中文实体识别最新SOTA算法Lex-Bert算法效果复现

综述
上一篇NER的刚刚复现了中文实体识别SOTA模型Flat-Lattice Transformer效果复现及原理分析,这不又一篇文章,在arxiv上放了出来:LEX-BERT: ENHANCING BERT BASED NER WITH LEXICONS 号称叒超越了FLat-NER成为了新的中文NER的SOTA,笔者本着求真的精神,对其Lex-Bert-V2代码进行实现,但是由于论文中没有说明具体使用的是什么实体类型词表,因此只能根据真实场景7类实体的训练集中的实体类型词表进行构建(包含人名、地名、机构名、时间、日期......),最终结果显示相比于BERT略有提升,但是相比于Bert直接附加词信息的方式是比不过的,因此,大胆推断Lex-Bert算法并不是一个通用算法,需要一个极好的外部实体类型词表。表1显示出复现的效果,我们发现6层上面,该算法都不是最优。另外我觉得Lex-Bert-V2方案有比较大的理论漏洞,这在最后讨论中进行详述。
表1. 中文7类NER效果
| 模型 | 精确率% | 召回率% | F值% |
| BERT 6层 | 68.32 | 70.00 | 69.15 |
| BERT 6层 + 词位置信息 | 69.40 | 70.06 | 69.73 |
| Lex-Bert-V2(6层) | 69.47 | 69.41 | 69.44 |
| Lex-Bert-V2(6层) attention全部位置 | 64.26 | 62.99 | 63.62 |
| BERT_wwm 6层 + 词位置信息 + 词性信息 | 67.85 | 67.66 | 67.75 |
备注:
(1)上述模型中BERT模型为哈工大的Bert_wwm,预测时直接过一个全连接到标签数目在softmax到标签概率即可。
(2)词位置信息是先对句子进行结巴分词,单字词作为0,多字词开始位置1,中间位置2,结束位置3,然后编码
到50维向量与bert输出的字符向量拼接后进行预测的方法。
(3)词性信息是结巴分词之后给实体打上词性标签(采用了40个词性标签)去编码到50维向量与词信息向量与
bert输出的字符向量拼接后进行预测的方法。这种方案是我受论文启发,采用结巴的词表进行分词并得到词性信息
将词信息也作为一维特征拼接上去,期望能提升效果,结果事与愿违。
(4)复现Lex2Bert实体识别算法。使用训练集中的实体作为实体类型词表,训练集中包含7类实体。
验证集实体数量 4600,训练集实体数量 26601,训练集包含验证集的实体: 1131,百分比:0.24586 1.Lex-BERT创新点
(1)可以引入实体类型type信息,作者认为在领域内,可以收集包含类型信息的词汇,与此同时实际上相当于也引入了实体的位置,在上篇文章中讲过引入单纯引入词位置就能使模型效果更优。
(2)相比于FLAT,没有外部的embeding和额外的Transformer+CRF,更轻快,实现起来也更简单。
2. 模型具体结构
论文作者共给出了2个版本的Lex-BERT,如图1所示:
Lex-BERT V1: 将type信息的标识符嵌入到词汇前后,[v][/v] [d][/d]代表的是具体的实体类型。
Lex-BERT V2: 将type信息的标识符拼接input后,然后与原始word起始的token共享相同的position embedding。这个实现起来很简单,针对每个句子加入一维输入张量input_pos,它的值如图1(b)所示,然后查找位置编码对应的向量生成一个768的向量附加到对应字符向量上即可。


Lex-BERT V2 在attention层中使用一个attetion_mask,文本token只去attend文本token、不去attend标识符token,而标识符token可以attend原文token。图2展示了这个attention_mask矩阵的形状。具体实现时可以在构建input_ids时针对每一个字符构建seqLen长的0/1序列,其中能看见的字符位置为1,看不见的为0,序列不足的位置padding也补0就行。最后对于batch个句子我们的attetion_mask是一个batchSize x seqLen x seqLen的矩阵,在输入Bert model的时候去把原来那个input_mask给替换掉就行了。


3.论文效果
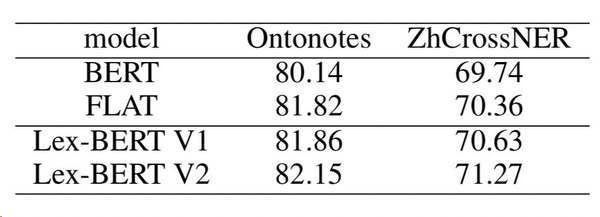

备注: 用的什么实体类型词表未明确,因此有很大疑点......
4.讨论
(1)引入实体类型信息这种先验信息及实体出现的位置信息,这种思路我觉得没问题。但是实现方式有待商榷。
(2)Lex-Bert-V2这种方案,存在比较大的理论漏洞,在验证集上,很多实体在实体词典中是不存在的,因此无法提前知晓所有候选句子中的实体及类型信息(可能包含一部分),所以在预测时,我认为仍采用的是前面token序列的标签结果,但是文中说句子的token不去attention实体标志符,这就导致就算有部分实体类型的标志符通过实体类型词典找到,由于不做attention,这个信息根本就没有被使用。我在真实场景复现时, Lex-Bert-V2这种方案就是使用的是token位置的标签,当然其效果略微提升了0.3个点,但这种方案和原始Bert没有什么本质区别。有一篇文章说过这个问题Fine-Tuning Pretrained Language Models_ Weight Initializations Data Orders and Early Stopping,就是采用预训练模型进行微调时,随机种子影响不小,因此两种模式原理相同结果也可能相差零点几个百分点。但是反过来如果Lex-Bert-V2直接使用后面附加的实体类型标签位置的结果进行真实标签预测的话,在我们的场景下由于验证集中实体只有约25%出现在类型词典中,那么最多会有25%的实体召回率,效果不言而喻。但是作者论文中又说效果很好,那只能是验证集里面的实体在实体类型词表中几乎都得出现,也就是实体类型词表包含训练集+验证集+测试集上的实体,这显然跟真实场景的使用情况不符。