过的最近节点,形成的支配树是后支配树。
在DAG中,对于一个点,所有能到达它的点在支配树中的LCA,就是它支配树中的父亲。为什么算符融合要建立在后支配树的基础上呢?我猜测可能是因为对于两个可融合算符在DAG中位置分为两种,一种是父子关系,那么可以直接执行算符融合算法;另外一种是它们之间是后支配关系。对于具有后支配关系的两个节点(n->m),就要判断未来路径上的节点是否都能够和点m发生融合,如果可以,那么n也可以和m发生融合。比如下图:
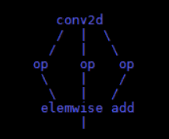
Conv2d要和elemwise add融合,必须判断它的三个op是否能和elemwise add融合。
TVM中融合流程分为三步:
1 遍历relay树,建立DAG用于后支配树分析;
2 建立后支配树;
3 应用算符融合算法。
一 建立DAG图
算符融合代码在src/relay/transforms/http://fuse_ops.cc中。其中算符融合也应用在常量折叠中。
首先TVM中通过如下代码来遍历relay树结构并建立DAG图。


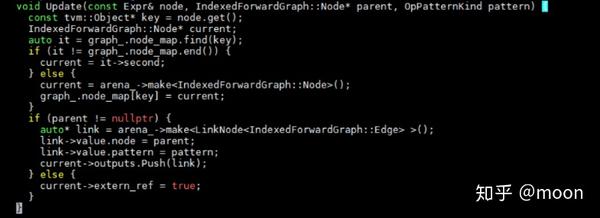

VisitExpr可以递归的调用在类IndexedforwardGraph中定义的VisitExpr_函数,通过深度优先搜索遍历relay树,并且建立DAG图。深度优先搜索是从exit节点作为根节点反向搜锁的,因此搜索树是一个后序搜索树。Outputs中保存了一个节点的输入的边,在构建后序支配树会通过这些输入边求取LCA。那么在这个搜索树基础上应用支配树算法,就能够得到一个后序支配树了。在这个类中针对不同节点类型重写visitExpr_函数,节点类型有FunctionNode,ConstantNode, CallNode, TuppleNode等。我们来看CallNode的访问函数定义:
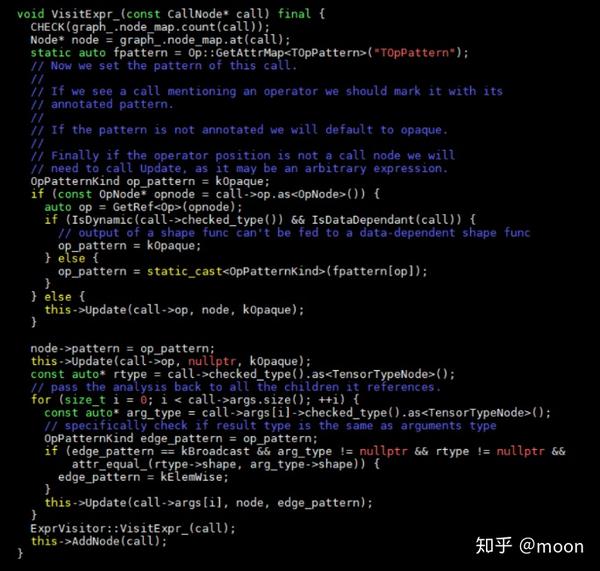

在最后还会递归调用ExprVisitor::VisitExpr_函数,最终将深度优先搜索到的节点按照叶节点起始顺序一次加入DAG图中。只有ConstantNode的访问函数中不再调用VisitExpr_,因为常量节点应该不存在叶节点了。在callNode中会将其输入加入到DAG中,同时遍历和输入以及其op连接的节点,ExprVisitor中对CallNode访问函数定义为:
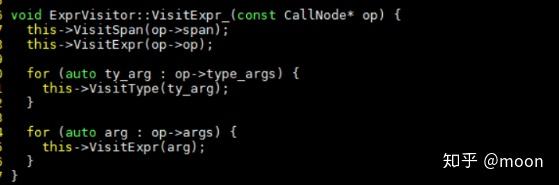

因为ExprVisitor是被IndexForwardGraph继承的,而VisitExpr_是虚拟函数,this就会指向IndexForwardGraph实例,最终就会调用这个类中定义的VisitExpr_函数,实现递归的遍历relay树。
这里要关注一下OpPatternKind,它定义了算子类型,是不同融合算法使用的依据。其定义在include/tvm/relay/op_attr_types.h文件中。
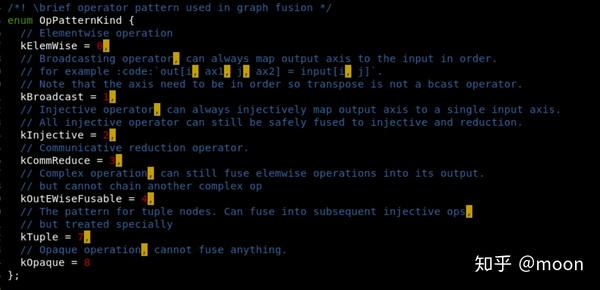

