ovs vxlan 时延和吞吐

设计云时到底要不要用vxlan,如果用vxlan到底要不要购买比较贵的smart nic做offload,采用软件vxlan还是硬件交换机vxlan,很难决策,这儿简单测试一下,给个参考,资源终究是有限的,成本还是有考虑的,了解清楚云上业务再做决策。
把网络比作一条水管,虹吸原理把水从一个池塘A抽到另一个池塘B,当然是水管越粗越好,水管粗细就是不同能力的网卡,一秒钟能从水管流出多少水就是吞吐,假如从水管入口滴一滴墨水,那墨水从入口到出口的时间就是单向时延,水管壁粗糙弯曲不直,水流就慢,时延就大,水在水管里流得越快单位时间从水管口流出来的水就越多,时延影响吞吐。水流速度主要取决于池塘A和池塘B的水位差,假如一个人甲向池塘A加水,另一个人乙从池塘B取水,甲乙动作快慢影响水位差,池塘大小就是buffer,池塘越大,甲乙动作对水位差影响越小,而水位差类似于链路层反压和TCP流量控制,甲乙就是TCP和系统调用。而真实的网络情况是很多水管很多池塘串连,水管有粗有细,池塘有大有小,很多甲乙,有胖有瘦有老有幼,瓶颈到底在哪里很难说清楚。
测试环境
物理机物理口的MTU是1500,vxlan0,ovs internal口和虚拟机的网口MTU都是1450,host物理口打开多队列,虚拟机8核16G,vhost=on,网口无多队列。
最普通的环境,不做其它特殊优化,就看最通用的环境表现是怎样的。
两台物理机不同路径对打流量。


红色的是physical流量测试路径,两个物理机直接流量测试。
ip link add vxlan0 type vxlan id 1111 dstport 5799 remote 10.145.69.49 local 10.145.69.26 dev eth4
ip link set vxlan0 up
ip addr add dev vxlan0 192.168.111.1/24
ip link add vxlan0 type vxlan id 1111 dstport 5799 remote 10.145.69.26 local 10.145.69.49 dev eth4
ip link set vxlan0 up
ip addr add dev vxlan0 192.168.111.2/24蓝色的是kernel vxlan流量测试路径,做上面的命令创建vxlan device,做vxlan encap/decap。
红色的是namespace vxlan流量测试路径,借用了neutron创建的namespace,br-int上连接的是internal类型的口,也做vxlan encpa/decap。
两个物理机上的两台虚拟机对打流量。
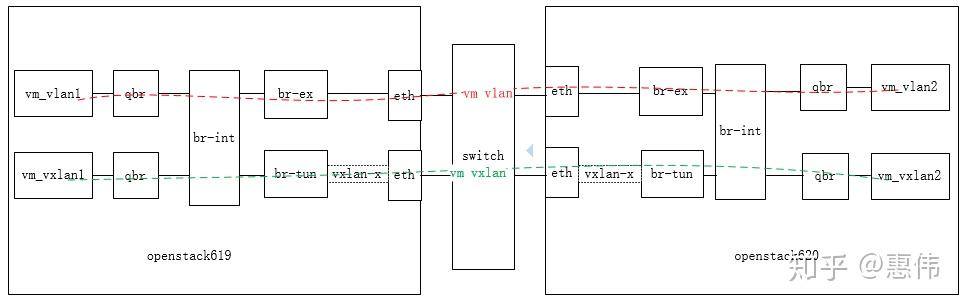

红色的是vm vlan流量测试路径,流量不做vxlan encap/decap。
绿色的是vm vxlan流量测试路径,流量做vxlan encap/decap。
5种测试都要经过host或者guest kernel tcp/ip stack,区别就是有没有kvm介入,有没有vxlan encap/decap。
测试方法
没有硬件测试仪,用一些小软件模拟业务真实场景测试。
#用ping测试时延
ip netns exec qdhcp-5cc14009-86bb-4610-91a7-ae7627e8a5b5 ping 192.168.200.2 -c 100
#背景pps高 ,再用ping测试时延
iperf3 -c 192.168.200.2 -p 8099 -t 180 -l 1 -u
#背景bps高,再用用ping测试时延
iperf3 -c 192.168.200.2 -p 8099 -t 180
#netperf测试TCP时延
netperf -H 192.168.111.2 -p 8077 -t TCP_RR -- -o mean_latency
#netperf测试UDP时延
netperf -H 192.168.111.2 -p 8077 -t UDP_RR -- -o mean_latency
数据
ping和iperf3测试结果,时延单位是ms。
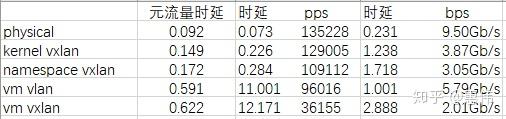

