
RNN基本模型汇总(deeplearning.ai)

祝大家新年快乐! 大吉大利,今晚吃鸡!
此篇是根据ng的deeplearning.ai的序列模型做的笔记,主要是为了总结一下RNN的基本的序列模型。还望大神勿喷。看完这篇文章,对于TextRNN,RCNN,Hierarchical Attention Network等模型结构就更好理解了,这些结构无非就是基本RNN结构的拼接,转换。
RNN基本模型
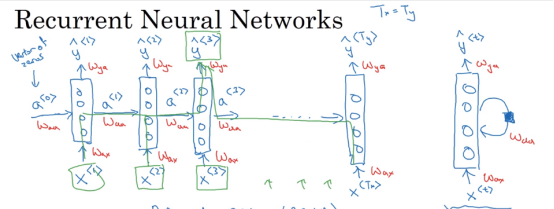
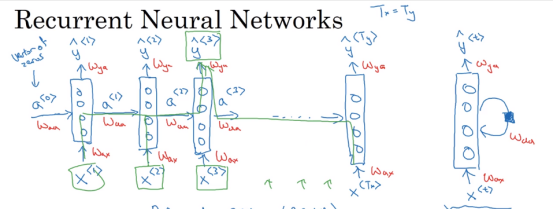
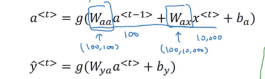
我认为RNN模型有以下三个特点:
- 时序性,递归性 y_{t} = f(y_{t-1},x_{t}) ,一般输入来自两个方面,一个是之前状态 y_{t-1} ,和当前状态的输入 x_{t} 。
- 参数共享,每一步的参数矩阵都是共享的,主要的参数矩阵也是上述的两个方面, W_{aa} 和 W_{ax} 。
- cell的设计,为了解决rnn更新时指数式的梯度弥散,梯度爆炸的问题和控制cell保留信息比例的问题,设计了gru,lstm cell,具体见后面。
反向传播过程
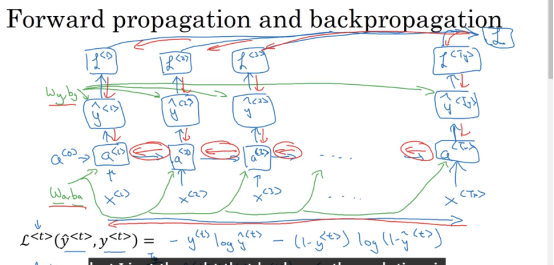

从图中可以看出,参数的更新方式也是基于时间步的,从loss function开始求导,最终都汇总的输入刚开始的时间步开始更新,由于每一步的参数都是共享的,更新了最初的时间步的参数,也就更新了所有的参数。这是RNN和其他网络结构不同的地方。
GRU

GRU cell有两个gate:
- update gate:
控制当前输入 \tilde{c}^{<t>} 和之前cell c^{<t-1>} 之间平衡关系,取值在0~1之间。
- reset gate:
控制当前输入 \tilde{c}^{<t>} 中有多少来自之前的输出,取值在0~1之间。
在GRU模型中输出 a^{<t>} 与cell中保存的信息 c^{<t>} 是一样的。
LSTM
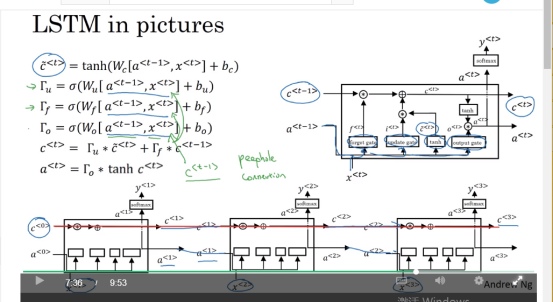

LSTM相较于GRU多了一个gate,即forget gate,将GRU中的update gate分成input gate和forget gate。且输出信息通过output gate去控制,相当于GRU中的reset gate。
- input gate (图中 \Gamma_{u} ) : 控制当前输入所占比例
- forget gate (图中 \Gamma_{f} ): 控制之前cell所占比例
- output gate(图中 \Gamma_{o} ) : 控制输出所占比例
通过gate的设计我们可以根据不同的任务学得不一样的参数,以控制当前信息和之前cell中的信息保留的比例,去更好的完成时序任务,同时也能防止梯度的弥散和爆炸(gradident clip 可以解决这个问题)。
双向RNN
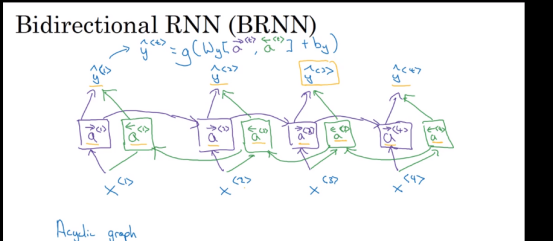

双向RNN意味着对于一条语句我们可以正着输入一遍,反过来输入一遍,这样对于每一个sate我们既可以考虑到前面的信息也可以考虑到后面的信息,然后concat二者的output 接一个线性权重即可得到输出。
deep RNN
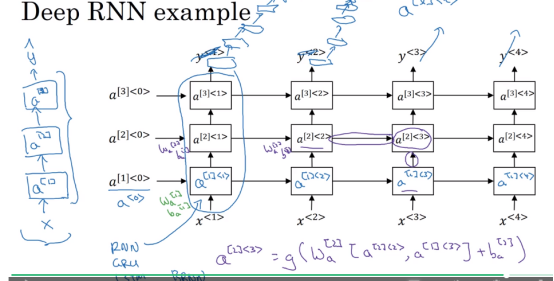

Deep RNN用多层的cell去提取特征,相当于cnn里面设置的多个卷积核。这样提取特征的效果会更好。
关于attention机制,word2vec等年后有时间再写吧,祝大家狗年大吉,旺旺旺~