二 建立后序支配树
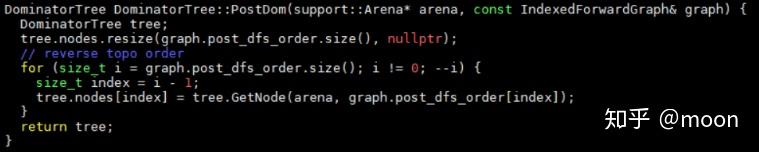
接下来看后序支配树的构建。构建函数是PostDom。因为根节点(DAG图的出口)在post_dfs_order中最后,所以从根节点开始寻找每个节点出点的LCA,这个LCA就是后序支配点。

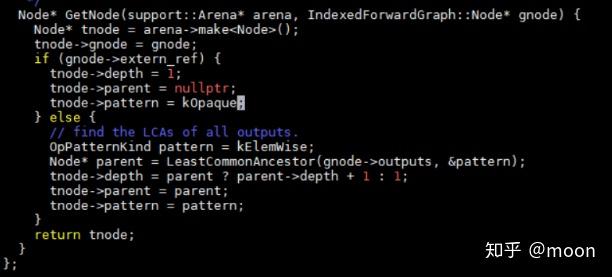
GetNode函数是获得支配点,构建支配树。在GetNode中,首先初始化根节点,然后求每个节点的输入节点的LCA,即是这个节点的支配点。

LeastComonAncestor函数中主要代码是:


通过两两求节点的LCA,来求取所有节点的LCA。程序会将计算图中的末节点深度设置为1。然后向上逐层增加,那么LCA的共同祖先是相同的,深度也一定是一致。遍历所有的节点,就得到一个后向支配树。节点的pattern指向他的LCA。在计算支配点的pattern的时候,会依据pattern的定义,选择pattern值最大的作为LCA的pattern。这块不是太深入理解。可能是其定义的从最小值到最大值pattern可以向下进行融合,比如kElemWise=0, kInjective=2, 那么前者就能融合到KInjective中。
三 融合
完成了DAG和postDominator tree构建后,就开始融合操作。TVM中定义了group结构体,用于表示融合后的图结构。Group结构体如下:
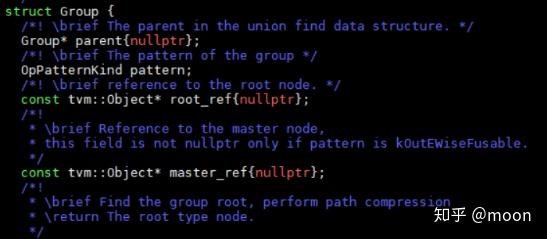

如果某些算符可以融合,那么就通过这个结构体中的parent,master_ref将这些节点建立连接关系。Group首先进行初始化和DAG相同的图。然后分别遍历dag,postDominator tree,以及group图中节点,来判断算符是否能被融合。Dag中和postDom中对应相同index的节点分别是被支配点和支配点。主要融合函数是以下两个函数:
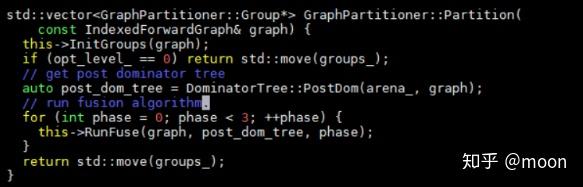

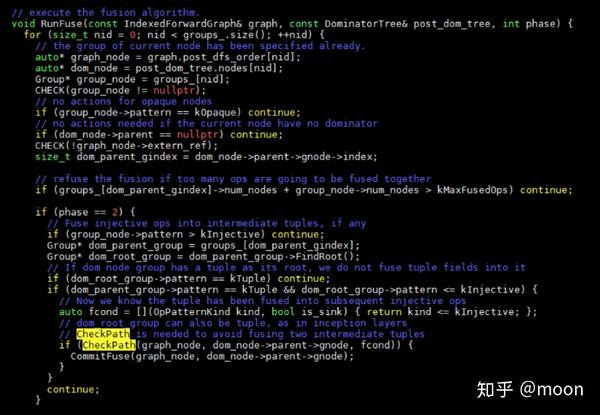

在runFuse中,有几种情况是不进行算符融合的:
1 算符类型是Kopaque的。
2 该节点不存在支配点。
3 能够融合的节点超过了一定数量。
融合操作算法基本上是考察当前节点到其支配点所有路径上的节点是否都符合融合规则,如果符合就进行融合,不符合就不融合。函数CheckPath就是用于考察src到sink路径是否能够融合的。
融合分成了三个phase,每个phase处理不同可融合类型。这里我没有深入研究。当判断支配树的前后节点可以融合后,就通过函数commitFuse执行融合操作。
完成融合之后,会遍历节点创建新的graph。
往期文章
1 TVM学习(一)
2 tensorflow中的控制流和优化器
3 TVM编译器


