机器学习代价函数中的正则项与最大后验概率估计

本文目录
1 最大后验概率估计(maximum posterior probability,MAP)
2 最大似然估计与最大后验估计的区别
3 最大后验估计与正则之间的关系
4 MLE和MAP之间的另一个重要的关联
本文正文
1 最大后验估计
本文主要讲解最大似然估计和最大后验估计之间关系,以及正则与最大后验估计之间的联系。
在前面我们已经讨论过什么叫最大似然估计以及如何应用在逻辑回归当中。
用极大似然估计构建优化问题(代价函数)的逻辑:
假设D=(x_i, y_i)(i=1,2,..., m)是服从某分布的随机变量产生的样本数据,\theta是该随机变量对应的概率分布函数的参数。该随机变量对应的概率分布函数就是机器学习中预设的假设函数(Hypothesis),最大似然估计就是求使得如下概率最大化的概率分布函数的参数\theta。
P(D)=P(D|\theta)=\prod_{i=1}^mP(y_i|x_i,\theta)
最大似然估计是构建模型的目标函数过程中最常用的一种方法。
另外,我们在建模过程中可能也会想:如何把已知的经验放到模型里面去?
- 问题:最大似然估计是否能够把人的经验(先验经验)也考虑进去?
- 不可以。最大似然本身是不可能把先验知识考虑进去的。
那如何才能做到把先验知识考虑进去呢? 答案就是使用最大后验估计(maximum posterior probability,MAP)!
那什么又是最大后验估计呢? 为了更好地理解它的含义,最好的方法是直接跟最大似然估计做个对比。
对于最大似然估计,我们需要最大化的是P(D|\theta), 然而在最大后验估计里,我们需要最大化的是P(\theta|D),这也叫做后验概率。 所以也把它叫作最大后验估计。
由于P(\theta|D)不好直接计算,可以用贝叶斯公式,把P(\theta|D)转化为P(\theta|D)=\frac{P(D|\theta)P(\theta)}{P(D)}。
所以,直观来看我们只是把模型的参数和观测值的顺序改了一下。看似比较小的改动,却带来完全不一样的模型。


2 最大似然估计与最大后验估计的区别
接下来,从数据的角度来了解一下它俩之间的区别是什么。


所以,总体来讲MAP要比MLE多出了一个项,就是P(\theta),也叫作先验概率,而且这个概率是我们可以指定的。MAP适用于样本比较少的情况。
例如,一个诊所一天来了20个病人检测癌症,其中有1个确诊。按照最大似然估计算出来来该诊所检测的人中得癌症的概率为1/20。如果,知道普通人得癌症的概率P(\theta)=0.01\%,用最大后验概率估计计算出来的结果就会比1/20小很多。
这就是MAP的奥妙之处,可以通过先验的方式来给模型灌输一些信息。 比如模型的参数\theta可能服从高斯分布,我们就可以假定先验就是高斯分布。
3 最大后验估计与正则之间的关系
接下来,我们来理清楚MAP与正则之间的关系。假如考虑逻辑回归,那在最大后验估计下应该如何表示它的目标函数呢?
由于之前讨论过逻辑回归,所以我们都知道如何通过最大似然来表示逻辑回归的目标函数(如下图所示)。


接着,我们试着把基于最大似然的逻辑回归改造成基于最大后验估计的逻辑回归,但提前需要定义好参数的先验。我们假定参数\thetaθ服从均值为0的高斯分布。那具体的MAP形式会是怎么样呢?


- 结论:在极大似然估计的基础上加了高斯的先验,这等同于我们在已有的代价函数上加了L2正则。
这个结论并不是偶然的,而且这就是先验以及正则之间的关系。
加入高斯的先验相当于加入了L2的正则。
那如果换成其他类型的先验又会是怎样呢?
下面,我们来看另一种情况:把先验设置为服从拉普拉斯分布,会发生什么情况?


在这个情况下我们得到的是加入L1正则之后的目标函数。根据L1正则的性质,我们知道它会带来稀疏解,所以很多都会变成0。
简答来个总结:


除了这两种情况,我们也可以假定参数服从其他类型的分布,这时候得出来的正则项肯定也是不一样的。
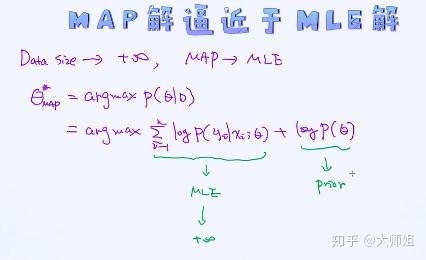
4 MLE和MAP之间的另一个重要的关联
下面的一句话也适合用来描述MLE和MAP之间的另一个重要的关联。


一个极端的情况是:当数据量无穷多的时候,MAP的结果会逼近于MLE的结果。这又如何去理解呢?如下图所示,当样本个数趋近于无穷大时,第一项的结果也趋近于无穷大,第二项的常数基本就不起作用了。

具体相关的知识点,也可以参考这篇文章:https://zhuanlan.zhihu.com/p/72370235
