Faiss PQ 实现

所谓PQ 即 Product Quantizer, 相对与普通的Quantizer而言
普通Quantizer 将整个向量通过单次聚类达到量化
而Product Quantizer 则通过对向量分段,每段分别聚类得到多个量化结果(每段一个量化结果),这样的好处是同较小的码本来表达非常大量的码
比如8段,每段256个码,总共256*8 个码本就可以表达256的8次方个码
而普通Quantizer要表达256的8次方个码,码本同样需要这么大
数据结构
struct ProductQuantizer {
size_t d; ///< size of the input vectors
size_t M; ///< number of subquantizers
size_t nbits; ///< number of bits per quantization index
// values derived from the above
size_t dsub; ///< dimensionality of each subvector
size_t byte_per_idx; ///< nb bytes per code component (1 or 2)
size_t code_size; ///< byte per indexed vector
size_t ksub; ///< number of centroids for each subquantizer
bool verbose; ///< verbose during training?
/// initialization
enum train_type_t {
Train_default,
Train_hot_start, ///< the centroids are already initialized
Train_shared, ///< share dictionary accross PQ segments
Train_hypercube, ///< intialize centroids with nbits-D hypercube
Train_hypercube_pca, ///< intialize centroids with nbits-D hypercube
};
train_type_t train_type;
ClusteringParameters cp; ///< parameters used during clustering
/// Centroid table, size M * ksub * dsub
std::vector<float> centroids;
.......
ProductQuantizer(size_t d, /* dimensionality of the input vectors */
size_t M, /* number of subquantizers */
size_t nbits);
.........重点关注
d: 向量维数
M:量化器的段数
nbits: 每个分段向量编码占用的bit数,如果为8,那么就有256个码
dsub:分段向量的维数
byteperidx:每段向量编码占用的字节数
code_size:向量编码占用的字节数
ksub: 每个子量化器的聚类中心点个数
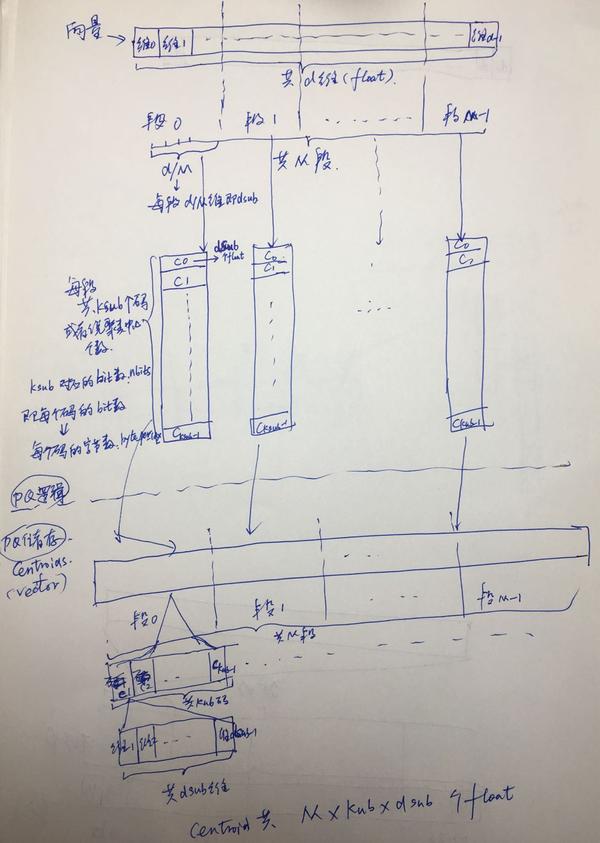
centroids: 所有的聚类中心点,总共 M * ksub * dsub个float
初始化
ProductQuantizer::ProductQuantizer (size_t d, size_t M, size_t nbits):
d(d), M(M), nbits(nbits)
{
set_derived_values ();
}3个核心的属性是
d: 输入向量的维度
M:向量的分段数
nbits: 每个分段向量编码占用的bit数,如果为8,那么就有256个码
void ProductQuantizer::set_derived_values () {
// quite a few derived values
FAISS_THROW_IF_NOT (d % M == 0);
dsub = d / M;
byte_per_idx = (nbits + 7) / 8;
code_size = byte_per_idx * M;
ksub = 1 << nbits;
centroids.resize (d * ksub);
verbose = false;
train_type = Train_default;
}其他的属性可以由上面的3个属性来推导
dsub = d / M 每个段的维数可以通过向量维数和向量的段数相除得到
byte_per_idx = (nbits + 7) / 8 通过编码位数来推算需要占用的字节数,不满8就补齐1个字节,如果能被8整除就是nbits/8 否则就是nbits/8+1
code_size 一个向量的编码占用的字节数, 即每段占用的字节数*段数
ksub = 1 << nbits 就是 2^nbits 比如8位,那么ksub 即每段的聚类中心点有256个
centroids:存放所有的聚类中心点(M段*每个段kub个聚类中心点),每个聚类中心点是dsub个float

训练
1) 输入
pq.train (n, trainset);n: 训练向量的个数
trainset: 训练向量数组
2)开始遍历所有段
c++
for (int m = 0; m < M; m++)
3) 准备好每个段下的所有分段向量
float * xslice = new float[n * dsub];
.......
for (int j = 0; j < n; j++)
memcpy (xslice + j * dsub, x + j * d + m * dsub, dsub * sizeof(float));4) 初始化聚类
Clustering clus (dsub, ksub, cp);此时的聚类针对每个分段向量的,所以向量的位数为分段向量的位数:dsub, 该段下的聚类中心点个数为前面提到的ksub
聚类初始化的细节可见 文档 Faiss聚类实现
5) 训练聚类
IndexFlatL2 index (dsub);
clus.train (n, xslice, index);聚类训练的细节可见 文档 Faiss聚类实现
6) 存储聚类结果
set_params (clus.centroids.data(), m);set_params 实现如下
void ProductQuantizer::set_params (const float * centroids_, int m)
{
memcpy (get_centroids(m, 0), centroids_,
ksub * dsub * sizeof (centroids_[0]));
}将聚类结果放入数据结构中提到centroids 中的相应的位置