netperf测试时延结果,时延单位是us。

测试时延工具用的是ping和netperf,ping和netperf用默认发包频率,ping是一秒一个包,netperf是连续发包,ping和netperf的值比较没意义。
分析
- 物理口支持各种offload和多队列所以性能最高时延最小。
- 没流量时namespace vxlan时延是physical的2倍,而vm vxlan是physical的7倍,vm vxlan相比于namespace vxlan多了qbr桥和kvm处理时间,说明相比vxlan处理,qbr和kvm耗费的时间更多。
- 背景pps大时 namespace vxlan时延是physical的4倍并且pps只是physical的80%,而vm vxlan时延是物理的17倍并且pps只是physical的26%,pps大时流量对kvm冲击更大,性能瓶颈突显,在看pps大时vm vlan的表现,时延是physical的15.6倍并且pps只是physical的70%,时延同样表现不佳,再比较vm vxlan以及vm vlan和namespace vxlan和kernel vxlan,更说明pps大时时延是由于kvm处理处理不及时导致的。pps大时观察到发送端vhost线程cpu 100%,接收端一个qemu-kvm线程cpu 100%,多队列,分散处理irq能提高处理性能减小部分时延。
- 小报文pps大时配置ethtool -N eth4 rx-flow-hash udp4 sdfn后ping时延没有改善,相比于vxlan处理引入的时延,更应当关注kvm对中断处理以及vcpu调度引入的时延,目前现状应该优先优化kvm。
- bps大时报文长度大pps相对小点,pps小vxlan encap/decap少kvm处理也少,vm vxlan bps只是namespace vxlan bps的66%,按道理说它的时延也应该是namespace vxlan的66%即1.145才对,结果确是2.888,说明kvm处理把时延翻倍了。
- bps大时vm vxlan相比vm vlan时延大是真正vxlan封装的问题,长报文大量占用vxlan device的budget,观察到一个ksoftirqd占用cpu 100%,配置网卡rss用udp源和目的port后,ethtool -N eth4 rx-flow-hash udp4 sdfn,ping时延才0.368,因为ping包hash到不同的物理cpu,ping包处理插队了,说明此时cpu处理vxlan存在性能瓶颈,性能影响了时延。
- 大报文bps大时,因为有MTU限制,pps其实也不小,ovs vxlan处理和kvm处理会引入相等的时延,但这个时延只是大pps时kvm引入时延的10%,一条流处理有上限,不同流占用不同的物理cpu能提高vxlan性能减小vxlan处理时延。
- vm vxlan相比于vm vlan,pps和bps都上不去,性能上存在较大瓶颈。
- netperf TCP和UDP测试发的都是小包,TCP和UDP封装的长度都是1字节,pps高,测试时发现qemu进程和vhost线程cpu占用率很高,说明性能瓶颈在于kvm,physical, kernel vxlan和namespace vxlan相比时延成20%增长,但加上kvm后,时延翻了二三倍,如果硬要知道vxlan encap/decap引入的时延比一下vm vxlan和vm vlan就知道了,大概10%左右,但kvm引入200%左右。
结论
- 时延瓶颈点在于kvm,kvm引入的时延远远大于vxlan encap/decap。
- ovs实现vxlan性能存在瓶颈,单cpu的ksoftirq很容易就100%了,吞吐上不去。
- 一旦用smart nic offload或者硬件交换机做vxlan处理后,vxlan对物理cpu占用基本没了,vxlan性能会大幅提高,单流kvm就更承受不住,时延会更大,性能瓶颈会转移到kvm,但多条流分散到不同的虚拟机会有部分收益,但肯定不会成线性的,linux进程调度和kvm处理中断很快就会成瓶颈。
